В языке SQL знак является ключевым элементом для выполнения различных операций. Он используется для сравнения, вычислений, фильтрации данных и других задач, и неправильное его применение может привести к ошибкам или неэффективным запросам. В зависимости от контекста знак может выполнять разные функции, и важно точно понимать, как его использовать в каждом конкретном случае.
Операторы сравнения – одна из основных категорий знаков в SQL. Знаки, такие как =, !=, <, >, BETWEEN и другие, позволяют фильтровать данные по различным условиям. Например, знак равенства = используется для проверки совпадения значений, а знак неравенства != позволяет исключить нежелательные записи. Правильное использование этих знаков помогает избежать ошибок в запросах и значительно ускоряет обработку данных.
Другой важной категорией является использование арифметических знаков в SQL, таких как +, —, *, /. Эти знаки используются для выполнения математических операций прямо в запросах, что позволяет, например, производить расчёты на основе данных из таблиц. Однако важно помнить о приоритете операций и избегать ошибок округления при делении.
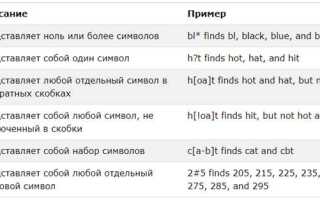
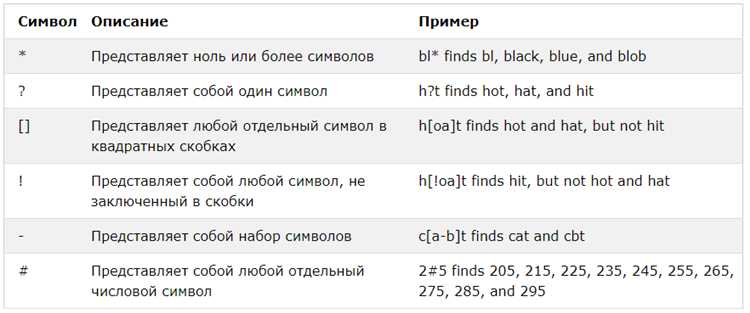
Не менее важен и знак LIKE, который применяется для поиска по шаблону. Он позволяет осуществлять фильтрацию строк с использованием подстановочных символов, таких как % для любых символов или _ для одного символа. Этот знак удобен для поиска по текстовым данным, но следует учитывать, что его использование может замедлить выполнение запроса при большом объеме данных.
Роль знаков в SQL запросах: символы и их значение

Знаки в SQL играют ключевую роль в формировании запросов, уточнении условий и манипуляции данными. Каждый символ имеет свою специфику, которую важно учитывать для правильного составления запросов. Рассмотрим наиболее важные символы и их применение.
Один из наиболее часто используемых знаков в SQL – это символ процента (%) в операторе LIKE. Он служит для подстановки любых символов в строках. Например, запрос SELECT * FROM users WHERE name LIKE 'A%'; возвращает все записи, у которых имя начинается с буквы A, независимо от того, что идет после нее. Символ процента позволяет значительно расширить возможности поиска по текстовым данным.
Также стоит отметить знак подчеркивания (_) в том же операторе LIKE. В отличие от %, он заменяет ровно один символ. Пример: SELECT * FROM products WHERE code LIKE 'A_2'; найдет все строки, где код начинается с «A», за которым идет любой символ, а затем цифра 2.
Для операций сравнения часто используются знаки равенства (=), неравенства (<> или !=), а также операторы больше (>), меньше (<), больше или равно (>=), меньше или равно (<=). Каждый из этих знаков позволяет точно сформулировать логику выборки данных. Важно помнить, что знак <> является стандартом для SQL, однако в некоторых СУБД, таких как MySQL, можно использовать !=.
Знак «и» (AND) и «или» (OR) имеют особое значение при комбинировании условий в запросах. Например, SELECT * FROM orders WHERE price > 100 AND status = 'completed'; вернет все заказы, где цена больше 100 и статус завершен. Использование этих логических операторов помогает уточнить запросы и сократить объем данных.
Для работы с диапазонами чисел и дат часто используется ключевое слово BETWEEN. Оно позволяет задать пределы для выборки. Например, запрос SELECT * FROM employees WHERE hire_date BETWEEN '2020-01-01' AND '2021-01-01'; вернет сотрудников, чьи даты найма лежат в указанном интервале. Это упрощает работу с датами и числовыми значениями.
Не менее важным является символ апострофа (‘) для обозначения строковых значений в запросах. Все строки, передаваемые в SQL, должны быть заключены в одиночные кавычки, что отличает их от других типов данных, таких как числа и даты. Например, SELECT * FROM books WHERE title = 'Harry Potter'; использует апостроф для указания строки.
Также стоит упомянуть использование символов для работы с множествами данных. Оператор IN позволяет выбрать данные, которые соответствуют любому из нескольких значений. Пример: SELECT * FROM products WHERE category IN ('electronics', 'furniture'); вернет все товары, относящиеся к указанным категориям.
Наконец, символы, такие как # и @, могут иметь специфическое значение в определенных СУБД, например, в MySQL или SQL Server. Они могут быть использованы для работы с системными переменными или временными таблицами. Эти символы имеют важное значение в более сложных запросах, а также в различных процедурах и триггерах.
Таким образом, роль знаков в SQL запросах состоит не только в изменении внешнего вида запросов, но и в существенном улучшении точности и эффективности работы с базами данных. Знание их правильного применения необходимо для корректного написания запросов и оптимизации работы с данными.
Использование знака «=» в SQL для сравнения значений

Когда используется знак «=», он проверяет, равны ли два значения. Если они равны, условие считается истинным, если нет – ложным. Например, в операторе SELECT знак «=» позволяет выбрать строки, где столбец соответствует заданному значению.
SELECT * FROM employees WHERE department = 'Sales';– выбирает все записи из таблицыemployees, где значение в столбцеdepartmentравно ‘Sales’.UPDATE products SET price = 20 WHERE product_id = 5;– обновляет цену на товар сproduct_id, равным 5, на 20.DELETE FROM customers WHERE city = 'Moscow';– удаляет все записи из таблицыcustomers, где город равен ‘Moscow’.
Для точного сравнения значений важно учитывать типы данных. Например, при сравнении строк в SQL используется регистрозависимость в некоторых СУБД (например, в PostgreSQL), тогда как в других (например, в MySQL) сравнение строк может быть не чувствительным к регистру по умолчанию. Это стоит учитывать при формировании запросов.
Важно также помнить, что оператор «=» не работает с NULL. Для проверки значений, равных NULL, необходимо использовать специальный оператор IS NULL или IS NOT NULL.
SELECT * FROM orders WHERE delivery_date IS NULL;– выбирает заказы, где дата доставки не указана.
При работе с числовыми значениями знак «=» имеет важное значение, так как он позволяет точно сравнивать данные, например, в операциях с ценами или идентификаторами. Однако, если вам нужно сравнивать значения с определенной погрешностью (например, при работе с вещественными числами), следует использовать операторы, позволяющие задать диапазон значений, такие как BETWEEN.
Также стоит помнить о возможных ошибках при сравнении дат в SQL. Формат даты в SQL зависит от СУБД, и при сравнении важно использовать правильный формат, например, 'YYYY-MM-DD'.
Как знак «>» применяется для фильтрации данных в запросах
 » применяется для фильтрации данных в запросах»>
» применяется для фильтрации данных в запросах»>
Пример простого использования знака «>»:
SELECT * FROM employees WHERE salary > 50000;
В этом примере SQL-запрос выберет все строки из таблицы employees, где значение в колонке salary больше 50 000. Это позволяет эффективно искать записи с высокими зарплатами или другими значениями, превышающими указанный порог.
Знак «>» также может применяться для работы с датами. Например, если необходимо найти сотрудников, чья дата начала работы позднее определённой даты, запрос будет следующим:
SELECT * FROM employees WHERE hire_date > '2020-01-01';
В этом случае выберутся все сотрудники, чья дата приёма на работу была позже 1 января 2020 года.
Важно помнить, что оператор «>» работает с любыми типами данных, которые поддерживают сравнении, включая строки. Для строк это будет означать лексикографическое сравнение, то есть сравнение символов по алфавиту.
При использовании знака «>» для фильтрации данных важно учитывать возможные пограничные значения. Например, запрос:
SELECT * FROM products WHERE price > 100;
выберет все товары, стоимость которых больше 100, но товар с ценой 100 не будет включён в выборку. Это стоит учитывать, чтобы избежать непредвиденных ошибок при анализе данных.
Знак «>» может быть полезен в сочетаниях с другими операторами, например, «AND», для более сложных фильтров. Например, чтобы найти сотрудников с зарплатой более 50 000 и стажем более 5 лет, запрос будет выглядеть так:
SELECT * FROM employees WHERE salary > 50000 AND years_of_experience > 5;
Объяснение знаков «AND» и «OR» в условиях WHERE

В SQL операторы «AND» и «OR» используются для комбинирования нескольких условий в выражении WHERE. Они позволяют создавать более сложные запросы, фильтруя данные в соответствии с несколькими критериями одновременно.
Оператор «AND» возвращает строки, которые удовлетворяют всем указанным условиям. Например, если необходимо выбрать записи, где возраст пользователя больше 30 лет и его статус активен, запрос будет выглядеть так:
SELECT * FROM users WHERE age > 30 AND status = 'active';
Здесь записи, где оба условия (возраст больше 30 и статус активен) истинны, будут включены в результат.
Оператор «OR», напротив, возвращает строки, которые удовлетворяют хотя бы одному из условий. Например, если нужно выбрать пользователей, которые старше 30 лет или имеют активный статус, запрос будет таким:
SELECT * FROM users WHERE age > 30 OR status = 'active';
В этом случае строка будет выбрана, если хотя бы одно из условий выполнено.
Важно помнить о приоритетах операторов. Оператор «AND» имеет более высокий приоритет, чем «OR». Это означает, что в случае комбинирования этих операторов без скобок условия с «AND» будут выполнены первыми. Чтобы изменить порядок выполнения, используйте круглые скобки. Например, запрос:
SELECT * FROM users WHERE age > 30 OR status = 'active' AND email LIKE '%@gmail.com';
выполнится как:
SELECT * FROM users WHERE age > 30 OR (status = 'active' AND email LIKE '%@gmail.com');
Таким образом, скобки изменяют логику выполнения запроса, заставляя сначала выполнить условия «status = ‘active'» и «email LIKE ‘%@gmail.com'», а затем проверять условие с возрастом.
Использование «AND» и «OR» помогает эффективно строить фильтрацию данных, однако важно точно понимать их приоритеты и логику работы для избегания ошибок в запросах.
Многозначность знака «%» при работе с LIKE в SQL
В SQL знак «%» используется в операторе LIKE как шаблон для поиска строк, которые соответствуют определенному шаблону. Это символ, который представляет собой любое количество символов, включая ноль. В зависимости от того, где и как используется знак «%», его поведение может изменяться. Понимание этой многозначности критически важно для эффективной работы с запросами.
При использовании LIKE в запросах к базе данных «%» имеет несколько типов применений:
1. В начале строки: Если знак «%» стоит перед текстом, это означает, что строка может начинаться с любых символов, но обязательно должна содержать текст после процента. Например, выражение LIKE "%abc" найдет все строки, заканчивающиеся на «abc».
2. В конце строки: Если «%» используется после текста, это означает, что строка может заканчиваться любыми символами. Например, LIKE "abc%" найдет все строки, начинающиеся на «abc».
3. Посередине строки: Когда «%» используется как часть шаблона, заключая текст с обеих сторон, это означает, что в строке могут быть любые символы до и после этого текста. Например, запрос LIKE "%abc%" вернет все строки, содержащие «abc» в любом месте.
4. Использование нескольких процентов: Если знак «%» повторяется несколько раз, это означает, что строка может содержать любые символы на любых позициях. Например, запрос LIKE "%%abc%%" будет эквивалентен LIKE "%abc%" и находит строки с «abc» в любом месте.
Кроме того, важно отметить, что SQL чувствителен к регистру, и знак «%» будет работать с учетом этого. Для поиска без учета регистра в большинстве СУБД используется модификация запроса или дополнительные операторы, такие как ILIKE в PostgreSQL.
Эффективность использования знака «%» в запросах может существенно зависеть от позиции этого символа в шаблоне. Например, использование «%» в начале строки может замедлить выполнение запроса, поскольку требует поиска по всем строкам таблицы, а не использования индекса. В таких случаях стоит продумать альтернативные методы, например, использование полнотекстового поиска или других специализированных операторов.
Как знак «+» используется для объединения строк в SQL

В SQL знак «+» используется для конкатенации строк в некоторых СУБД, таких как Microsoft SQL Server и MS Access. Этот оператор позволяет объединять два или более текстовых значения в одно.
Основные моменты использования знака «+» для объединения строк:
- Оператор «+» соединяет два значения типа данных string или varchar.
- Если хотя бы одно из значений является NULL, результат объединения также будет NULL.
- Для числовых значений применяется явное преобразование типов, что может привести к неожиданным результатам при попытке объединить число и строку.
- Можно использовать несколько операторов «+» для соединения нескольких строковых значений в одну строку.
Пример использования:
SELECT FirstName + ' ' + LastName AS FullName FROM Employees;
В данном примере происходит объединение имени и фамилии сотрудников в один столбец с именем FullName. Оператор «+» вставляет пробел между значениями, обеспечивая читаемость результата.
Важно помнить, что в некоторых СУБД, например, в PostgreSQL или MySQL, для объединения строк используется другой оператор – CONCAT(). Поэтому при разработке кросс-платформенных решений необходимо учитывать особенности работы с конкатенацией строк в разных системах.
Рекомендуется использовать оператор «+» с осторожностью, особенно когда в базе данных могут встречаться NULL-значения, так как это может повлиять на корректность результатов запроса. В таких случаях можно использовать функцию ISNULL() или COALESCE(), чтобы обработать возможные NULL-значения до конкатенации.
Применение знаков для работы с NULL в SQL запросах
IS NULL – это основной оператор для проверки на NULL. Он используется в условиях WHERE, чтобы найти строки, где поле не содержит значения. Например:
SELECT * FROM employees WHERE manager_id IS NULL;
Этот запрос выберет всех сотрудников, у которых не указан руководитель.
Противоположный оператор IS NOT NULL используется для поиска строк, где поле содержит ненулевое значение:
SELECT * FROM products WHERE price IS NOT NULL;
Здесь будут возвращены все товары, у которых указана цена.
Также важен знак =, который, несмотря на свою универсальность в сравнении, не подходит для работы с NULL. Сравнение с NULL с использованием знака равно (=) всегда возвращает ложь. Например:
SELECT * FROM orders WHERE delivery_date = NULL;
Этот запрос не даст результатов, поскольку любое сравнение с NULL (через знак = или <>) всегда возвращает неопределённый результат.
Для работы с NULL в выражениях можно использовать функцию COALESCE, которая возвращает первый ненулевой аргумент из списка. Например:
SELECT COALESCE(phone_number, 'Не указан') FROM customers;
Здесь если значение phone_number NULL, то в качестве результата будет возвращён текст ‘Не указан’.
Для замены NULL на конкретное значение часто используют функцию IFNULL (или её аналог, в зависимости от СУБД, например, NVL в Oracle). Она работает по принципу: если первое значение NULL, то возвращается второе. Пример:
SELECT IFNULL(address, 'Адрес не указан') FROM users;
Наконец, стоит помнить, что операции с NULL (например, сложение, вычитание, деление) всегда приводят к результату NULL. Это поведение важно учитывать, чтобы избежать неожиданных результатов при агрегации или вычислениях.
Частые ошибки при использовании знаков в SQL запросах и как их избежать
Другой частой ошибкой является неправильное использование оператора «LIKE» для точных совпадений. Это оператор предназначен для поиска с шаблоном, но многие используют его, когда можно обойтись оператором «=». Пример: SELECT * FROM products WHERE product_code LIKE '12345'; будет работать медленно, в отличие от SELECT * FROM products WHERE product_code = '12345';, что значительно эффективнее.
Ошибки при работе с логическими операторами «AND» и «OR» также довольно распространены. Неправильная расстановка скобок в сложных условиях может привести к неожиданным результатам. Например, запрос SELECT * FROM orders WHERE status = 'completed' OR amount > 1000 AND date > '2025-01-01'; может вернуть неверные данные. Чтобы избежать ошибок, всегда используйте скобки для явного уточнения порядка выполнения операций: SELECT * FROM orders WHERE (status = 'completed' OR amount > 1000) AND date > '2025-01-01';.
При использовании знака «<>», который обозначает «не равно», важно помнить, что его поведение может варьироваться в зависимости от СУБД. Например, в некоторых случаях сравнение с NULL через «<>» не даст ожидаемого результата. Вместо этого следует использовать оператор IS NOT NULL, чтобы проверить, что значение не является NULL: SELECT * FROM employees WHERE salary IS NOT NULL;.
Использование знаков для работы с датами и временем тоже требует внимательности. Часто программисты ошибаются, пытаясь сравнить даты без приведения типов или используют неподходящие форматы. Например, запрос SELECT * FROM events WHERE event_date > '2025-12-01'; может не сработать, если дата в базе данных хранится в формате YYYY-MM-DD или DD/MM/YYYY. Всегда проверяйте формат данных в базе и, при необходимости, используйте функцию для приведения типов, например, STR_TO_DATE() в MySQL.
Ещё одна ошибка – это избыточное использование оператора «DISTINCT». Часто его применяют там, где он не нужен, например, при запросах с единственным уникальным значением в результирующем наборе. Применение этого оператора может замедлить выполнение запроса, особенно на больших таблицах. Лучше избегать использования «DISTINCT», если вы уверены, что данные уже уникальны.
Ошибки с использованием символов подстановки «%» и «_» при работе с оператором «LIKE» также достаточно распространены. Например, использование LIKE '%abc' приведет к поиску строк, заканчивающихся на «abc», но если потребуется найти строки, начинающиеся с «abc», нужно использовать шаблон 'abc%'. Иногда неправильное использование этих символов может существенно повлиять на производительность запросов.
Чтобы избежать таких ошибок, всегда проверяйте синтаксис, внимательно анализируйте структуру запросов и проводите тестирование на ограниченных выборках данных. Используйте средства профилирования запросов для выявления неэффективных операций и для оптимизации работы с большими объёмами данных.