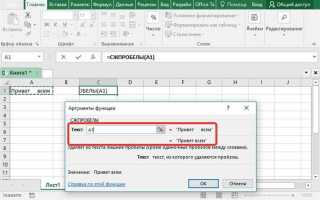
Наличие лишних пробелов в строковых данных может нарушать сортировку, влиять на точность фильтрации и мешать корректной агрегации. В SQL для удаления пробелов применяются встроенные строковые функции, которые позволяют избавиться как от пробелов в начале и конце строки, так и от всех пробелов внутри строки.
Для удаления пробелов по краям строки используется функция TRIM(). Она актуальна во всех основных диалектах SQL. Пример: SELECT TRIM(‘ текст ‘) вернёт ‘текст’. В MySQL и PostgreSQL можно также указывать, какие именно символы удалять: TRIM(BOTH FROM ‘—текст—‘).
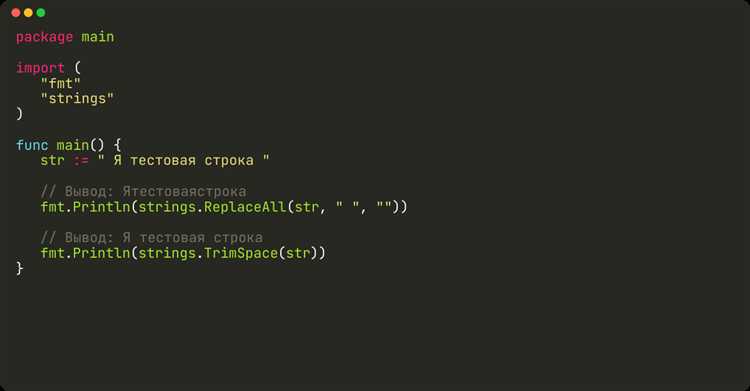
Чтобы удалить все пробелы внутри строки, используется комбинация REPLACE(). Пример: SELECT REPLACE(‘т е к с т’, ‘ ‘, ») преобразует строку в ‘текст’. В SQL Server и Oracle подход аналогичный.
Если требуется убрать только ведущие или только завершающие пробелы, применяются LTRIM() и RTRIM(). Они доступны в большинстве систем управления базами данных, включая SQL Server, PostgreSQL и Oracle. Например: LTRIM(‘ текст’) вернёт ‘текст’, а RTRIM(‘текст ‘) – ‘текст’.
Для регулярной очистки данных на уровне всей таблицы используется обновление через UPDATE с вложенными функциями. Пример для PostgreSQL: UPDATE table_name SET column_name = REPLACE(TRIM(column_name), ‘ ‘, »).
Удаление пробелов в начале и в конце строки с помощью TRIM()
Функция TRIM() удаляет лишние символы с обеих сторон строки. По умолчанию удаляются пробелы. В SQL это полезно при очистке данных, поступающих из внешних источников.
- Синтаксис:
TRIM([LEADING | TRAILING | BOTH] [удаляемый_символ] FROM строка) - Без параметров:
TRIM(строка)– удаляет пробелы в начале и в конце строки. - Пример:
SELECT TRIM(' example ');– вернёт'example'. - Для явного указания направления:
TRIM(LEADING FROM строка)– удаляет только в началеTRIM(TRAILING FROM строка)– удаляет только в конце
Если нужно удалить не пробел, а конкретный символ, его указывают явно:
SELECT TRIM(BOTH 'x' FROM 'xxxabcxxx');Результат: 'abc'.
TRIM() поддерживается большинством СУБД: PostgreSQL, MySQL, SQL Server (частично через LTRIM()/RTRIM()), Oracle. При кросс-платформенной разработке важно учитывать различия в синтаксисе.
- В PostgreSQL: полная поддержка
TRIM()по стандарту SQL. - В SQL Server: используйте
LTRIM(RTRIM(строка))для аналогичного результата.
Как убрать все пробелы внутри строки при помощи REPLACE()
Функция REPLACE() в SQL позволяет заменить все вхождения одного подстрочного значения другим. Для удаления всех пробелов из строки её применяют так:
SELECT REPLACE(строка, ' ', '') AS строка_без_пробелов FROM таблица;
Этот запрос проходит по каждому символу строки и убирает все пробелы, включая те, что находятся внутри текста, а не только в начале или в конце. Например, строка 'текст с пробелами' превращается в 'текстспробелами'.
Функция REPLACE() нечувствительна к положению символа в строке и заменяет абсолютно все вхождения указанного символа. При необходимости обработки только части строки используйте REPLACE() в сочетании с другими функциями, такими как SUBSTRING().
Если в базе хранятся строки с неразрывными пробелами (например, CHAR(160)), их следует удалять отдельно: REPLACE(REPLACE(строка, CHAR(160), ''), ' ', '').
Использование REGEXP_REPLACE для удаления лишних пробелов между словами
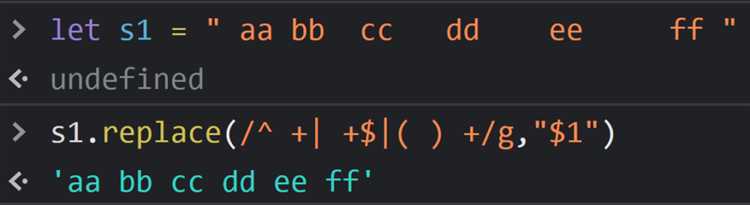
Функция REGEXP_REPLACE применяется для устранения последовательных пробелов, оставляя один пробел между словами. Это особенно полезно при очистке данных, импортированных из внешних источников, где форматирование может быть нарушено.
Пример для Oracle:
SELECT REGEXP_REPLACE('текст с лишними пробелами', '\s{2,}', ' ') AS результат FROM dual;
Регулярное выражение \s{2,} указывает на два и более подряд идущих пробела. Все такие последовательности заменяются на одиночный пробел.
Для PostgreSQL синтаксис аналогичен, но функция вызывается иначе:
SELECT REGEXP_REPLACE('пример с пробелами', '\s{2,}', ' ', 'g');
Флаг 'g' означает глобальную замену по всей строке. Без него будет заменена только первая подходящая последовательность.
Важно: \s включает в себя пробелы, табуляции и символы новой строки. Для точечной работы только с пробелами используйте ' {2,}'.
При необходимости удалить пробелы также в начале и в конце строки, добавьте второй вызов TRIM или вложите REGEXP_REPLACE:
SELECT TRIM(REGEXP_REPLACE(' строка с пробелами ', '\s{2,}', ' ')) AS очищено;
Удаление невидимых пробельных символов в данных из внешних источников
Данные, поступающие из внешних систем, часто содержат невидимые символы: non-breaking space (U+00A0), табуляции (U+0009), символы возврата каретки (U+000D), перевода строки (U+000A), а также нулевой пробел (U+200B) и управляющие символы в диапазоне U+0000–U+001F. Они не отображаются при просмотре, но влияют на фильтрацию, агрегацию и сравнение строк.
Для удаления таких символов в SQL используйте выражение с функцией REPLACE в сочетании с TRIM и REGEXP_REPLACE (если поддерживается вашей СУБД). В PostgreSQL можно применить:
REGEXP_REPLACE(column_name, ‘[\u0000-\u001F\u00A0\u200B]’, », ‘g’)
В Oracle используйте:
REGEXP_REPLACE(column_name, ‘[[:cntrl:]]|\xA0|\x{200B}’, »)
В SQL Server начиная с версии 2022 доступна функция TRANSLATE, но для удаления скрытых символов лучше комбинировать REPLACE:
REPLACE(REPLACE(REPLACE(column_name, CHAR(160), »), CHAR(9), »), CHAR(8203), »)
В MySQL начиная с версии 8.0 доступен REGEXP_REPLACE:
REGEXP_REPLACE(column_name, ‘[\x{00}-\x{1F}\x{A0}\x{200B}]’, »)
Перед импортом данных из CSV, JSON или XML рекомендуется выполнять предобработку на стороне скрипта (например, на Python), удаляя проблемные символы через регулярные выражения или фильтрацию по Unicode-категориям.
Использование CHAR() с указанием конкретного кода символа помогает точно удалить нежелательные символы, особенно если источник нестандартизирован. Проверку содержимого можно автоматизировать с помощью регулярных выражений или функций подсчета длины до и после очистки.
Как обрабатывать строки с множественными пробелами в середине
SQL не предлагает встроенной функции для сжатия последовательных пробелов в середине строки до одного, но задачу можно решить через комбинацию функций. Пример ниже демонстрирует способ устранения лишних пробелов между словами:
SELECT REGEXP_REPLACE(строка, '\s{2,}', ' ') AS очищенная_строка
FROM таблица;REGEXP_REPLACE– функция, поддерживаемая в PostgreSQL, Oracle, Snowflake, BigQuery и других СУБД с поддержкой регулярных выражений.\s{2,}– регулярное выражение, указывающее на два и более подряд идущих пробела или других пробельных символов (включая табуляции и переносы строк).' '– замена всей последовательности пробелов на один пробел.
Если используется Microsoft SQL Server, регулярные выражения напрямую не поддерживаются, но можно использовать вложенные вызовы REPLACE:
WHILE CHARINDEX(' ', @строка) > 0
SET @строка = REPLACE(@строка, ' ', ' ');- Этот подход итеративно заменяет двойные пробелы, пока они не исчезнут.
- Рекомендуется для небольших объемов данных, поскольку он неэффективен при работе с большими наборами строк.
В MySQL используйте:
SELECT REGEXP_REPLACE(строка, '[ ]{2,}', ' ') AS результат
FROM таблица;- Начиная с версии 8.0.4 поддерживается
REGEXP_REPLACE. - Символ пробела в квадратных скобках исключает замену табуляций – при необходимости регулярное выражение можно адаптировать.
После удаления лишних пробелов целесообразно также убрать пробелы в начале и в конце строки:
SELECT TRIM(REGEXP_REPLACE(строка, '\s{2,}', ' ')) FROM таблица;Объединение этих приемов обеспечивает компактное и единообразное форматирование строк.
Удаление пробелов в строках при обновлении таблицы
В SQL часто требуется очистить строки от лишних пробелов, например, при обновлении данных в таблице. Для этого можно использовать функцию REPLACE(), которая позволяет заменить пробелы на пустые строки, или TRIM(), которая удаляет пробелы с начала и конца строки.
Для обновления записей в таблице с удалением пробелов внутри строк используйте запрос следующего вида:
UPDATE таблица
SET колонка = REPLACE(колонка, ' ', '')
WHERE колонка LIKE '% %';Этот запрос заменяет все пробелы в строках указанной колонки на пустые строки. Убедитесь, что в условии WHERE используется проверка на наличие пробела, чтобы обновить только те записи, которые содержат пробелы.
Если задача заключается в удалении пробелов только с начала и конца строки, используйте TRIM():
UPDATE таблица
SET колонка = TRIM(колонка)
WHERE колонка LIKE ' %' OR колонка LIKE '% ';Этот запрос удаляет пробелы только с краев строки, оставляя внутренние пробелы неизменными. Для более сложных манипуляций с пробелами в строках можно комбинировать REPLACE() и TRIM() в зависимости от требований задачи.
Если необходимо удалить пробелы только между определёнными словами, уточните регулярное выражение или используйте дополнительные функции, такие как REGEXP_REPLACE(), доступные в некоторых СУБД, например, в PostgreSQL.
Всегда проверяйте результат изменений с помощью SELECT-запросов перед массовым обновлением, чтобы избежать ошибок и потери данных.
Удаление пробелов в выборке без изменения исходных данных
Для удаления пробелов в строках, не влияя на исходные данные в базе, можно использовать функцию TRIM, которая удаляет пробелы только в результате выборки. Это особенно полезно, когда необходимо провести анализ или подготовку данных, не изменяя их в базе данных.
Чтобы удалить начальные и конечные пробелы в строках, можно применить следующий запрос:
SELECT TRIM(имя_столбца) FROM таблица;
Этот метод удаляет пробелы по краям строки, но не влияет на пробелы внутри текста.
Для удаления всех пробелов из строки, независимо от их расположения, можно использовать функцию REPLACE:
SELECT REPLACE(имя_столбца, ' ', '') FROM таблица;
Этот запрос удалит все пробелы, как в начале, так и в середине строки. Такой подход позволяет быстро очистить данные в выборке, не вмешиваясь в сами записи в таблице.
Если задача заключается в удалении пробелов только изначальных или конечных, но без трогания пробелов между словами, то предпочтительнее использовать TRIM, а для полной очистки строки – REPLACE.
Особое внимание стоит уделить производительности при работе с большими объемами данных. В случае значительных объемов строк, использование REPLACE может замедлить выполнение запросов. В таких случаях рекомендуется ограничить выборку с помощью WHERE или индексов, чтобы минимизировать нагрузку на сервер.