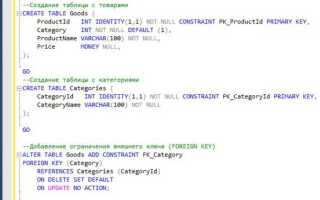
Для создания новой таблицы в SQL используется команда CREATE TABLE. Этот запрос позволяет задать структуру таблицы, включая наименования столбцов, типы данных для каждого столбца и ограничения, такие как PRIMARY KEY, NOT NULL, и UNIQUE.
Основная форма запроса выглядит следующим образом:
CREATE TABLE имя_таблицы (
столбец1 тип_данных [ограничения],
столбец2 тип_данных [ограничения],
…
);
При указании типа данных важно учитывать, какой вид информации будет храниться в каждом столбце. Например, для хранения целых чисел используется тип INT, для строк – VARCHAR или TEXT, а для дат – DATE.
Не забывайте об ограничениях. Например, PRIMARY KEY гарантирует уникальность значений в столбце, а NOT NULL предотвращает создание записей без значения в определённом столбце. Правильное использование ограничений обеспечивает целостность данных и позволяет эффективно управлять таблицей.
Выбор базы данных для создания таблицы
При создании таблицы в SQL необходимо учитывать тип базы данных, в которой она будет размещена. Разные системы управления базами данных (СУБД) могут иметь свои особенности, влияющие на структуру и работу таблиц. Для эффективного выбора важно ориентироваться на несколько факторов.
1. Совместимость с типом данных
Каждая СУБД имеет свои особенности в поддержке типов данных. Например, MySQL и PostgreSQL имеют схожие типы данных, но в некоторых случаях их синтаксис отличается. Важно заранее определить, какие данные будут храниться в таблице, и проверить поддержку нужных типов данных в выбранной СУБД.
2. Масштабируемость
Если проект предполагает большую нагрузку или рост объема данных, стоит выбрать СУБД с хорошей поддержкой масштабируемости. Например, PostgreSQL и MariaDB обладают сильными средствами для работы с большими объемами данных и сложными запросами.
3. Поддержка индексов и производительность
Разные СУБД предлагают различные методы создания индексов, что может существенно повлиять на скорость выполнения запросов. Например, в PostgreSQL индексы создаются с использованием B-деревьев, а в MySQL – с помощью различных типов индексов, таких как HASH и BTREE. Выбор базы данных должен учитывать тип запросов, который будет чаще всего выполняться.
4. Совместимость с транзакциями
Если работа с данными требует строгой транзакционной целостности, стоит обратить внимание на поддержку ACID-транзакций в СУБД. PostgreSQL и Oracle предоставляют наиболее высокую степень согласованности данных. В то время как MySQL в стандартной конфигурации использует менее строгую изоляцию транзакций в некоторых случаях.
5. Лицензирование и стоимость
Выбор между бесплатными и коммерческими СУБД может зависеть от бюджета проекта. Например, MySQL и PostgreSQL бесплатны и с открытым исходным кодом, а для Oracle и MS SQL Server могут потребоваться лицензионные отчисления. Если в проекте важна гибкость без дополнительных затрат, открытые СУБД являются хорошим выбором.
6. Поддержка репликации и резервного копирования
Если проект требует высокодоступной базы данных, стоит учитывать механизмы репликации и восстановления данных. В PostgreSQL и MySQL репликация осуществляется с помощью мастера-слейва, в то время как в Oracle доступны более сложные схемы репликации и восстановления.
Решение о выборе СУБД должно опираться на тип данных, требования к производительности, возможности масштабирования и особенности использования в проекте. Каждая СУБД имеет свои преимущества, и правильный выбор поможет избежать множества проблем в процессе работы с таблицами.
Определение структуры таблицы: типы данных для столбцов
Выбор типа данных для столбцов в таблице имеет решающее значение для производительности и корректности работы базы данных. Каждый тип данных оптимизирован для хранения определённых значений, и неправильный выбор может привести к излишнему потреблению памяти или проблемам с обработкой запросов.
Основные типы данных в SQL включают:
Числовые типы:
— INT – целое число. Используется для хранения значений в диапазоне от -2,147,483,648 до 2,147,483,647.
— DECIMAL и NUMERIC – фиксированная точность. Подходит для хранения денежных сумм или других значений, где важно точное представление.
— FLOAT, REAL – числа с плавающей запятой. Применяются для хранения значений с небольшой погрешностью, таких как научные вычисления.
Текстовые типы:
— VARCHAR – строка переменной длины. Рекомендуется для хранения текстов переменной длины. Например, для имени или адреса.
— CHAR – строка фиксированной длины. Используется, если длина строки всегда одинаковая, например, для хранения кодов или фиксированных идентификаторов.
— TEXT – для больших текстов, например, для комментариев, описаний.
Дата и время:
— DATE – хранение только даты. Идеально подходит для событий, где время не имеет значения.
— TIME – хранение только времени, используется для записи времени суток.
— DATETIME и TIMESTAMP – для хранения как даты, так и времени. Для временных меток и отслеживания изменений данных.
Логические типы:
— BOOLEAN – хранит значения «истина» или «ложь». Обычно используется для флагов или состояний.
При проектировании структуры таблицы важно учитывать, как типы данных будут влиять на производительность. Например, использование VARCHAR вместо CHAR может существенно снизить потребление памяти, если длина строк переменная. Также стоит обращать внимание на размер данных – типы данных, такие как TEXT или DECIMAL, могут занимать значительно больше места на диске по сравнению с INT или DATE.
Некоторые СУБД предоставляют дополнительные типы данных, например, BLOB для хранения бинарных данных (изображений, файлов) или UUID для уникальных идентификаторов. Важно учитывать, что выбор типа данных должен быть адаптирован под конкретные нужды проекта и способствовать оптимизации запросов и операций с базой данных.
Использование ключевых слов CREATE TABLE и их синтаксис
Команда CREATE TABLE позволяет создать новую таблицу в базе данных. Основной синтаксис включает в себя указание имени таблицы и определение её столбцов, а также их типов данных. Формат команды следующий:
CREATE TABLE имя_таблицы (
имя_столбца_1 тип_данных_1,
имя_столбца_2 тип_данных_2,
...
);
Типы данных могут варьироваться в зависимости от системы управления базами данных (СУБД). Наиболее распространенные типы: INT, VARCHAR, DATE, FLOAT. Также могут быть использованы ограничения, такие как NOT NULL, UNIQUE, PRIMARY KEY, которые накладывают ограничения на столбцы, обеспечивая целостность данных.
Пример создания таблицы:
CREATE TABLE сотрудники (
id INT PRIMARY KEY,
имя VARCHAR(100) NOT NULL,
дата_рождения DATE,
зарплата FLOAT);
В данном примере столбец id является уникальным идентификатором записи и имеет ограничение PRIMARY KEY, что обеспечивает уникальность значений в этом столбце. Столбец имя не может содержать пустых значений благодаря NOT NULL.
Если необходимо добавить дополнительные характеристики для столбцов, например, установить значения по умолчанию, можно использовать DEFAULT. Например, если для столбца зарплата нужно задать значение по умолчанию:
CREATE TABLE сотрудники (
id INT PRIMARY KEY,
имя VARCHAR(100) NOT NULL,
зарплата FLOAT DEFAULT 50000);
Здесь столбец зарплата будет автоматически иметь значение 50000, если при вставке данных не указано другое значение.
Обратите внимание, что в разных СУБД могут быть нюансы в синтаксисе, например, в MySQL и PostgreSQL существуют различные ограничения на длину строк в типе VARCHAR, а в SQL Server может быть использован тип данных NVARCHAR для поддержки Unicode.
Как задать первичный ключ для таблицы
Первичный ключ (PRIMARY KEY) в SQL уникально идентифицирует каждую запись в таблице. Для его задания используется ключевое слово PRIMARY KEY при создании таблицы или добавлении столбца.
Есть два способа задать первичный ключ: на этапе создания таблицы или после её создания. Рассмотрим оба варианта.
1. Задание первичного ключа при создании таблицы
Для задания первичного ключа при создании таблицы указывается столбец, который будет выступать в роли ключа. Обычно это столбец с уникальными значениями, например, ID.
CREATE TABLE users ( id INT NOT NULL, name VARCHAR(100), email VARCHAR(100), PRIMARY KEY (id) );
Здесь столбец id является первичным ключом. Он уникален для каждой строки и не может содержать NULL.
2. Задание первичного ключа для нескольких столбцов
Иногда требуется использовать комбинацию столбцов в качестве первичного ключа. В таком случае нужно указать все столбцы, которые будут составлять ключ, в одном определении PRIMARY KEY.
CREATE TABLE orders ( order_id INT NOT NULL, product_id INT NOT NULL, quantity INT, PRIMARY KEY (order_id, product_id) );
Здесь комбинация столбцов order_id и product_id уникально идентифицирует каждую строку в таблице.
3. Добавление первичного ключа к уже существующей таблице
Если таблица уже существует, можно добавить первичный ключ с помощью команды ALTER TABLE:
ALTER TABLE users ADD PRIMARY KEY (id);
Важно, чтобы столбец, на который накладывается первичный ключ, не содержал повторяющихся значений и NULL.
4. Ограничения при использовании первичного ключа
- Столбец, определённый как первичный ключ, не может содержать NULL.
- Каждое значение в столбце первичного ключа должно быть уникальным.
- Таблица может иметь только один первичный ключ.
Если попытаться вставить дублирующееся значение или NULL в столбец первичного ключа, SQL вернёт ошибку.
5. Особенности при использовании автоинкремента
Если первичный ключ является автоинкрементируемым, например, для идентификаторов записей, можно использовать команду AUTO_INCREMENT (MySQL) или SERIAL (PostgreSQL). Это позволяет автоматически генерировать уникальные значения для первичного ключа при вставке новых строк.
CREATE TABLE users ( id INT AUTO_INCREMENT, name VARCHAR(100), PRIMARY KEY (id) );
Здесь значению столбца id будет автоматически присваиваться уникальное число при добавлении новой строки.
Добавление ограничений (constraints) для столбцов
Ограничения (constraints) в SQL используются для обеспечения целостности данных. Они позволяют задать правила, которые столбцы таблицы должны соблюдать. Эти правила включают проверки на уникальность значений, допустимость пустых значений, ссылки на другие таблицы и другие условия. Ограничения могут быть определены как при создании таблицы, так и при её изменении. Рассмотрим основные типы ограничений, которые можно применить к столбцам.
NOT NULL ограничение заставляет столбец содержать только ненулевые значения. Оно предотвращает вставку строк с пустыми значениями в столбец.
Пример:
CREATE TABLE employees ( id INT NOT NULL, name VARCHAR(100) NOT NULL );
UNIQUE ограничение обеспечивает уникальность значений в столбце, то есть повторяющиеся значения будут отклонены.
Пример:
CREATE TABLE employees ( id INT PRIMARY KEY, email VARCHAR(100) UNIQUE );
PRIMARY KEY ограничение объединяет два свойства: уникальность значений и запрет на NULL. Этот ключ используется для идентификации каждой строки в таблице.
Пример:
CREATE TABLE employees ( id INT PRIMARY KEY, name VARCHAR(100) );
FOREIGN KEY ограничение связывает столбец с другим столбцом в другой таблице. Это важно для поддержания целостности данных и предотвращения удаления или обновления данных, на которые могут ссылаться другие строки.
Пример:
CREATE TABLE orders ( order_id INT PRIMARY KEY, customer_id INT, FOREIGN KEY (customer_id) REFERENCES customers(id) );
CHECK ограничение позволяет задать условия для значений столбца. Оно применяется, когда необходимо проверить, что данные соответствуют определённому формату или диапазону.
Пример:
CREATE TABLE employees ( id INT PRIMARY KEY, salary DECIMAL(10, 2), CHECK (salary > 0) );
DEFAULT ограничение задаёт значение по умолчанию для столбца, если при вставке строки не указано явное значение для этого столбца.
Пример:
CREATE TABLE employees ( id INT PRIMARY KEY, hire_date DATE DEFAULT CURRENT_DATE );
Ограничения можно добавлять и изменять после создания таблицы с помощью команды ALTER TABLE. Например, чтобы добавить ограничение UNIQUE к столбцу:
Пример:
ALTER TABLE employees ADD CONSTRAINT unique_email UNIQUE (email);
Каждое ограничение выполняет важную роль в поддержании целостности данных, и их использование в проектировании базы данных позволяет избежать ошибок и обеспечить корректность информации в таблицах.
Создание таблицы с внешними ключами
Для создания таблицы с внешними ключами в SQL необходимо указать столбец, который будет ссылаться на другой столбец в другой таблице. Это позволяет установить связи между данными, обеспечивая целостность данных.
Внешний ключ используется для обеспечения ссылочной целостности между двумя таблицами. Он ограничивает значения столбца таким образом, чтобы они соответствовали значениям первичного ключа в другой таблице.
Пример создания таблицы с внешним ключом:
CREATE TABLE Orders ( OrderID INT PRIMARY KEY, CustomerID INT, OrderDate DATE, FOREIGN KEY (CustomerID) REFERENCES Customers(CustomerID) );
В этом примере столбец CustomerID в таблице Orders ссылается на столбец CustomerID в таблице Customers. Это означает, что значения в Orders.CustomerID должны совпадать с существующими значениями в Customers.CustomerID.
Важно учитывать, что тип данных внешнего ключа должен совпадать с типом данных первичного ключа, на который он ссылается. Если типы не совпадают, SQL выдаст ошибку.
Для определения действий, которые будут предприняты при изменении или удалении данных в таблице, с которой связан внешний ключ, можно использовать дополнительные параметры. Например:
CREATE TABLE Orders ( OrderID INT PRIMARY KEY, CustomerID INT, OrderDate DATE, FOREIGN KEY (CustomerID) REFERENCES Customers(CustomerID) ON DELETE CASCADE ON UPDATE RESTRICT );
В данном примере ON DELETE CASCADE гарантирует, что при удалении записи из таблицы Customers будут удалены все связанные заказы, а ON UPDATE RESTRICT блокирует изменение значений CustomerID в таблице Customers, если на эти значения ссылаются записи в Orders.
При проектировании таблиц с внешними ключами важно учитывать, как изменения в одной таблице могут повлиять на связанные данные в других таблицах. Правильное использование внешних ключей помогает поддерживать целостность и правильность данных в базе данных.
Как создать таблицу с автоматическим увеличением значений
Для создания таблицы с автоматическим увеличением значений в SQL используется тип данных, поддерживающий автоинкремент (например, в MySQL или PostgreSQL). Это позволяет автоматически увеличивать значение столбца при каждой вставке новой строки.
В большинстве СУБД автоинкрементное поле реализуется с помощью ключевого слова AUTO_INCREMENT или SERIAL.
- MySQL: Для создания автоинкрементного столбца используется тип данных
INTс атрибутомAUTO_INCREMENT. - PostgreSQL: Здесь используется тип
SERIAL, который создает поле с автоинкрементом. - SQL Server: Для этого применяется тип
INTс атрибутомIDENTITY.
Пример создания таблицы с автоинкрементом в MySQL:
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100)
);
При вставке данных в такую таблицу значение для столбца id будет автоматически увеличиваться:
INSERT INTO users (name, email) VALUES ('Иван Иванов', 'ivan@example.com');
Важно помнить, что автоинкрементные столбцы обычно используются для первичных ключей, так как они гарантируют уникальность значений. Также можно настроить начальное значение или шаг увеличения в зависимости от СУБД.
В PostgreSQL автоинкрементное поле создается с помощью типа SERIAL:
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100)
);
В SQL Server синтаксис будет следующим:
CREATE TABLE users (
id INT IDENTITY(1,1) PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100)
);
Для настройки шагов автоинкремента и начального значения, используйте дополнительные параметры. Например, в MySQL можно установить начальное значение с помощью опции START WITH и шаг с помощью INCREMENT BY.
Пример настройки автоинкремента в MySQL:
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100)
) AUTO_INCREMENT = 1001;
Такой подход позволяет гибко управлять значениями автоинкремента в зависимости от потребностей.
Проверка и отладка созданной таблицы
Следующий этап – проверка ограничений. Если таблица содержит внешние ключи, уникальные индексы или другие ограничения, стоит выполнить тестовые вставки, чтобы убедиться в их работе. Использование INSERT, UPDATE и DELETE запросов позволит проверить, как ограничения влияют на данные.
Для поиска ошибок можно использовать SELECT запросы с различными условиями фильтрации и сортировки. Это поможет удостовериться, что данные сохраняются в правильном формате и что индексы работают корректно. Например, можно выполнить запрос с фильтром по числовому диапазону или текстовому поиску, чтобы увидеть, не нарушены ли ограничения длины строк.
Если в таблице используются индексы, важно проверить их эффективность. Для этого можно воспользоваться командой EXPLAIN, которая покажет план выполнения запроса, позволяя понять, насколько быстро выполняются операции поиска и обновления.
В случае, если обнаружены ошибки, стоит провести анализ структуры таблицы и данных. Иногда проблемы могут быть связаны с неверным выбором типов данных или некорректными связями между таблицами. В таких случаях полезно воспользоваться командой SHOW CREATE TABLE, которая отобразит полное определение таблицы с учётом всех параметров.