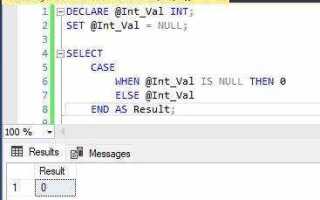
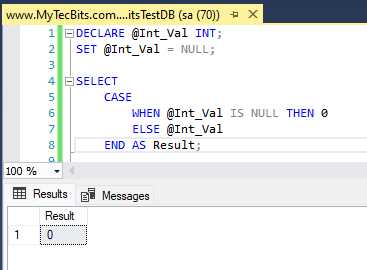
NULL-значения в реляционных базах данных представляют собой отсутствие данных и не поддаются традиционным операциям сравнения. Это усложняет фильтрацию и агрегацию, нарушает ожидаемое поведение JOIN-ов и приводит к ошибкам при вычислениях. Эффективная работа с NULL требует точного понимания механики SQL и выбора соответствующих техник обработки.
Первый способ устранения NULL – использование конструкции IS NOT NULL в WHERE-условиях. Это позволяет исключить строки с отсутствующими значениями на этапе выборки. Например, SELECT * FROM сотрудники WHERE зарплата IS NOT NULL вернёт только те записи, где зарплата задана.
Для агрегации данных важно учитывать, что функции AVG, SUM, COUNT по умолчанию игнорируют NULL. Однако COUNT(*) учитывает все строки, включая те, где значения отсутствуют. При необходимости точного контроля следует использовать COUNT(поле).
При объединении таблиц с помощью LEFT JOIN необходимо применять фильтрацию по NULL в связанных таблицах, чтобы определить, были ли найдены соответствующие записи. Условие WHERE другая_таблица.id IS NULL позволяет выявить отсутствующие связи, что важно для анализа неполных данных.
Использование CASE в SELECT-запросах обеспечивает гибкое управление логикой отображения NULL. Пример: CASE WHEN дата_увольнения IS NULL THEN ‘Работает’ ELSE ‘Уволен’ – улучшает читаемость данных без изменения самой структуры таблицы.
Как удалить строки с null в конкретном столбце с помощью WHERE
Для удаления строк, содержащих null в определённом столбце, используется оператор DELETE с условием WHERE. Важно правильно указать имя столбца, чтобы исключить только те строки, где значение в этом столбце равно null.
Пример запроса:
DELETE FROM table_name WHERE column_name IS NULL;
В данном случае, столбец column_name проверяется на наличие значений null, и все строки с такими значениями удаляются. Оператор IS NULL – это стандартный способ проверки на null в SQL, так как простой оператор «=» не подходит для сравнения с null.
Перед выполнением запроса рекомендуется убедиться, что удаляются только те строки, которые действительно нужно удалить. Для этого можно сначала выполнить SELECT запрос с аналогичным условием, чтобы проверить, какие строки будут затронуты:
SELECT * FROM table_name WHERE column_name IS NULL;
Также стоит помнить, что операция DELETE необратима, и данные будут безвозвратно удалены. В случае необходимости восстановления информации можно заранее сделать резервную копию таблицы или использовать транзакции.
Если нужно удалить строки с null в нескольких столбцах, можно комбинировать условия с помощью оператора AND:
DELETE FROM table_name WHERE column_name1 IS NULL AND column_name2 IS NULL;
Этот запрос удаляет только те строки, где оба столбца имеют значение null. Если нужно, чтобы хотя бы одно из условий выполнялось, используется оператор OR:
DELETE FROM table_name WHERE column_name1 IS NULL OR column_name2 IS NULL;
Таким образом, операторы WHERE с IS NULL позволяют точно управлять удалением строк с null в нужных столбцах, минимизируя вероятность ошибок.
Использование IS NOT NULL для фильтрации результатов

Применение IS NOT NULL помогает сузить выборку и уменьшить количество ненужных строк в результате. Например, если необходимо найти всех клиентов, у которых указан email, запрос будет выглядеть так:
SELECT * FROM customers WHERE email IS NOT NULL;
Данный запрос возвращает только те записи, в которых поле email содержит данные. Важно, что IS NOT NULL используется именно для исключения пустых значений, а не для проверки пустых строк или значений по умолчанию.
При работе с IS NOT NULL важно учитывать, что этот оператор исключает только те строки, где значение столбца равно NULL, но не обрабатывает случаи, когда в поле указана пустая строка (») или другие специфичные значения, такие как нулевые даты. В таких случаях необходимо комбинировать IS NOT NULL с другими операторами, чтобы более точно настроить фильтрацию данных.
Например, если нужно получить записи, где email не пустой и не является пустой строкой, можно использовать такой запрос:
SELECT * FROM customers WHERE email IS NOT NULL AND email <> '';
Это гарантирует, что результат будет включать только те строки, где поле email действительно заполнено и не является пустым.
Использование IS NOT NULL также важно в контексте производительности запросов. Например, индексы на столбцах, которые часто фильтруются с помощью этого оператора, могут значительно ускорить выполнение запросов. Однако для улучшения производительности важно, чтобы в базе данных не было значительного количества строк с NULL значениями, что может негативно сказаться на эффективности индексации.
Удаление записей с null через подзапросы

Простой пример удаления записей с null в одном из столбцов может выглядеть следующим образом:
DELETE FROM employees
WHERE id IN (SELECT id FROM employees WHERE department IS NULL);В этом примере подзапрос сначала выбирает все записи, у которых значение в столбце «department» равно NULL, а основной запрос удаляет эти записи. Важно, что подзапрос использует идентификатор записи (например, «id»), чтобы корректно идентифицировать и удалить нужные строки.
Подзапросы позволяют избегать необходимости выполнять сложные операции с объединением таблиц, если задача ограничивается удалением по одному или нескольким критериям, включая NULL значения. Кроме того, такой подход дает возможность выполнять удаление только на основе отфильтрованных данных, что помогает сохранить производительность базы данных при большом объеме записей.
Важно помнить, что подзапросы должны быть написаны с учетом возможных проблем производительности. Например, подзапросы, возвращающие большое количество строк, могут негативно сказаться на скорости выполнения запроса. В таких случаях рекомендуется использовать индексы на столбцы, которые участвуют в фильтрации, или ограничить выборку с помощью дополнительных условий в подзапросе.
Использование подзапросов для удаления записей с NULL значениями подходит в случаях, когда требуется точечное удаление без воздействия на другие данные в таблице. Этот подход также помогает предотвратить случайное удаление данных, если запрос не будет слишком широким или неоптимизированным.
Применение JOIN для исключения null из связанных таблиц
В SQL запросах использование оператора JOIN позволяет объединить данные из нескольких таблиц. Однако при этом могут возникать строки с значениями NULL, если одна из таблиц не содержит соответствующих данных для соединения. Для исключения таких значений можно применить различные стратегии с использованием JOIN.
Основной техникой является использование INNER JOIN, который автоматически исключает строки с NULL в полях, участвующих в соединении. Это гарантирует, что в результирующем наборе данных будут только те строки, где существуют совпадения в обеих таблицах.
INNER JOIN– соединяет только те строки, где есть соответствие в обеих таблицах. Если одна из сторон не имеет записи, связанной с другой, результат исключает такие строки.LEFT JOIN– если необходимо сохранить все записи из левой таблицы, но исключить строки сNULLиз правой таблицы, можно добавить условиеWHEREдля исключения этих значений.RIGHT JOIN– аналогиченLEFT JOIN, но с приоритетом для правой таблицы. Также применимо условие для удаления строк сNULL.
Пример использования INNER JOIN:
SELECT orders.order_id, customers.customer_name
FROM orders
INNER JOIN customers ON orders.customer_id = customers.customer_id;
Этот запрос вернет только те заказы, которые связаны с существующими клиентами. Строки с NULL в поле customer_id в таблице orders не будут включены в результат.
Для использования LEFT JOIN с исключением NULL в правой таблице, можно добавить фильтрацию:
SELECT orders.order_id, customers.customer_name
FROM orders
LEFT JOIN customers ON orders.customer_id = customers.customer_id
WHERE customers.customer_name IS NOT NULL;
В этом случае результат будет включать все заказы, но только те, у которых есть соответствующие клиенты в таблице customers.
Таким образом, правильное использование JOIN позволяет контролировать наличие NULL в результирующих данных, гарантируя точность и полноту выборки. Выбор типа соединения зависит от требований к данным и особенностей базы данных.
Удаление строк с несколькими null в разных столбцах

Удаление строк с несколькими значениями NULL в различных столбцах может быть важной задачей для очистки данных в SQL. Иногда бывает необходимо исключить строки, где хотя бы в двух или более столбцах содержатся пустые значения. Для этого можно использовать конструкцию WHERE с операторами IS NULL и логическими выражениями.
Простой пример запроса, удаляющего строки с NULL в двух столбцах (например, column1 и column2), выглядит так:
DELETE FROM table_name WHERE column1 IS NULL AND column2 IS NULL;
Этот запрос удалит строки, где оба столбца содержат NULL. Однако, если необходимо проверить большее количество столбцов, можно добавлять дополнительные условия с логическим оператором AND:
DELETE FROM table_name WHERE column1 IS NULL AND column2 IS NULL AND column3 IS NULL;
Если задача состоит в удалении строк, где хотя бы один из нескольких столбцов содержит NULL, следует использовать оператор OR:
DELETE FROM table_name WHERE column1 IS NULL OR column2 IS NULL OR column3 IS NULL;
Важно учитывать, что для сложных запросов с множественными условиями могут понадобиться индексы на столбцы, содержащие NULL. Это поможет ускорить выполнение запроса, особенно при работе с большими объемами данных. Кроме того, всегда полезно делать предварительный SELECT-запрос для проверки, какие строки будут удалены:
SELECT * FROM table_name WHERE column1 IS NULL OR column2 IS NULL OR column3 IS NULL;
Если удаление строк с несколькими NULL необходимо выполнить только в определённых случаях, например, когда количество NULL превышает заданный порог, можно использовать более сложные выражения, такие как COUNT(NULL) в подзапросах или оконные функции, если это поддерживается базой данных.
Такие операции полезны для устранения «пустых» или неполных записей, которые могут искажать результаты анализа или отчетности. Однако следует помнить, что удаление данных без предварительного бэкапа может привести к потере важной информации, поэтому всегда рекомендуется тестировать запросы на небольших выборках перед их применением в реальной базе данных.
Использование COALESCE для подмены null перед фильтрацией
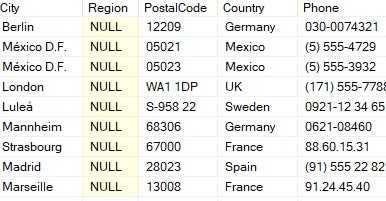
Функция COALESCE в SQL позволяет заменить значения NULL на заданное значение, что особенно полезно при фильтрации данных. Вместо того чтобы работать с NULL как с отдельным значением, можно заменить его на более подходящее для дальнейшей обработки. Это упрощает логику запроса и повышает производительность, так как позволяет избежать ненужных проверок на NULL в фильтрах.
Когда необходимо отфильтровать строки, содержащие NULL, применение COALESCE позволяет значительно упростить задачу. Например, если в таблице есть поле, где могут встречаться NULL значения, и нужно выбрать все записи, кроме NULL, можно использовать COALESCE для замены этих значений на специфическое значение, с которым можно работать.
Пример использования COALESCE перед фильтрацией:
SELECT * FROM employees WHERE COALESCE(salary, 0) > 50000;
В этом запросе NULL в столбце salary заменяется на 0, что позволяет правильно провести фильтрацию, не теряя записи с отсутствующими значениями. Это решение будет работать даже в случае, если в базе данных есть пустые записи в поле зарплаты, и их необходимо исключить из выборки.
COALESCE может быть полезна не только при фильтрации, но и при агрегации. Например, если нужно подсчитать сумму значений с заменой NULL на 0, функция COALESCE позволяет избежать ошибок в вычислениях:
SELECT SUM(COALESCE(salary, 0)) FROM employees;
Важно помнить, что использование COALESCE требует внимательности при выборе значения для замены NULL. Оно должно быть логично в контексте данных и задачи. Например, при фильтрации по датам или строкам использование произвольных значений может привести к искажению результатов.
Для более сложных случаев можно комбинировать COALESCE с другими функциями. Например, если нужно подменить NULL в зависимости от других условий, можно использовать вложенные функции COALESCE:
SELECT * FROM employees WHERE COALESCE(department_id, COALESCE(manager_id, 0)) > 100;
Такой подход позволяет гибко обрабатывать различные ситуации, когда нужно выбрать первое ненулевое значение из нескольких полей.
Удаление null с помощью оконных функций
Оконные функции в SQL позволяют эффективно обрабатывать данные по строкам, сохраняя при этом доступ к остальным данным в запросе. Когда необходимо заменить или удалить значения NULL, оконные функции могут предоставить гибкие и производительные решения.
Для замены NULL значений используется оконная функция COALESCE() в сочетании с OVER(), что позволяет работать с данными по группе строк без явной агрегации.
COALESCE()возвращает первое ненулевое значение среди переданных параметров. Это удобно для замены NULL на заданное значение.- Пример использования:
SELECT
COALESCE( column_name, 'Значение по умолчанию' ) OVER (PARTITION BY group_column) AS new_column
FROM table_name;
В этом примере, для каждой строки в пределах группы, если значение в column_name равно NULL, оно будет заменено на ‘Значение по умолчанию’. Для строк, где значение не NULL, будет возвращено само значение столбца.
Оконные функции помогают избежать дублирования значений при использовании PARTITION BY, что позволяет обрабатывать группы данных индивидуально. Это может быть полезно в случае работы с временными интервалами или категориями.
Для удаления NULL из набора данных можно использовать оконную функцию FIRST_VALUE() или LAST_VALUE(), чтобы взять первое или последнее ненулевое значение в пределах окна.
FIRST_VALUE()позволяет выбрать первое ненулевое значение по каждому окну.LAST_VALUE()аналогично работает с последним ненулевым значением.
Пример:
SELECT
FIRST_VALUE(column_name IGNORE NULLS) OVER (PARTITION BY group_column ORDER BY date_column) AS cleaned_column
FROM table_name;
В этом запросе, NULL значения в column_name будут заменяться первым ненулевым значением, учитывая сортировку по date_column.
Использование оконных функций для удаления или замены NULL позволяет избежать сложных подзапросов и улучшить производительность, особенно при работе с большими объемами данных. Это решение полезно в ситуациях, где необходимо учитывать контекст строк, например, для вычислений по времени или в пределах определенных групп.
Удаление дубликатов с null с использованием DISTINCT и ROW_NUMBER
Удаление дубликатов с учетом значений NULL – частая задача при работе с базами данных. Для эффективного решения этой проблемы можно использовать два основных инструмента: DISTINCT и ROW_NUMBER().
DISTINCT – оператор, который позволяет избавиться от повторяющихся строк в результате запроса. Однако, когда в столбцах присутствуют NULL значения, DISTINCT может не всегда работать так, как ожидается, поскольку NULL трактуется как уникальное значение. В результате, даже если столбцы содержат одинаковые NULL, они могут быть восприняты как разные. Это создаёт проблему, особенно когда нужно привести к одному значению все строки с NULL.
Для точного контроля над удалением дубликатов можно использовать ROW_NUMBER() в комбинации с оконными функциями. ROW_NUMBER() позволяет присваивать уникальный номер каждой строке в пределах определённой группы, что полезно для удаления дубликатов, включая те, где есть NULL значения.
Пример запроса, который помогает решить эту задачу:
WITH NumberedRows AS (
SELECT
column1, column2,
ROW_NUMBER() OVER (PARTITION BY column1 ORDER BY column2) AS rn
FROM your_table
)
SELECT column1, column2
FROM NumberedRows
WHERE rn = 1;Здесь ROW_NUMBER() присваивает номер строкам, группируя их по значению в column1, и сортирует их по column2. Строки с одинаковыми значениями будут иметь одинаковое значение в column1, но будут уникально идентифицированы через номер в rn. Далее, мы выбираем только строки с номером 1, что позволяет оставить только одну строку для каждой группы значений.
Такой подход позволяет эффективно удалять дубликаты, включая строки с NULL, сохраняя при этом гибкость в сортировке и фильтрации данных.