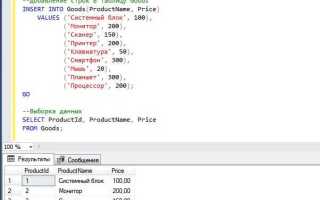
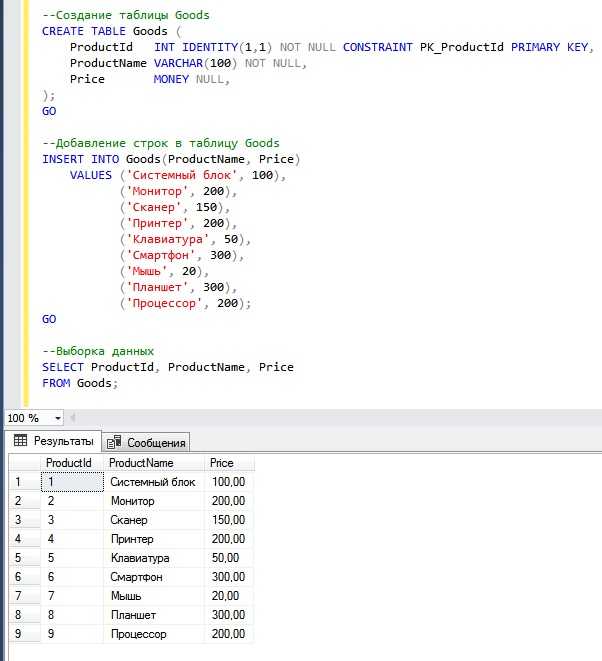
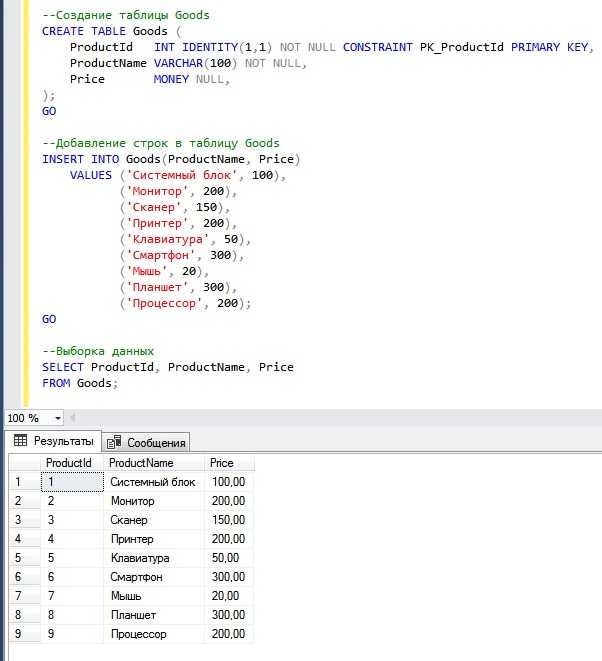
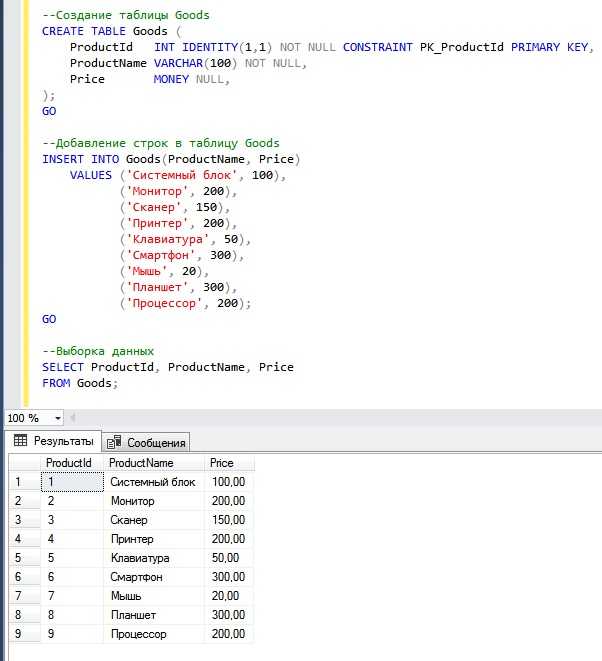
Повторяющиеся строки в базе данных могут возникать по множеству причин: ошибки при импорте данных, сбои в логике приложения, нарушения ограничений уникальности. Такие дубликаты приводят к неточным результатам аналитики, избыточному использованию хранилища и снижению производительности запросов. Оптимизация выборки и чистка таблиц – неотъемлемая часть работы с SQL.
Для удаления дубликатов чаще всего используется конструкция ROW_NUMBER() в сочетании с CTE (Common Table Expression). Она позволяет точно определить повторяющиеся записи, оставляя только одну – по определённому критерию, например, самой ранней или последней дате создания. Пример:
WITH CTE AS (
SELECT *, ROW_NUMBER() OVER (PARTITION BY email ORDER BY created_at DESC) AS rn
FROM users
)
DELETE FROM CTE WHERE rn > 1;
Функции DISTINCT и GROUP BY подходят только для выборки без дубликатов, но не для их удаления. Использование JOIN на подзапрос с агрегатами также допустимо, однако менее эффективно при больших объёмах данных.
Важно учитывать наличие первичных ключей и связей с другими таблицами: при удалении строк возможны нарушения ссылочной целостности. Поэтому перед очисткой дубликатов рекомендуется использовать SELECT COUNT(*) и проверять уникальность по ключевым столбцам. Пример запроса для аудита:
SELECT email, COUNT(*)
FROM users
GROUP BY email
HAVING COUNT(*) > 1;
Как найти дубликаты строк с помощью GROUP BY и HAVING
Для выявления дубликатов в таблице применяются операторы GROUP BY и HAVING, позволяющие сгруппировать строки по выбранным столбцам и отфильтровать группы, содержащие более одной записи. Это особенно полезно при анализе данных, где требуется точно определить повторяющиеся значения по определённому критерию.
Пример запроса для нахождения дубликатов по столбцам email и username:
SELECT email, username, COUNT(*) AS count
FROM users
GROUP BY email, username
HAVING COUNT(*) > 1;
Этот запрос возвращает только те сочетания email и username, которые встречаются более одного раза. Использование COUNT(*) в сочетании с HAVING позволяет исключить уникальные строки и сосредоточиться исключительно на повторениях.
Для анализа повторов по одному столбцу, например phone_number, структура запроса остаётся аналогичной:
SELECT phone_number, COUNT(*) AS count
FROM contacts
GROUP BY phone_number
HAVING COUNT(*) > 1;
Важно, чтобы в GROUP BY были указаны только те поля, по которым необходимо определить дубликаты. Добавление лишних столбцов нарушит агрегацию и приведёт к неверным результатам.
Для получения идентификаторов всех строк-дубликатов можно использовать вложенный запрос:
SELECT *
FROM orders
WHERE (customer_id, product_id) IN (
SELECT customer_id, product_id
FROM orders
GROUP BY customer_id, product_id
HAVING COUNT(*) > 1
);
Такой подход позволяет не только выявить дубликаты, но и работать с полными строками, например, для последующего удаления или обновления.
Удаление полных дубликатов с помощью DISTINCT
Оператор SELECT DISTINCT возвращает только уникальные строки результата, полностью исключая повторяющиеся. Это наиболее эффективный способ устранения полных дубликатов без удаления данных из таблицы.
Пример запроса, выбирающего уникальные строки из таблицы employees:
SELECT DISTINCT first_name, last_name, department_id
FROM employees;
Важно: DISTINCT сравнивает значения по всем указанным в SELECT столбцам. Если даже одно значение отличается – строка считается уникальной. Чтобы исключить только абсолютно одинаковые строки, необходимо перечислить все столбцы таблицы:
SELECT DISTINCT *
FROM employees;
Такой подход особенно полезен при анализе импортированных данных, где могут дублироваться целые записи. Однако DISTINCT не влияет на физические данные в таблице – он лишь фильтрует результат запроса. Для удаления дубликатов на уровне таблицы необходимо использовать DELETE с подзапросом или CTE.
Рекомендуется использовать DISTINCT при создании представлений, экспорте данных или построении аналитических выборок, где важна чистота выборки, но не требуется изменять исходные данные.
Использование подзапросов для удаления повторяющихся записей
Подзапросы позволяют точно определить дубликаты и удалить избыточные строки, оставив только одну уникальную. Это особенно актуально, когда отсутствует ограничение UNIQUE или первичный ключ, а структура таблицы допускает повторение данных.
Наиболее надёжный способ – использование конструкции DELETE с подзапросом, возвращающим идентификаторы дублирующихся строк. Пример:
DELETE FROM users
WHERE id IN (
SELECT id FROM (
SELECT id
FROM users
WHERE (name, email) IN (
SELECT name, email
FROM users
GROUP BY name, email
HAVING COUNT(*) > 1
)
AND id NOT IN (
SELECT MIN(id)
FROM users
GROUP BY name, email
)
) AS duplicates
);
- Во внешнем запросе удаляются строки по идентификатору
id. - Во внутреннем подзапросе отбираются только те записи, которые повторяются по комбинации
(name, email). - Сохраняется строка с минимальным
id– все остальные считаются дубликатами. - Используется двойное вложение подзапроса, чтобы избежать ошибки MySQL «You can’t specify target table for update in FROM clause».
Рекомендации по использованию:
- Убедитесь, что поле
idуникально – это упрощает выборку. - Выбирайте поля для группировки осознанно: любые отличия между строками исключат их из дубликатов.
- Создавайте резервную копию таблицы перед удалением – операция необратима.
Подзапросы эффективны для удаления повторов в больших объемах данных, особенно при использовании индексов на поля группировки.
Удаление дубликатов по одному столбцу с сохранением одной строки
Для удаления дубликатов по конкретному столбцу, например, email, с сохранением одной строки, используется подзапрос с функцией ROW_NUMBER(). Этот подход сохраняет полный контроль над тем, какая строка остаётся.
Пример для PostgreSQL, SQL Server или других СУБД, поддерживающих оконные функции:
WITH Ranked AS (
SELECT *, ROW_NUMBER() OVER (PARTITION BY email ORDER BY id) AS rn
FROM users
)
DELETE FROM users
WHERE id IN (
SELECT id FROM Ranked WHERE rn > 1
);
Функция ROW_NUMBER() нумерует строки в каждой группе одинаковых значений email. Строки с номером выше 1 считаются дубликатами и подлежат удалению. Параметр ORDER BY id определяет, какая строка сохраняется – самая первая по id. При необходимости можно использовать другой столбец для сортировки, например, created_at.
Для MySQL 8.0+ аналогичный запрос будет выглядеть так же. В более ранних версиях MySQL, не поддерживающих оконные функции, можно использовать подзапрос на MIN(id):
DELETE FROM users
WHERE id NOT IN (
SELECT MIN(id)
FROM users
GROUP BY email
);
Этот подход оставляет строку с минимальным id в каждой группе и удаляет остальные. Однако он не даёт гибкости в выборе, какую строку оставить, и не позволяет сохранить остальные данные в дубликатах.
При удалении дубликатов обязательно делайте резервную копию или используйте транзакцию, чтобы при необходимости откатить изменения.
Применение оконных функций для идентификации повторяющихся строк
Оконные функции позволяют точно определить дубликаты на основе выбранных полей. Используйте функцию ROW_NUMBER() для нумерации строк в разрезе уникального набора значений. Например, чтобы выявить повторы по колонкам email и created_at:
SELECT *, ROW_NUMBER() OVER (PARTITION BY email, created_at ORDER BY id) AS rn FROM users
Значение rn > 1 указывает на повтор. Для получения только дубликатов:
SELECT * FROM (SELECT *, ROW_NUMBER() OVER (PARTITION BY email, created_at ORDER BY id) AS rn FROM users) t WHERE rn > 1
Если нужно оставить первую запись, остальные удалить:
DELETE FROM users WHERE id IN (SELECT id FROM (SELECT id, ROW_NUMBER() OVER (PARTITION BY email, created_at ORDER BY id) AS rn FROM users) t WHERE rn > 1)
Не применяйте DISTINCT или GROUP BY при необходимости сохранить все колонки, включая уникальные. Оконные функции позволяют обойти это ограничение, сохраняя полную информацию и управляя порядком удаления через ORDER BY.
Удаление дубликатов в таблице с сохранением наименьшего или наибольшего значения
Для удаления дубликатов из таблицы с сохранением наименьшего или наибольшего значения в определённой колонке можно использовать SQL запросы с агрегацией и оконными функциями. Это позволяет исключить повторяющиеся строки, оставив те, которые имеют минимальное или максимальное значение в определённой колонке, в зависимости от задачи.
Пример: предположим, что у вас есть таблица с колонками `id`, `value` и `category`. Необходимо удалить строки с одинаковыми значениями в колонке `value`, оставив ту, в которой `category` имеет минимальное значение.
Решение с использованием функции `ROW_NUMBER()`:
WITH ranked AS ( SELECT id, value, category, ROW_NUMBER() OVER (PARTITION BY value ORDER BY category ASC) AS rn FROM your_table ) DELETE FROM your_table WHERE id IN ( SELECT id FROM ranked WHERE rn > 1 );
Здесь мы используем оконную функцию `ROW_NUMBER()`, чтобы нумеровать строки с одинаковым значением в колонке `value`. Строки с наименьшим значением `category` получают номер 1, остальные – номера больше 1. В подзапросе выбираются только те строки, которые имеют номера больше 1, то есть дубликаты, и они удаляются.
Если требуется сохранить строку с максимальным значением в другой колонке, например, по `category`, используется сортировка по убыванию:
WITH ranked AS ( SELECT id, value, category, ROW_NUMBER() OVER (PARTITION BY value ORDER BY category DESC) AS rn FROM your_table ) DELETE FROM your_table WHERE id IN ( SELECT id FROM ranked WHERE rn > 1 );
Аналогичным образом можно работать с другими агрегациями, если нужно учитывать сумму, среднее значение или другие параметры. Важно правильно выбрать колонку для сортировки в оконной функции, чтобы добиться нужного результата.