

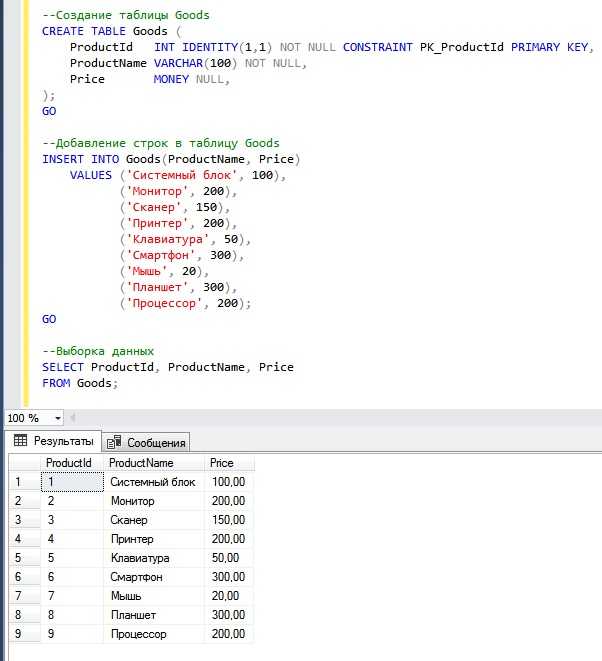
Создание счетчика в SQL – важная задача для управления уникальными значениями, такими как идентификаторы записей или количество действий пользователя. Один из простых способов реализации – использование последовательностей (sequences) или автоинкрементируемых столбцов, в зависимости от требований к проекту и СУБД.
Автоинкрементируемые столбцы являются наиболее распространённым методом для создания уникальных значений. Для этого можно воспользоваться атрибутом AUTO_INCREMENT в MySQL или SERIAL в PostgreSQL. Этот подход идеально подходит для сценариев, где необходимо автоматически увеличивать значение при вставке новой записи.
Пример создания автоинкрементируемого столбца в MySQL:
CREATE TABLE users ( id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(100) );
Для более сложных случаев, когда необходимо управлять значением счетчика вручную, используйте последовательности. Они обеспечивают большую гибкость, так как позволяют контролировать начальное значение, шаг инкремента и другие параметры.
Пример создания последовательности в PostgreSQL:
CREATE SEQUENCE user_id_seq START WITH 1 INCREMENT BY 1;
Затем последовательность можно использовать для задания значений в других таблицах:
INSERT INTO users (id, name)
VALUES (nextval('user_id_seq'), 'Иван');
Счетчики в SQL дают возможность точно контролировать уникальные идентификаторы, улучшая управление данными и повышая производительность системы. Использование правильного метода зависит от конкретных требований вашего проекта и выбранной СУБД.
Создание простого счетчика с использованием функции COUNT()

Функция COUNT() в SQL позволяет подсчитать количество строк в таблице, соответствующих заданным критериям. Для простого подсчета всех записей в таблице можно использовать запрос вида:
SELECT COUNT(*) FROM имя_таблицы;
Этот запрос вернет количество всех строк в таблице, независимо от их содержимого. Однако часто требуется подсчитать количество строк с определенными условиями. Для этого используется условие WHERE:
SELECT COUNT(*) FROM имя_таблицы WHERE условие;
Например, чтобы посчитать количество заказов, сделанных определенным клиентом, можно использовать следующий запрос:
SELECT COUNT(*) FROM заказы WHERE id_клиента = 1;
Для подсчета уникальных значений в столбце используется COUNT с DISTINCT. Например, для подсчета уникальных клиентов в заказах:
SELECT COUNT(DISTINCT id_клиента) FROM заказы;
Функция COUNT() эффективна и при работе с большими объемами данных, так как оптимизируется для подсчета строк. Однако для фильтрации данных всегда важно правильно использовать индексы и учитывать особенности структуры базы данных.
Как подсчитать количество уникальных значений в столбце
Для подсчета уникальных значений в столбце в SQL используется оператор COUNT(DISTINCT). Этот метод позволяет получить количество различных записей в указанном столбце, исключая повторяющиеся значения.
Простой пример запроса:
SELECT COUNT(DISTINCT column_name) FROM table_name;В этом примере column_name – это имя столбца, а table_name – название таблицы, из которой будет производиться подсчет уникальных значений. Запрос вернет число, отражающее количество различных значений в столбце.
Если необходимо подсчитать уникальные значения с дополнительными условиями, можно использовать оператор WHERE. Например, для подсчета уникальных значений в столбце, где значения больше 10:
SELECT COUNT(DISTINCT column_name) FROM table_name WHERE column_name > 10;Также стоит помнить, что COUNT(DISTINCT) работает не только для текстовых и числовых данных, но и для других типов, таких как даты или логические значения.
Важно учитывать, что использование COUNT(DISTINCT) может повлиять на производительность запросов, особенно если таблица содержит большое количество строк. В таких случаях рекомендуется использовать индексы на столбце для ускорения выполнения запроса.
Подсчет уникальных значений в нескольких столбцах осуществляется так:
SELECT COUNT(DISTINCT column1, column2) FROM table_name;Этот запрос вернет количество уникальных комбинаций значений в двух столбцах. Метод работает аналогично для большего числа столбцов.
Реализация автонумерации записей с помощью ID
Для автоматического назначения уникальных идентификаторов в базе данных используется механизм автонумерации. Он позволяет избежать дублирования значений и гарантирует, что каждый новый элемент получает уникальный номер без необходимости вручную указывать ID.
Для создания автонумерации в SQL наиболее часто применяют тип данных, поддерживающий автоинкремент. В MySQL это будет тип INT AUTO_INCREMENT, а в PostgreSQL — SERIAL. В других СУБД могут использоваться аналогичные методы.
Пример для MySQL:
CREATE TABLE users ( id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(100), email VARCHAR(100) );
В данном примере поле id будет автоматически увеличиваться при добавлении новой записи. При вставке данных не нужно указывать значение для поля id; оно будет присвоено автоматически.
Пример для PostgreSQL:
CREATE TABLE users ( id SERIAL PRIMARY KEY, name VARCHAR(100), email VARCHAR(100) );
В PostgreSQL поле id также автоматически увеличивается с помощью типа SERIAL, который представляет собой комбинацию INTEGER и последовательности.
Если требуется использовать другую логику для нумерации, например, начинать с определенного числа или использовать определенный шаг, это можно настроить с помощью последовательностей. Например, в PostgreSQL:
CREATE SEQUENCE user_id_seq START 1000;
CREATE TABLE users (
id INT DEFAULT nextval('user_id_seq'),
name VARCHAR(100),
email VARCHAR(100)
);
В этом примере последовательность начинается с 1000 и увеличивается на 1 при каждом добавлении новой записи.
Также стоит учитывать, что автонумерация работает только в рамках одной таблицы. Если записи из разных таблиц должны иметь уникальные ID на уровне всей базы данных, придется использовать дополнительную логику для их генерации, например, с помощью глобальных последовательностей или комбинированных ключей.
Использование переменных для создания счетчиков в SQL
В SQL переменные позволяют последовательно присваивать значения строкам выборки, имитируя поведение счётчика. Это особенно полезно при отсутствии встроенной функции ROW_NUMBER(), например, в MySQL до версии 8.0.
- Для MySQL (до 8.0) счётчик можно реализовать с помощью пользовательской переменной:
SELECT
@row := @row + 1 AS счетчик,
t.*
FROM
таблица t,
(SELECT @row := 0) r;
- Переменная
@rowинициализируется до начала основной выборки. - Инкремент происходит во время чтения каждой строки.
- Порядок может быть непредсказуемым без
ORDER BY. Для надёжности добавляй сортировку:
SELECT
@row := @row + 1 AS счетчик,
t.*
FROM
(SELECT * FROM таблица ORDER BY дата_создания) t,
(SELECT @row := 0) r;
- В PostgreSQL переменные не поддерживаются напрямую. Аналогичную задачу решает
ROW_NUMBER(). - В SQL Server можно использовать переменные внутри курсора, но предпочтительнее применять оконные функции.
Переменные в MySQL чувствительны к контексту исполнения. Вложенные подзапросы, агрегаты и соединения могут повлиять на ожидаемое поведение. Избегай их при использовании счётчиков на переменных.
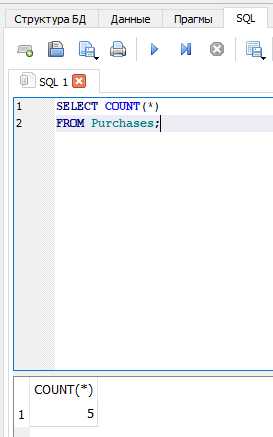
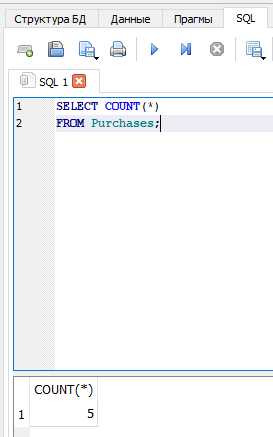
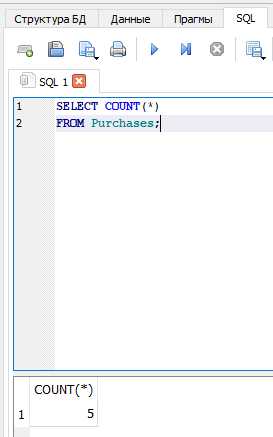
Создание счетчика с учетом условий фильтрации
Чтобы посчитать количество строк, соответствующих определённым условиям, используйте конструкцию COUNT(*) с оператором WHERE. Это позволяет получить точное количество записей, отвечающих заданным критериям.
SELECT COUNT(*) FROM заказы WHERE статус = 'доставлен';– подсчёт доставленных заказов.SELECT COUNT(*) FROM пользователи WHERE дата_регистрации >= '2025-01-01';– количество пользователей, зарегистрированных с начала года.
Если нужно сгруппировать данные и подсчитать количество по каждой категории, используется GROUP BY.
SELECT статус, COUNT(*) FROM заказы GROUP BY статус;– количество заказов по каждому статусу.
Чтобы фильтровать уже сгруппированные данные, добавляется HAVING:
SELECT клиент_id, COUNT(*) FROM заказы GROUP BY клиент_id HAVING COUNT(*) > 5;– клиенты с более чем пятью заказами.
Если требуется подсчёт уникальных значений, применяется COUNT(DISTINCT ...):
SELECT COUNT(DISTINCT клиент_id) FROM заказы WHERE дата >= '2025-01-01';– число уникальных клиентов с начала года.
Фильтрацию по нескольким условиям реализуют с помощью AND и OR:
SELECT COUNT(*) FROM заказы WHERE статус = 'доставлен' AND дата BETWEEN '2025-01-01' AND '2025-03-31';
Для повторяющихся фильтров создавайте представления или подзапросы:
SELECT COUNT(*) FROM (SELECT * FROM заказы WHERE регион = 'Сибирь') AS z;
Как использовать оконные функции для создания сложных счетчиков
Оконные функции позволяют вычислять счетчики без агрегации строк. Это особенно полезно, когда требуется сохранить все строки результата и при этом посчитать, например, порядковый номер внутри группы или накопительный итог.
Для присвоения номера строке в пределах определённой группы используется функция ROW_NUMBER(). Пример: нумерация заказов по каждому клиенту:
SELECT client_id, order_id, ROW_NUMBER() OVER (PARTITION BY client_id ORDER BY order_date) AS order_rank FROM orders;
Если требуется накопительный счетчик, используется SUM() как оконная функция. Например, подсчет общей суммы заказов клиента с начала взаимодействия:
SELECT client_id, order_date, amount, SUM(amount) OVER (PARTITION BY client_id ORDER BY order_date) AS cumulative_total FROM orders;
Функция COUNT() через окно позволяет учитывать повторяющиеся значения. Пример – подсчет количества покупок нарастающим итогом в течение месяца:
SELECT client_id, order_date, COUNT(*) OVER (PARTITION BY client_id ORDER BY order_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS purchase_count FROM orders;
Для ограничения окна можно применять рамки. Например, подсчет количества событий за последние 7 дней по дате:
SELECT event_id, event_date, COUNT(*) OVER (ORDER BY event_date RANGE BETWEEN INTERVAL 6 DAY PRECEDING AND CURRENT ROW) AS last_week_events FROM events;
Комбинируя различные оконные функции, можно создавать вложенные счетчики, сравнивать текущие значения с предыдущими (LAG(), LEAD()) и рассчитывать интервалы между событиями. Это позволяет анализировать поведение пользователей, скорость обработки заявок или цикличность продаж без удаления строк и группировок.
Пример инкремента счетчика при вставке новых данных
Для автоматического увеличения счётчика при добавлении записей удобно использовать автоинкрементное поле. Пример ниже показывает создание таблицы и вставку данных с использованием такого механизма в PostgreSQL.
CREATE TABLE users (
id SERIAL PRIMARY KEY,
username TEXT NOT NULL
);
INSERT INTO users (username) VALUES
('ivan'),
('petr'),
('olga');
Поле id автоматически увеличивается с каждой новой записью. Тип SERIAL создаёт последовательность и связывает её с полем. Проверить результат:
SELECT * FROM users;Результат запроса:
| id | username |
|---|---|
| 1 | ivan |
| 2 | petr |
| 3 | olga |
В MySQL используется AUTO_INCREMENT:
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(255) NOT NULL
);
Аналогично, поле id будет увеличиваться без явного указания значения при вставке. Такой подход гарантирует уникальность счётчика без дополнительных запросов и блокировок.
Влияние индексов на работу счетчиков в больших таблицах
При подсчёте строк с помощью COUNT(*) в больших таблицах наличие индексов может существенно повлиять на скорость выполнения запроса. Если столбец, участвующий в условии фильтрации, проиндексирован, СУБД может использовать индекс для обхода нужных строк, минуя полное сканирование таблицы.
Например, запрос SELECT COUNT(*) FROM orders WHERE status = ‘shipped’ при наличии индекса по status может обойтись чтением только индексных страниц. Это особенно заметно при миллионах записей. Без индекса СУБД будет вынуждена сканировать каждую строку, что значительно увеличит нагрузку.
Индекс по NULLABLE-столбцам требует осторожности: COUNT(column) учитывает только ненулевые значения. Индексы, исключающие NULL, могут ускорить такой запрос, но не подойдут, если требуется учитывать все записи.
Сложные счетчики с группировкой, например COUNT(*) GROUP BY customer_id, выигрывают от композитных индексов, где первый столбец – customer_id. Это снижает количество обращений к диску и ускоряет агрегацию.
Однако чрезмерное количество индексов замедляет вставку и обновление данных. Для счётчиков, запускаемых регулярно, лучше использовать покрывающие индексы – они содержат все необходимые столбцы для выполнения запроса, исключая обращение к основной таблице.
Использование partial indexes также может быть полезным. Например, если нужно считать только завершённые заказы, индекс только по строкам с status = ‘completed’ снизит объём данных и ускорит выборку.
Для аналитических задач применимы bitmap-индексы (в СУБД, где они поддерживаются), особенно при подсчётах по столбцам с малой кардинальностью. Они показывают высокую эффективность при агрегировании.





