Связывание нескольких таблиц в SQL – ключевая операция для работы с реляционными базами данных, позволяющая объединять данные, распределённые по различным структурам. Это важно, когда информация логически разделена между таблицами, но для выполнения запросов нужно объединить её в одном результате. На практике наиболее часто используются операции JOIN, такие как INNER JOIN, LEFT JOIN и RIGHT JOIN, каждая из которых имеет свою область применения.
Основной принцип соединения таблиц – использование ключей: обычно это первичные и внешние ключи, которые обеспечивают целостность данных. При правильной настройке связей можно избежать дублирования информации, улучшить производительность запросов и упростить обслуживание базы данных. Важно помнить, что выбор типа соединения зависит от того, какие именно данные вы хотите получить и как они представлены в базе.
Для того чтобы эффективно связать несколько таблиц, стоит учитывать не только тип соединения, но и оптимизацию запросов. Например, при использовании INNER JOIN важно минимизировать число строк, участвующих в соединении, а при работе с LEFT JOIN или RIGHT JOIN – избегать ненужных значений NULL, если они не несут полезной информации для конечного результата.
Выбор типа соединения: INNER JOIN, LEFT JOIN, RIGHT JOIN или FULL JOIN
INNER JOIN – это наиболее распространённый тип соединения. Он возвращает только те строки, которые имеют совпадения в обеих таблицах. Это соединение идеально подходит, если необходимо работать только с теми записями, которые присутствуют в обеих таблицах. Например, для получения информации о заказах и клиентах, которые сделали эти заказы, INNER JOIN обеспечит результат только для тех клиентов, у которых есть хотя бы один заказ.
LEFT JOIN (или LEFT OUTER JOIN) возвращает все строки из левой таблицы и соответствующие строки из правой. Если в правой таблице нет соответствующего значения, то для этих строк будут использованы значения NULL. Этот тип соединения полезен, когда нужно сохранить все записи из левой таблицы, даже если для некоторых из них нет данных в правой. Например, для отображения списка всех сотрудников и их проектов, LEFT JOIN позволит вывести сотрудников без проектов с пустыми значениями в колонках правой таблицы.
RIGHT JOIN (или RIGHT OUTER JOIN) аналогичен LEFT JOIN, но сохраняет все строки из правой таблицы. Если для строки из правой таблицы нет соответствующего значения в левой, то в результирующем наборе данных появятся значения NULL для левой таблицы. Этот тип соединения используется реже, чем LEFT JOIN, но может быть полезен в случаях, когда важно сохранить все данные из правой таблицы, а не из левой.
FULL JOIN (или FULL OUTER JOIN) объединяет результаты LEFT JOIN и RIGHT JOIN. Он возвращает все строки из обеих таблиц, заполняя отсутствующие значения NULL. Используется, когда необходимо получить полную информацию из обеих таблиц, включая те строки, которые не имеют соответствующих значений в другой таблице. Этот тип соединения редко применяется, поскольку может привести к значительным объёмам данных с NULL-значениями, но он полезен в сложных аналитических запросах, где важно учесть все записи.
Правильный выбор типа соединения зависит от задачи. INNER JOIN подходит для фильтрации данных, где важны только соответствующие записи. LEFT JOIN используется, когда необходимо сохранить все данные из левой таблицы, даже если нет совпадений в правой. RIGHT JOIN применяется для аналогичной задачи с правой таблицей. FULL JOIN пригоден в случаях, когда требуется объединить всё содержимое обеих таблиц, даже если некоторые записи не имеют соответствий.
Использование ON и USING для корректной связи таблиц

В SQL существуют два основных способа указания условий для соединения таблиц: через ключевое слово ON и через USING. Оба метода выполняют одинаковую функцию, но их использование зависит от контекста и структуры данных.
ON позволяет гибко указывать условия соединения, что делает его предпочтительным в более сложных случаях. Он используется, когда столбцы, по которым происходит соединение, имеют разные имена в разных таблицах. Например:
SELECT *
FROM orders o
JOIN customers c ON o.customer_id = c.id;Здесь столбцы customer_id из таблицы orders и id из таблицы customers связываются через условие, заданное в ON.
При использовании ON важно помнить, что условие может быть более сложным, включать логические операторы или несколько сравнений. Например, можно соединить таблицы по нескольким столбцам или задать дополнительное условие для фильтрации данных:
SELECT *
FROM orders o
JOIN customers c ON o.customer_id = c.id AND o.status = 'active';С другой стороны, USING используется для простых случаев, когда столбцы, по которым происходит соединение, имеют одинаковые имена. Этот оператор упрощает запрос и делает его более читаемым. Пример:
SELECT *
FROM orders o
JOIN customers c USING (customer_id);Здесь столбцы с одинаковым именем customer_id в обеих таблицах автоматически используются для соединения. Важно отметить, что USING можно применить только тогда, когда имена столбцов совпадают, иначе запрос завершится ошибкой.
Кроме того, в случае использования USING результирующий набор будет содержать только один столбец с названием customer_id, исключив дублирование данных.
Таким образом, выбор между ON и USING зависит от ситуации. Для простоты и читаемости кода используйте USING, когда имена столбцов совпадают. В более сложных случаях или при необходимости в дополнительных условиях соединения используйте ON.
Оптимизация запросов с несколькими соединениями
Чем больше соединений (JOIN) содержит SQL-запрос, тем выше нагрузка на планировщик запросов и оптимизатор. Чтобы минимизировать издержки, необходимо заранее определить критически важные связи и использовать только те таблицы, которые реально нужны для выборки. Применяйте EXPLAIN для анализа плана выполнения: он показывает, какие индексы используются, в каком порядке обрабатываются таблицы и где возможны узкие места.
При соединении большого количества таблиц по внешним ключам, всегда проверяйте наличие индексов на полях, участвующих в условиях соединения. Например, если используется INNER JOIN orders ON users.id = orders.user_id, убедитесь, что на orders.user_id есть индекс. Без него СУБД будет сканировать таблицу целиком.
Избегайте соединений с подзапросами, особенно если они возвращают большое количество строк. Вместо SELECT ... FROM A JOIN (SELECT ...) B эффективнее использовать WITH-выражения (CTE) с явной фильтрацией или агрегированием до соединения.
Сортировки, агрегации и фильтры должны быть как можно ближе к источнику данных. Применяйте условия WHERE и HAVING до выполнения соединений, чтобы уменьшить объём обрабатываемых данных. В случае сложных многотабличных запросов разделите их на несколько шагов с сохранением промежуточных результатов во временные таблицы – это упростит отладку и повысит читаемость.
Порядок соединений имеет значение. Некоторые СУБД (например, PostgreSQL) сами определяют оптимальный порядок, но в MySQL порядок следования JOIN’ов может напрямую влиять на производительность. Сначала соединяйте таблицы с наименьшим количеством строк после фильтрации.
Минимизируйте использование SELECT *. Явное указание нужных полей уменьшает объём передаваемых данных и ускоряет выполнение запроса.
Как работать с самосоединениями (self join) в SQL

Для выполнения самосоединения в SQL используется оператор JOIN, где одна из копий таблицы будет представлять собой «левое» соединение, а другая – «правое». Каждая из копий получает уникальный псевдоним, чтобы отличать поля, даже если они имеют одинаковые имена.
Основной синтаксис самосоединения:
SELECT A.column1, B.column2 FROM table_name A JOIN table_name B ON A.column_name = B.column_name;
Здесь:
- A и B – псевдонимы одной и той же таблицы.
- column1 и column2 – выбираемые столбцы из разных копий таблицы.
- column_name – столбец, по которому производится соединение.
Пример. У вас есть таблица employees с данными о сотрудниках и их руководителях. Каждый сотрудник может быть связан с руководителем через поле manager_id, которое ссылается на employee_id того же сотрудника.
Запрос, который находит имя сотрудника и его руководителя:
SELECT e.employee_name, m.employee_name AS manager_name FROM employees e JOIN employees m ON e.manager_id = m.employee_id;
В данном примере таблица employees соединяется сама с собой: одна копия таблицы содержит данные сотрудников (с псевдонимом e), а другая – данные их руководителей (с псевдонимом m).
Основные рекомендации при работе с самосоединениями:
- Используйте псевдонимы для каждой копии таблицы, чтобы избежать путаницы и сделать запросы читаемыми.
- При работе с иерархиями учитывайте, что самосоединение может привести к повторению данных, если не ограничить выборку условиями в
WHEREилиHAVING. - При соединении таблицы с самой собой всегда проверяйте наличие индексов на ключевых полях (например, на
employee_idиmanager_id), чтобы ускорить выполнение запроса.
Самосоединения особенно полезны для работы с иерархическими данными, такими как отчётные структуры, семейные деревья, каталоги продуктов с подкатегориями и т.п.
Пример работы с несколькими таблицами в подзапросах
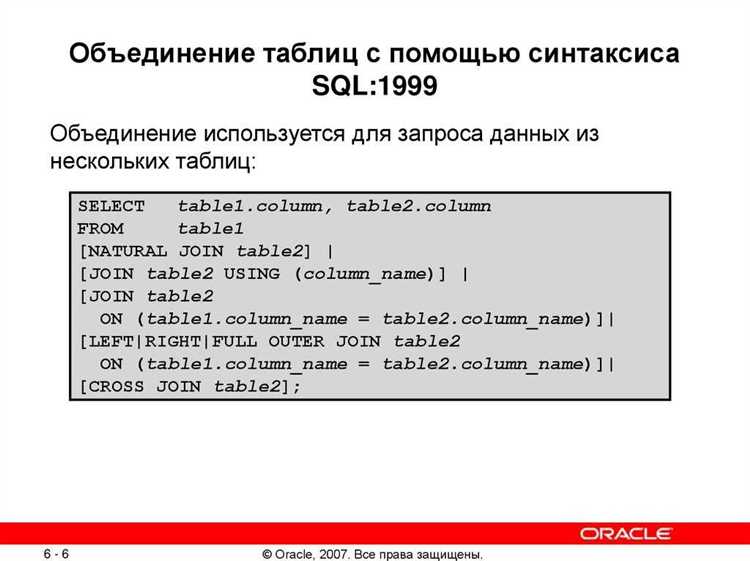
Подзапросы в SQL позволяют извлекать данные из одной таблицы на основе информации из другой. Рассмотрим пример, когда необходимо получить список сотрудников, работающих в отделах, где средняя зарплата выше 50 000 рублей.
Предположим, у нас есть две таблицы: employees (сотрудники) и departments (отделы). Чтобы найти нужных сотрудников, можно использовать подзапрос для фильтрации отделов с высокой средней зарплатой.
SELECT e.employee_id, e.name, e.salary, e.department_id FROM employees e WHERE e.department_id IN ( SELECT d.department_id FROM departments d JOIN employees e2 ON e2.department_id = d.department_id GROUP BY d.department_id HAVING AVG(e2.salary) > 50000 );
Здесь подзапрос выбирает department_id всех отделов, в которых средняя зарплата сотрудников превышает 50 000 рублей. Основной запрос затем использует результат этого подзапроса, чтобы отфильтровать сотрудников по соответствующим отделам.
Подзапросы могут быть использованы не только для фильтрации данных, но и для выборки агрегаций или объединений. В данном примере JOIN между таблицами employees и departments позволяет соединить информацию о сотрудниках и их отделах, а агрегатная функция AVG вычисляет среднюю зарплату.
Важно учитывать, что подзапросы могут быть менее эффективными, чем прямые соединения, особенно при больших объемах данных. В таких случаях стоит рассматривать использование явных JOIN-ов, которые могут быть оптимизированы СУБД.
Как избежать ошибок при связывании таблиц с одинаковыми именами столбцов
Связывание нескольких таблиц в SQL, где есть одинаковые имена столбцов, может привести к неопределённости и ошибкам в запросах. Чтобы избежать таких ситуаций, следует соблюдать несколько важных рекомендаций:
- Используйте псевдонимы для таблиц. Присваивание псевдонимов (alias) таблицам помогает избежать путаницы при обращении к столбцам с одинаковыми именами. Например, вместо того чтобы писать
SELECT column_name FROM table1, table2, используйте псевдонимы:SELECT t1.column_name, t2.column_name FROM table1 AS t1 JOIN table2 AS t2. - Указывайте полный путь к столбцу. Всегда указывайте не только имя столбца, но и имя таблицы или её псевдоним перед каждым столбцом, особенно при использовании объединений (JOIN). Это исключает неоднозначность. Например,
SELECT t1.column_name, t2.column_name FROM table1 t1 JOIN table2 t2 ON t1.id = t2.id. - Используйте префиксы для столбцов. Если таблицы содержат одинаковые столбцы, например,
idилиname, можно добавить префикс к имени столбца при его выборке:SELECT t1.id AS id1, t2.id AS id2 FROM table1 t1 JOIN table2 t2. - Следите за структурой данных. Столкнувшись с одинаковыми столбцами, важно удостовериться, что они имеют одинаковый тип данных. Это поможет избежать ошибок при объединении таблиц, особенно если используется операция
JOINна этих столбцах. - Используйте явное указание
JOINвместо запятых. При связывании нескольких таблиц рекомендуется использоватьJOINдля уточнения условий объединения. Запятая может привести к неявному кросс-присоединению, что усложняет анализ запроса и повышает вероятность ошибок. - Проверяйте уникальность столбцов в выборке. Когда в запросе участвуют несколько таблиц с одинаковыми именами столбцов, всегда уточняйте, что именно требуется выбрать: все столбцы или только определённые. Это предотвратит дублирование данных и ошибки при их обработке.
- Используйте
COALESCEилиCASEдля обработки NULL-значений. Если при объединении таблиц с одинаковыми столбцами могут появляться NULL-значения, используйте функции для их обработки, например,COALESCE, чтобы указать альтернативные значения.
Применяя эти подходы, можно минимизировать вероятность ошибок при работе с таблицами, содержащими одинаковые столбцы, и сделать SQL-запросы более стабильными и читаемыми.
Порядок соединений таблиц и влияние на производительность запроса
При соединении нескольких таблиц в SQL порядок их соединений играет важную роль в производительности запроса. SQL-оптимизатор может по-разному интерпретировать порядок операций, и эффективность выполнения запроса зависит от порядка, в котором таблицы соединяются.
Самый распространённый подход – это последовательное соединение таблиц в порядке их появления в запросе. Однако, на практике, такой подход не всегда оптимален. Проблемы могут возникать, если соединяемые таблицы имеют большое количество строк, а также если не использованы индексы для ускорения операций. Важно учитывать несколько факторов, таких как размер таблиц, индексы и тип соединений.
Для эффективной работы запроса рекомендуется использовать следующие стратегии:
- Начинать с таблиц с меньшим числом строк: если одна из таблиц имеет значительно меньше строк, её лучше соединить первой. Это позволит минимизировать объем данных, с которыми работают другие таблицы.
- Использовать индексы: при соединении таблиц на полях, которые индексированы, запрос будет выполняться быстрее. Важно, чтобы индексы соответствовали условиям соединения и были актуальными.
- Расположение условий соединения: разместив условия фильтрации (например, через WHERE или ON) перед соединением, можно уменьшить количество строк, с которыми работает SQL-оптимизатор.
- Использовать правильные типы соединений: в зависимости от задачи, INNER JOIN, LEFT JOIN или другие типы соединений могут иметь разные эффекты на производительность. INNER JOIN, например, обычно работает быстрее, чем LEFT JOIN, так как исключает строки, не имеющие совпадений.
Важно помнить, что для оптимизации запроса всегда стоит проверять результаты выполнения с помощью EXPLAIN, чтобы увидеть план выполнения и возможные узкие места.
Пример неправильного порядка соединений:
SELECT A.*, B.*, C.* FROM A JOIN B ON A.id = B.id JOIN C ON B.id = C.id;
В этом запросе сначала соединяются таблицы A и B, а затем результат соединяется с таблицей C. Это может привести к излишнему объему данных, если таблица B имеет много строк, а таблица C – относительно небольшая.
Правильный порядок может выглядеть так:
SELECT A.*, B.*, C.* FROM C JOIN B ON C.id = B.id JOIN A ON A.id = B.id;
Здесь сначала соединяются таблицы C и B, что позволяет уменьшить объем данных на следующем шаге.
Таким образом, для повышения производительности запроса необходимо внимательно следить за порядком соединений таблиц, их размером и правильностью индексации. Несоответствующий порядок соединений может значительно замедлить выполнение запроса и увеличить нагрузку на базу данных.
Применение алиасов для улучшения читаемости сложных запросов
Использование алиасов в SQL позволяет значительно упростить восприятие сложных запросов, особенно когда необходимо связать несколько таблиц. Алиасы помогают сделать запросы более компактными и читаемыми, а также предотвращают возникновение путаницы при работе с длинными именами таблиц и полей.
При работе с множеством таблиц важно задавать алиасы таким образом, чтобы они были интуитивно понятными и отражали суть данных. Например, вместо использования полного имени таблицы employees, можно присвоить ей алиас e, что значительно сократит длину запросов, но при этом не потеряет ясности, если правильно выбрать алиас для каждой таблицы.
В случае с запросами, включающими несколько соединений, алиасы становятся незаменимыми для предотвращения двусмысленности. Например, если нужно объединить таблицы employees и departments, можно использовать алиасы e и d, соответственно. Запрос с алиасами будет выглядеть гораздо проще:
SELECT e.name, d.department_name FROM employees e JOIN departments d ON e.department_id = d.id;
Важным аспектом является использование алиасов для колонок. Если в запросе используются несколько полей с одинаковыми именами из разных таблиц, алиас для колонки позволяет избежать ошибок. Например:
SELECT e.name AS employee_name, d.department_name FROM employees e JOIN departments d ON e.department_id = d.id;
Здесь employee_name делает название колонки более специфичным, указывая, что это имя сотрудника, а не название отдела.
Кроме того, алиасы могут быть полезны при создании вычисляемых колонок. Например, если нужно посчитать возраст сотрудника, можно создать алиас для этого вычисления:
SELECT e.name, YEAR(CURDATE()) - YEAR(e.birth_date) AS age FROM employees e;
Задание алиаса для вычисляемого значения улучшает читаемость, позволяя сразу понять, что столбец представляет собой возраст сотрудника, а не какой-либо другой показатель.
Важно помнить, что алиасы следует выбирать таким образом, чтобы они не только сокращали запрос, но и оставались логичными и понятными для других разработчиков, которые будут работать с этим кодом. В конце концов, цель алиасов – повысить ясность, а не скрыть суть данных.
Вопрос-ответ:
Что такое связь таблиц в SQL и зачем она нужна?
Связь таблиц в SQL позволяет объединить данные из разных таблиц, что дает возможность более гибко работать с информацией. Обычно это делается с помощью ключевых полей, которые позволяют соединить строки из разных таблиц по соответствующим значениям. Например, можно создать связь между таблицей заказов и таблицей клиентов, чтобы для каждого заказа был доступен контакт клиента. Связи позволяют строить сложные запросы, объединяя данные из нескольких источников.
Как правильно связать несколько таблиц в SQL?
Для связи нескольких таблиц в SQL обычно используют операторы JOIN. С помощью этих операторов можно объединять данные из двух или более таблиц по ключевым полям. Наиболее часто используется INNER JOIN, который возвращает строки, когда есть совпадение в обеих таблицах. Также есть LEFT JOIN (или LEFT OUTER JOIN), который вернет все строки из левой таблицы, а из правой — только те, которые соответствуют условиям связи. Если строки правой таблицы не подходят под условие, то они будут заполнены значениями NULL. Помимо этого, есть RIGHT JOIN (или RIGHT OUTER JOIN), который работает аналогично LEFT JOIN, но возвращает все строки из правой таблицы, а из левой — только соответствующие. Для работы с несколькими таблицами важно правильно определить, по каким полям будут происходить объединения, чтобы данные были логично связаны.