

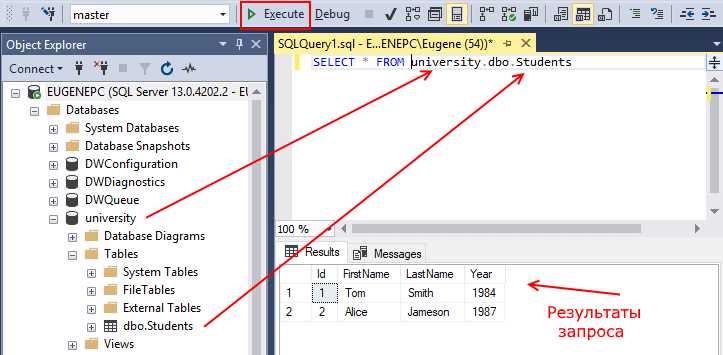
Создание таблицы в базе данных с помощью SQL-запроса – одна из базовых задач, с которой сталкивается каждый разработчик, работающий с реляционными СУБД. Для этого используется команда CREATE TABLE, которая позволяет определить структуру таблицы, указывая названия столбцов и их типы данных.
При написании запроса важно точно определить типы данных для каждого столбца. INT используется для хранения целых чисел, VARCHAR – для строк переменной длины, а DATE или DATETIME – для дат и временных значений. Эти типы данных влияют не только на корректность хранения информации, но и на производительность запросов.
Если требуется, можно указать дополнительные параметры для столбцов, например, задать первичный ключ с помощью PRIMARY KEY или установить уникальность значений через UNIQUE. Важно учитывать, что PRIMARY KEY автоматически создает индекс, что ускоряет операции поиска по этому столбцу.
Для обеспечения целостности данных часто используются ограничения NOT NULL, чтобы исключить наличие пустых значений в столбцах, где это критично, а также FOREIGN KEY для создания связей между таблицами. Эти ограничения помогают избежать ошибок и обеспечивают правильную работу базы данных в долгосрочной перспективе.
Задача разработчика – не только создать таблицу, но и правильно спроектировать её структуру, чтобы запросы к базе данных выполнялись эффективно. Правильный выбор типов данных и ограничений помогает избежать излишних сложностей в будущем, что снижает риск возникновения проблем при масштабировании системы.
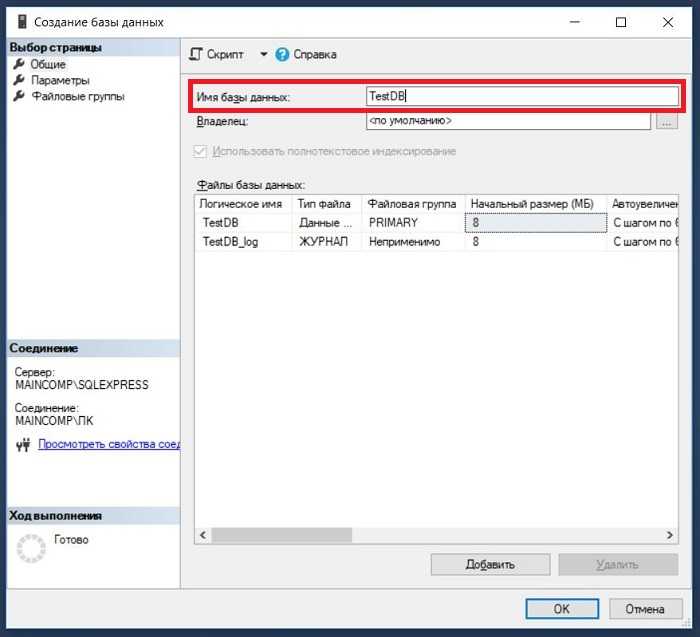
Определение структуры таблицы с помощью CREATE TABLE
SQL-запрос CREATE TABLE используется для создания новой таблицы в базе данных, определяя её структуру. Основной синтаксис включает в себя название таблицы и описание каждого столбца, его типа данных и дополнительных параметров.
Типы данных, используемые для столбцов, могут варьироваться в зависимости от СУБД, но наиболее распространённые – это INT (целые числа), VARCHAR (строки переменной длины), DATE (дата) и BOOLEAN (логический тип). Каждый столбец обязательно указывается с типом данных.
Пример базового запроса:
CREATE TABLE users ( id INT PRIMARY KEY, name VARCHAR(100), birthdate DATE );
В данном примере создаётся таблица users с тремя столбцами: id (целое число), name (строка длиной до 100 символов) и birthdate (дата рождения).
Можно добавить дополнительные ограничения к столбцам. Например, PRIMARY KEY гарантирует уникальность значений в столбце, а NOT NULL предотвращает появление пустых значений в определённом столбце.
Пример с дополнительными ограничениями:
CREATE TABLE employees ( id INT PRIMARY KEY, name VARCHAR(100) NOT NULL, salary DECIMAL(10, 2) NOT NULL, hire_date DATE );
Здесь столбец salary имеет тип данных DECIMAL, который позволяет хранить числа с плавающей запятой с точностью до двух знаков после запятой. Оба столбца name и salary не могут содержать пустых значений, так как у них установлено ограничение NOT NULL.
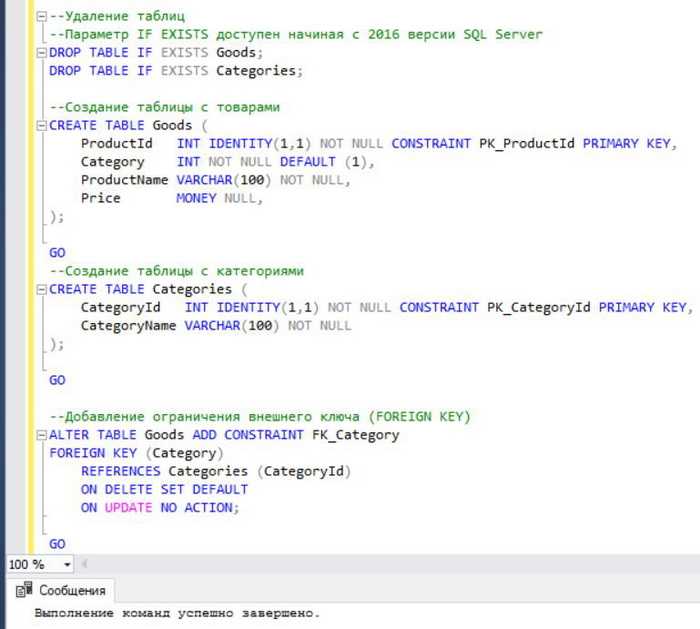
Можно также определить внешние ключи с помощью FOREIGN KEY, что позволяет связать таблицу с другой. Например, если у вас есть таблица departments, можно создать связь с таблицей employees:
CREATE TABLE departments ( id INT PRIMARY KEY, department_name VARCHAR(100) ); CREATE TABLE employees ( id INT PRIMARY KEY, name VARCHAR(100), department_id INT, FOREIGN KEY (department_id) REFERENCES departments(id) );
Здесь столбец department_id в таблице employees является внешним ключом, который ссылается на столбец id в таблице departments.
Для каждого столбца можно также указать значение по умолчанию с помощью DEFAULT. Это значение будет присвоено столбцу, если в момент вставки данных не указано иное значение.
Пример с установкой значения по умолчанию:
CREATE TABLE products ( id INT PRIMARY KEY, name VARCHAR(100), price DECIMAL(10, 2) DEFAULT 0.00 );
В данном случае, если при добавлении нового продукта не указана цена, в столбец price будет записано значение 0.00.
Правильное определение структуры таблицы важно для поддержания целостности данных, повышения производительности запросов и обеспечения корректности работы базы данных.
Выбор типов данных для столбцов таблицы
При создании таблицы в SQL важно правильно выбрать типы данных для каждого столбца, чтобы обеспечить оптимальное хранение данных и эффективное выполнение запросов. Ошибки в выборе типов могут привести к излишнему использованию памяти или замедлению работы базы данных.
Для хранения числовых значений следует использовать типы данных, такие как INT для целых чисел или DECIMAL для чисел с фиксированной точностью. Тип FLOAT подходит для данных с плавающей точкой, но из-за особенностей представления данных может привести к погрешностям при вычислениях.
Когда требуется хранить строки, выбор между типами CHAR и VARCHAR зависит от особенностей данных. Тип CHAR фиксированной длины подходит для строк одинаковой длины, например, для кодов или идентификаторов. Если длина строк варьируется, лучше использовать VARCHAR, что сэкономит место в таблице. Однако стоит помнить, что VARCHAR имеет дополнительные накладные расходы на хранение длины строки.
Для работы с датами и временем следует использовать типы DATE, TIME, DATETIME или TIMESTAMP. DATE подходит для хранения только даты, TIME – времени, а DATETIME и TIMESTAMP комбинируют дату и время. Выбор зависит от требований к точности и диапазону данных. Например, TIMESTAMP может быть полезен для отслеживания изменений в данных с учётом часового пояса.
Тип BOOLEAN часто используется для хранения логических значений (истина/ложь). В некоторых СУБД вместо BOOLEAN могут использоваться INT или TINYINT, где 0 – ложь, а 1 – истина.
Для хранения больших текстовых данных, таких как статьи или комментарии, следует использовать типы данных TEXT или CLOB. Эти типы поддерживают хранение значительных объёмов текста, но стоит учитывать, что они могут быть менее эффективными в плане быстродействия при поиске по содержимому.
Выбор типа данных также зависит от ожидаемого объёма данных. Например, если известно, что столбец всегда будет содержать небольшие значения (например, флаг или статус), использование типа SMALLINT или TINYINT будет более эффективно по сравнению с INT.
Наконец, важно учитывать требования к индексации столбцов. Для часто используемых в поисковых запросах столбцов следует выбирать типы данных, которые оптимально индексируются, например, числовые типы для фильтрации и сортировки. Использование слишком длинных строковых типов данных может замедлить индексирование и ухудшить производительность базы данных.
Установка ограничений на столбцы (NOT NULL, UNIQUE и другие)
Ограничения столбцов в SQL позволяют задать правила для данных, которые могут быть занесены в таблицу. Они помогают предотвратить ошибочные или нежелательные данные, обеспечивая целостность базы данных. Рассмотрим несколько ключевых типов ограничений.
NOT NULL – это ограничение, которое запрещает хранение пустых значений (NULL) в столбце. Оно полезно, когда нужно гарантировать, что в столбце всегда будет храниться значение. Например, в таблице с пользователями поле «имя» должно быть обязательным:
CREATE TABLE users ( id INT PRIMARY KEY, name VARCHAR(100) NOT NULL );
В данном случае, при попытке вставить запись без значения в поле «name», произойдёт ошибка.
UNIQUE – это ограничение, которое гарантирует, что все значения в столбце будут уникальными. Это полезно для полей, где не допускаются повторяющиеся данные, например, для адресов электронной почты или номеров телефонов:
CREATE TABLE users ( id INT PRIMARY KEY, email VARCHAR(100) UNIQUE );
В данном примере столбец «email» не может содержать два одинаковых значения. Если попытаться вставить запись с уже существующим значением, произойдёт ошибка.
PRIMARY KEY – это комбинация ограничения NOT NULL и UNIQUE. Столбец, определённый как PRIMARY KEY, должен содержать уникальные значения и не может быть пустым. Обычно он используется для идентификаторов записей:
CREATE TABLE users ( id INT PRIMARY KEY, name VARCHAR(100) );
В данном случае столбец «id» будет уникальным и обязательным для каждой записи.
FOREIGN KEY – это ограничение, которое устанавливает связь между столбцами в разных таблицах. Оно гарантирует, что значения в одном столбце соответствуют значениям в другом столбце, обеспечивая целостность данных между связанными таблицами. Например, можно установить связь между таблицами заказов и пользователей:
CREATE TABLE orders ( order_id INT PRIMARY KEY, user_id INT, FOREIGN KEY (user_id) REFERENCES users(id) );
В этом примере столбец «user_id» в таблице «orders» ссылается на столбец «id» в таблице «users». Если в таблице «users» нет записи с указанным идентификатором, то вставить заказ будет невозможно.
CHECK – это ограничение, которое позволяет задать логическое условие для значений столбца. Например, если столбец «age» должен содержать только положительные числа, можно использовать CHECK:
CREATE TABLE users ( id INT PRIMARY KEY, name VARCHAR(100), age INT CHECK (age > 0) );
В данном случае вставка записи с возрастом меньше или равным нулю приведёт к ошибке.
DEFAULT – это ограничение задаёт значение по умолчанию для столбца, если при вставке записи оно не указано. Например, для столбца «status» можно задать значение «active» по умолчанию:
CREATE TABLE users ( id INT PRIMARY KEY, name VARCHAR(100), status VARCHAR(50) DEFAULT 'active' );
Если при вставке данных не указано значение для «status», по умолчанию будет установлено значение «active».
Для более сложных случаев можно комбинировать несколько ограничений в одном столбце. Например, столбец может быть одновременно PRIMARY KEY и NOT NULL, или можно использовать UNIQUE вместе с CHECK для дополнительной валидации данных.
Как задать первичный ключ (PRIMARY KEY) для таблицы
1. Указание первичного ключа при создании таблицы
Для задания первичного ключа при создании таблицы используется ключевое слово PRIMARY KEY. Обычно первичный ключ задаётся для одного или нескольких столбцов, которые будут уникально идентифицировать запись в таблице.
CREATE TABLE Employees (
EmployeeID INT NOT NULL,
LastName VARCHAR(100),
FirstName VARCHAR(100),
PRIMARY KEY (EmployeeID)
);- В данном примере
EmployeeIDявляется первичным ключом. Это означает, что для каждого сотрудника в таблице будет уникальный идентификатор. - Поле, которое используется в качестве первичного ключа, не может содержать
NULLзначения.
2. Указание составного первичного ключа
Если таблица требует уникальной идентификации через комбинацию нескольких столбцов, можно использовать составной первичный ключ. Он позволяет объединить несколько столбцов для создания уникальной записи.
CREATE TABLE Orders (
OrderID INT NOT NULL,
ProductID INT NOT NULL,
Quantity INT,
PRIMARY KEY (OrderID, ProductID)
);- Здесь составной первичный ключ состоит из двух столбцов:
OrderIDиProductID. Это позволяет уникально идентифицировать каждую строку в таблице.
3. Добавление первичного ключа в существующую таблицу
Если таблица уже существует, можно добавить первичный ключ с помощью команды ALTER TABLE.
ALTER TABLE Employees
ADD PRIMARY KEY (EmployeeID);- Если в таблице уже есть строки с повторяющимися значениями в столбце, для которого задаётся первичный ключ, операция завершится ошибкой.
4. Ограничения при выборе столбца для первичного ключа
Перед тем как назначить столбец первичным ключом, стоит учесть несколько важных ограничений:
- Уникальность: Значения в столбце должны быть уникальными для каждой записи.
- Невозможность NULL: Столбец не может содержать NULL-значения.
- Тип данных: Обычно для первичного ключа используют числовые или строковые типы данных, которые гарантируют уникальность и простоту индексации.
5. Индексация первичного ключа
SQL автоматически создаёт уникальный индекс для столбца, который является первичным ключом. Этот индекс ускоряет операции поиска, вставки и удаления строк в таблице. Не нужно создавать индекс вручную, если столбец уже является первичным ключом.
6. Удаление первичного ключа

Если необходимо удалить первичный ключ, можно использовать команду ALTER TABLE с параметром DROP PRIMARY KEY.
ALTER TABLE Employees
DROP PRIMARY KEY;- Удаление первичного ключа также удаляет уникальный индекс, связанный с этим столбцом.
Добавление внешних ключей (FOREIGN KEY) для связей между таблицами
Чтобы создать внешний ключ, нужно определить его в момент создания таблицы или добавить позже с помощью команды ALTER TABLE. Рассмотрим оба варианта.
Пример создания внешнего ключа при создании таблицы:
CREATE TABLE Заказы ( заказ_id INT PRIMARY KEY, клиент_id INT, дата_заказа DATE, FOREIGN KEY (клиент_id) REFERENCES Клиенты(клиент_id) );
В данном примере поле клиент_id в таблице «Заказы» является внешним ключом, ссылающимся на поле клиент_id таблицы «Клиенты».
Если таблица уже существует, внешний ключ можно добавить с помощью команды ALTER TABLE:
ALTER TABLE Заказы ADD CONSTRAINT fk_клиент_id FOREIGN KEY (клиент_id) REFERENCES Клиенты(клиент_id);
Важно соблюдать несколько правил при работе с внешними ключами:
- Поле, на которое ссылается внешний ключ, должно быть уникальным, обычно это первичный ключ.
- Типы данных поля внешнего ключа и поля первичного ключа должны совпадать.
- Если значение в поле внешнего ключа не находит соответствие в другой таблице, операция будет отклонена.
Также стоит отметить возможность использования дополнительных параметров, таких как ON DELETE CASCADE и ON UPDATE CASCADE, которые определяют поведение при изменении или удалении связанных записей:
CREATE TABLE Заказы ( заказ_id INT PRIMARY KEY, клиент_id INT, дата_заказа DATE, FOREIGN KEY (клиент_id) REFERENCES Клиенты(клиент_id) ON DELETE CASCADE ON UPDATE CASCADE );
Опция ON DELETE CASCADE автоматически удаляет связанные записи в таблице «Заказы», если соответствующий клиент из таблицы «Клиенты» удалён. Аналогично, ON UPDATE CASCADE обновляет значения внешнего ключа в таблице «Заказы», если изменяется значение первичного ключа в таблице «Клиенты».
Важно правильно проектировать таблицы и связи между ними, чтобы избежать ненужных зависимостей или цикличных ссылок. Внешние ключи помогают поддерживать целостность данных и предотвращают ошибки, связанные с удалением или изменением записей в одной таблице, которые могут повлиять на другие.
Как создать таблицу с автоинкрементом для уникальных значений
Для создания таблицы в SQL, где одно из полей будет автоматически увеличиваться при добавлении новой строки, используется тип данных AUTO_INCREMENT (MySQL) или SERIAL (PostgreSQL). Эти типы обеспечивают уникальность значений в колонке и помогают упростить управление идентификаторами. Рассмотрим, как это реализуется на примере SQL-запроса.
В MySQL для создания таблицы с автоинкрементом можно использовать следующий запрос:
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100) UNIQUE
);В данном примере колонка id автоматически получает уникальные значения при добавлении каждой новой строки. Тип данных INT гарантирует, что идентификаторы будут числовыми, а AUTO_INCREMENT заставляет значение увеличиваться на единицу для каждой новой строки.
Если вы используете PostgreSQL, аналогичный запрос будет выглядеть так:
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100) UNIQUE
);Здесь SERIAL автоматически создает уникальные значения для колонки id и устанавливает ее как первичный ключ.
Важно помнить, что при использовании автоинкремента нельзя явно указать значение для этой колонки при вставке данных. Например, в запросе:
INSERT INTO users (name, email) VALUES ('John Doe', 'john.doe@example.com');Значение для поля id будет автоматически присвоено сервером базы данных. Если же требуется перезаписать текущее значение автоинкремента, можно использовать специальные команды, такие как ALTER TABLE для MySQL или SETVAL для PostgreSQL.
Кроме того, для создания уникальных значений в других колонках (например, email) можно использовать ограничение UNIQUE, которое гарантирует, что в таблице не будет двух строк с одинаковыми значениями в указанной колонке.
Таким образом, использование автоинкремента и ограничений на уникальность позволяет легко управлять идентификаторами и обеспечить целостность данных в таблице.
Пример создания таблицы с несколькими индексами для ускорения запросов
Предположим, у нас есть таблица заказов с полями order_id, customer_id, order_date и total_amount. Мы создадим несколько индексов, чтобы ускорить выполнение различных типов запросов.
Пример создания таблицы с индексами:
CREATE TABLE orders ( order_id INT PRIMARY KEY, customer_id INT, order_date DATE, total_amount DECIMAL(10, 2) );
Теперь добавим индексы. Первый индекс будет создан на поле customer_id, так как мы часто будем искать заказы по клиенту:
CREATE INDEX idx_customer_id ON orders (customer_id);
Второй индекс на поле order_date позволит ускорить запросы, сортирующие заказы по дате:
CREATE INDEX idx_order_date ON orders (order_date);
Третий индекс может быть составным и включать два поля: customer_id и order_date, что ускорит запросы, которые фильтруют заказы по клиенту и дате:
CREATE INDEX idx_customer_order_date ON orders (customer_id, order_date);
Важно помнить, что создание индексов увеличивает время вставки, обновления и удаления данных, так как индексы тоже нужно поддерживать. Поэтому важно сбалансировать количество индексов с необходимостью их использования в запросах.
В случаях, когда запросы часто выполняют соединение по полям customer_id и order_date, составной индекс может значительно ускорить выполнение, так как запросы будут использовать этот индекс для быстрого доступа к данным.
Однако следует избегать создания слишком большого количества индексов, так как это может привести к излишним накладным расходам на обслуживание индексов, особенно при больших объемах данных. Регулярно анализируйте запросы и определяйте, какие индексы действительно необходимы для оптимизации производительности.





