Повторяющиеся строки в результатах SQL-запросов чаще всего возникают из-за некорректных соединений таблиц, отсутствия фильтрации или неправильного выбора ключевых столбцов. Удаление дубликатов – задача не только эстетическая: она влияет на точность агрегаций, корректность бизнес-отчетности и производительность приложений.
Один из базовых способов устранения дублирования – использование ключевого слова DISTINCT. Оно подходит для простых случаев, когда требуется исключить полностью идентичные строки по всем столбцам. Однако DISTINCT неэффективен при работе с большими объемами данных, поскольку приводит к полной сортировке результата.
Если нужно удалить дубликаты по определённому набору столбцов, предпочтительнее использовать оконные функции, такие как ROW_NUMBER(). С их помощью можно идентифицировать избыточные строки и исключить их на уровне подзапроса. Например, в PostgreSQL или SQL Server это позволяет оставить только первую встречающуюся строку из группы, соответствующей условию уникальности.
В случаях, когда требуется физически удалить дубликаты из таблицы, а не только из результатов запроса, используются конструкции с подзапросами и CTE (Common Table Expressions). Они позволяют сначала пометить лишние строки с помощью оконной функции, а затем выполнить DELETE по условию ранжирования. Такой подход минимизирует риск удаления нужных данных и сохраняет контроль над процессом очистки.
Выбор метода зависит от контекста: логическое удаление при агрегации, временное исключение из выборки или физическое удаление из таблицы. Универсального решения нет, но понимание причин появления дубликатов и инструментов SQL – ключ к корректной и производительной работе с данными.
Как использовать DISTINCT для удаления полных дубликатов
Ключевое слово DISTINCT позволяет исключить повторяющиеся строки, если они полностью идентичны по всем выбранным полям. Это наиболее простой способ устранить дубликаты при выборке данных.
- Синтаксис:
SELECT DISTINCT column1, column2, ... FROM table_name; - Убедитесь, что перечислены только те столбцы, по которым требуется сравнение. Если хотя бы одно значение отличается, строка не считается дубликатом.
SELECT DISTINCT * FROM table_name;исключает только полностью одинаковые строки, включая все поля, даже служебные (например, идентификаторы или временные метки).- При использовании
DISTINCTсJOINилиGROUP BYпроверяйте, не вносят ли они неочевидные различия, приводящие к сохранению дубликатов. - Производительность
DISTINCTможет снижаться на больших объемах данных из-за необходимости сортировки и удаления повторов. Оптимизируйте индексы по полям, участвующим в запросе.
Используйте DISTINCT только при уверенности, что поля в выборке достаточны для определения уникальности. В противном случае дубликаты сохранятся, и потребуется дополнительная фильтрация.
Удаление дубликатов с помощью группировки и агрегатных функций
Группировка по нужным столбцам позволяет оставить только уникальные комбинации значений. Например, чтобы исключить повторяющиеся записи по полям name и email, используйте конструкцию:
SELECT name, email FROM users GROUP BY name, email;
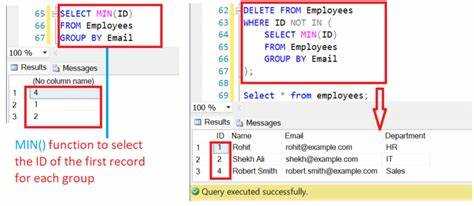
Если необходимо сохранить дополнительные поля, например id или created_at, используйте агрегатные функции. Чтобы выбрать запись с минимальным идентификатором для каждой уникальной пары name и email, выполните:
SELECT MIN(id) AS id, name, email FROM users GROUP BY name, email;
Аналогично можно применять MAX(), COUNT(), SUM() или AVG() в зависимости от задачи. Если нужно получить самую позднюю дату создания для каждой группы, подойдет:
SELECT name, email, MAX(created_at) AS last_created FROM users GROUP BY name, email;
Важно: при использовании GROUP BY все поля, не обернутые агрегатными функциями, должны быть указаны в списке группировки. Иначе запрос вызовет ошибку или вернет непредсказуемый результат.
Применение подзапроса с ROW_NUMBER для удаления повторяющихся строк
Функция ROW_NUMBER() позволяет пронумеровать строки в пределах логически разделённых групп, определённых через PARTITION BY. Это удобно, когда необходимо сохранить только одну строку из каждой группы дубликатов.
Для удаления повторов, нужно сначала определить критерии дублирования. Например, если строки считаются дубликатами по полям email и created_at, создаётся подзапрос с ROW_NUMBER(), где каждая группа идентичных значений получает свой порядок.
Пример:
WITH RankedRows AS (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY email, created_at ORDER BY id) AS rn
FROM users
)
DELETE FROM users
WHERE id IN (
SELECT id FROM RankedRows WHERE rn > 1
);Здесь подзапрос RankedRows определяет дубликаты по email и created_at, сохраняя только первую строку в каждой группе (где rn = 1). Все остальные (где rn > 1) попадают в подзапрос удаления.
Важно: ORDER BY внутри OVER() должен быть по уникальному или полу-уникальному столбцу (например, id), чтобы однозначно определить, какая из строк считается «первой». Без этого результат будет непредсказуемым.
Такой подход не только эффективен, но и безопасен – он не требует временных таблиц и работает во всех современных СУБД, включая PostgreSQL, SQL Server и Oracle.
Удаление дубликатов по одной или нескольким колонкам с использованием CTE

Для удаления дубликатов по одной или нескольким колонкам эффективно применять обобщённые табличные выражения (CTE) с функцией ROW_NUMBER(). Это позволяет сохранить только одну строку из каждой группы дубликатов, определяемой набором полей.
Рассмотрим пример, где требуется удалить дубликаты по колонкам email и created_at из таблицы users. Допустим, необходимо оставить первую запись по дате создания:
WITH ranked_users AS (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY email, created_at ORDER BY id) AS rn
FROM users
)
DELETE FROM users
WHERE id IN (
SELECT id FROM ranked_users WHERE rn > 1
);Ключевые моменты:
PARTITION BYопределяет, по каким полям считается уникальность;ORDER BYуправляет приоритетом выбора строки, которую нужно сохранить;rn > 1отбирает все дубликаты, кроме первой строки в группе;- Удаление происходит по
id, чтобы избежать повторного чтения из исходной таблицы.
Для дубликатов по одной колонке (например, только email) синтаксис аналогичен:
WITH ranked_users AS (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY email ORDER BY id) AS rn
FROM users
)
DELETE FROM users
WHERE id IN (
SELECT id FROM ranked_users WHERE rn > 1
);Важно: перед удалением рекомендуется выполнить SELECT * FROM ranked_users WHERE rn > 1 для проверки правильности отбора строк. Это предотвращает случайное удаление нужных данных.
Различия между DISTINCT и GROUP BY при работе с дубликатами
DISTINCT используется исключительно для удаления повторяющихся строк из результирующего набора. Он не предоставляет возможности выполнять агрегатные вычисления. Применение DISTINCT эффективно, если цель – получить уникальные комбинации значений без дополнительной обработки.
GROUP BY группирует строки по указанным столбцам и часто используется совместно с агрегатными функциями: COUNT(), SUM(), AVG() и другими. Если агрегатные функции не используются, результат может быть аналогичен DISTINCT, но производительность будет ниже из-за дополнительных операций группировки.
Например, SELECT DISTINCT city FROM customers и SELECT city FROM customers GROUP BY city вернут одинаковый результат, но первый вариант работает быстрее и проще читается. Однако если требуется посчитать количество клиентов в каждом городе, GROUP BY незаменим: SELECT city, COUNT(*) FROM customers GROUP BY city.
Если в запросе используются неагрегатные столбцы, не указанные в GROUP BY, это приведёт к ошибке или неопределённому поведению. DISTINCT в этом плане более гибкий, так как не требует указания всех столбцов в определённом порядке.
Использование DISTINCT оправдано при простом исключении дубликатов. GROUP BY применяется, когда нужно агрегировать данные или готовить их для дальнейшего анализа. Выбор зависит от задачи и структуры запроса.
Как удалить дубликаты с сохранением строки с минимальным или максимальным значением
В случае работы с дубликатами строк в базе данных часто требуется сохранить не все записи, а только одну – с минимальным или максимальным значением по определенному столбцу. Для этого можно использовать несколько подходов в SQL-запросах.
Основной метод заключается в использовании подзапросов или оконных функций для выбора уникальных строк с нужным значением. Рассмотрим основные способы удаления дубликатов с сохранением строки с минимальным или максимальным значением.
Использование оконных функций
Если ваша СУБД поддерживает оконные функции (например, PostgreSQL, SQL Server, MySQL 8.0 и выше), можно использовать функцию ROW_NUMBER(), которая позволяет нумеровать строки в пределах каждой группы, а затем удалить все строки, кроме нужной.
WITH Ranked AS ( SELECT *, ROW_NUMBER() OVER (PARTITION BY column_to_check ORDER BY column_with_min_or_max_value DESC) AS rn FROM your_table ) DELETE FROM your_table WHERE id IN ( SELECT id FROM Ranked WHERE rn > 1 );
В данном запросе PARTITION BY делит данные на группы по столбцу с потенциальными дубликатами. Далее, с помощью ORDER BY, выбирается строка с максимальным значением по нужному столбцу (если нужно минимальное, меняем порядок на ASC). После этого строки с порядковым номером > 1 удаляются.
Использование подзапросов
Если ваша СУБД не поддерживает оконные функции, можно обойтись подзапросом с агрегатными функциями. В этом случае мы выбираем минимальные или максимальные значения и исключаем дубликаты, сравнив значения в основной таблице с результатами подзапроса.
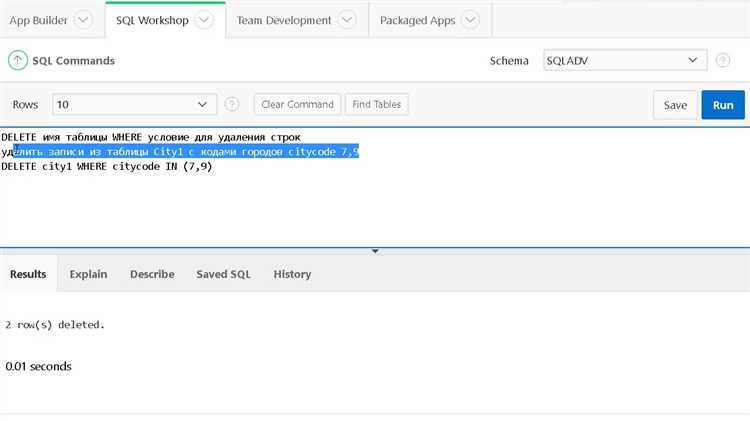
DELETE FROM your_table WHERE id NOT IN ( SELECT MIN(id) FROM your_table GROUP BY column_to_check );
Этот запрос удаляет все строки, кроме той, у которой минимальный id в группе дубликатов, определяемых по столбцу column_to_check. Для сохранения строки с максимальным значением можно заменить MIN(id) на MAX(id).
Использование DISTINCT ON (PostgreSQL)
 (пока оценок нет)
(пока оценок нет)