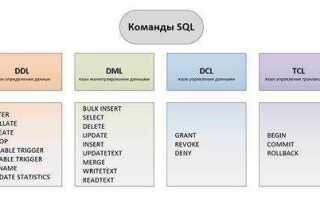
SQL запросы, предназначенные для работы с реляционными базами данных, обеспечивают удобный способ работы с данными. Однако при обработке больших объемов информации, например, в распределенных вычислительных системах, таких как Hadoop, стандартные SQL запросы не могут быть напрямую выполнены. В таких системах используется парадигма MapReduce, которая решает задачи параллельной обработки данных. Процесс преобразования SQL запросов в задания MapReduce требует четкого понимания того, как каждый этап SQL запроса может быть представлен в терминах MapReduce.
Каждый SQL запрос можно разбить на несколько операций, которые соответствуют задачам Map и Reduce в модели MapReduce. Операции фильтрации, агрегации и сортировки SQL запросов должны быть тщательно адаптированы для работы в распределенной среде. Например, операции выборки SELECT и фильтрации WHERE могут быть трансформированы в шаги Map, где данные разбиваются на блоки и анализируются параллельно. В то же время, операции объединения JOIN и агрегации GROUP BY потребуют выполнения дополнительных шагов для объединения и сводки данных в Reduce фазе.
Важно отметить, что преобразование SQL запроса в MapReduce не всегда бывает прямолинейным. Некоторые конструкции SQL требуют дополнительных оптимизаций и сложных алгоритмов для минимизации времени обработки и использования ресурсов. Например, сложные операции соединений или подзапросы могут быть преобразованы в более сложные последовательности MapReduce задач, включающие несколько этапов промежуточной агрегации.
Процесс трансформации SQL запросов в MapReduce задания требует детального подхода к разбиению данных и управлению состоянием вычислений. Умение оптимизировать такие трансформации помогает существенно повысить производительность системы обработки данных, особенно в условиях обработки огромных массивов информации.
Преобразование SQL SELECT-запроса в этапы MapReduce
Процесс преобразования SQL SELECT-запроса в этапы MapReduce включает несколько ключевых шагов, каждый из которых соответствует одной из стадий обработки данных в модели MapReduce. Рассмотрим, как этот процесс выглядит на практике.
Основные этапы преобразования SQL-запроса в MapReduce:
- Этап Map: На этом этапе SQL-запрос выполняет операцию выборки данных. Map-функция отвечает за распределение данных по ключам. Например, в случае SQL-запроса с агрегацией данных, таких как
SELECTсGROUP BY, каждому уникальному значению из колонки создается соответствующая пара «ключ-значение». - Фильтрация данных: В SQL-запросах часто используется
WHEREдля фильтрации данных. На этапе Map фильтрация выполняется через условие, проверяя каждый элемент, прежде чем отправить его на следующие этапы. Map-функция может отбросить неинтересующие данные, передавая лишь те, которые соответствуют фильтрам SQL-запроса. - Перенос в этап Reduce: После того как все данные распределены по ключам на этапе Map, они отправляются на этап Reduce. Здесь выполняется агрегация, как, например, в случае использования SQL-функций
COUNT(),SUM(),AVG()и других агрегатных функций. Каждый уникальный ключ, получивший пару «ключ-значение», будет обработан индивидуально, и выполняются нужные вычисления. - Объединение данных (шаг Reduce): На этапе Reduce SQL-запрос с
JOINможет быть реализован как объединение данных, полученных из разных источников. MapReduce выполняет объединение по ключам, сгруппировав их, а затем применяет требуемую операцию для комбинирования данных.
Пример:
SELECT country, COUNT(*) FROM users GROUP BY country- Map-функция: разбивает данные по странам (ключ — страна, значение — 1).
Reduce-функция: суммирует количество пользователей по каждой стране.
Таким образом, преобразование SQL-запроса в MapReduce требует учета как структуры исходных данных, так и особенностей агрегирования, фильтрации и объединения информации. Этот процесс позволяет эффективно обрабатывать большие объемы данных, разделяя вычисления на множество независимых задач, выполняющихся параллельно.
Реализация операций JOIN в MapReduce на основе SQL-запросов
SQL-запрос с операцией JOIN преобразуется в MapReduce за счет применения двух этапов: Map и Reduce. На этапе Map данные разбиваются по ключам, что позволяет обработать каждую группу данных отдельно. Затем на этапе Reduce происходит выполнение самого соединения на основе этих ключей.
Рассмотрим несколько типов JOIN в контексте MapReduce.
Inner Join
В случае inner join соединяются только те записи, которые соответствуют условиям соединения в обеих таблицах. Во время маппинга каждая строка данных из обеих таблиц метится соответствующим ключом, на основе которого и происходит дальнейшая агрегация. Например, если у нас есть таблица с пользователями и таблица с заказами, то в Mapper обе таблицы будут снабжены ключами, такими как идентификатор пользователя. После этого в Reduce этапе происходит объединение всех записей с одинаковыми ключами. Важно, чтобы данные с одинаковыми ключами попадали на один редьюсер, что достигается использованием правильной хеш-функции.
Left Join
Для left join важным аспектом является сохранение всех записей из левой таблицы, даже если нет совпадений в правой. На этапе Map происходит маркировка данных так, чтобы редьюсер мог понять, какие записи из левой таблицы не имеют соответствий в правой. Такие записи на этапе Reduce будут включать null или пустые значения для правой таблицы.
Broadcast Join
Если одна из таблиц значительно меньше другой, то может быть использован подход broadcast join. В этом случае меньшая таблица полностью передается всем редьюсерам. Маппер создает ключи для всех записей из более крупной таблицы и передает их вместе с данными из меньшей таблицы. Это позволяет минимизировать количество данных, передаваемых между узлами и ускорить выполнение запроса.
Hash Join
В случае hash join в MapReduce данные из обеих таблиц разбиваются на блоки с помощью хеширования по ключу. Это позволяет эффективно искать соответствующие записи в обеих таблицах. Преимущество этого подхода в том, что можно уменьшить объем данных, передаваемых в сеть, так как записи, имеющие одинаковый ключ, всегда будут передаваться в один и тот же редьюсер.
Задачи и рекомендации
Для эффективной реализации JOIN-операций в MapReduce необходимо учитывать несколько факторов:
- Размер данных: Если одна таблица значительно больше другой, стоит использовать broadcast join, чтобы избежать излишней передачи больших объемов данных между узлами.
- Группировка данных: При выполнении MapReduce операций необходимо заранее продумать способ группировки данных по ключам, так как это определяет эффективность объединения на этапе Reduce.
- Оптимизация шардирования: На этапе шардирования важно удостовериться, что данные распределены равномерно, чтобы не возникало перегрузки одного узла, что может замедлить процесс.
Реализация операций JOIN в MapReduce требует внимательного подхода к архитектуре обработки данных, так как неправильное распределение или использование памяти может привести к значительным потерям производительности. Тем не менее, при правильной настройке MapReduce может эффективно справляться с большими объемами данных, выполняя операции соединения с высокой масштабируемостью.
Как агрегировать данные в MapReduce с помощью SQL GROUP BY
Агрегация данных с помощью SQL GROUP BY в MapReduce требует понимания процесса преобразования запросов в два этапа – Map и Reduce. В SQL оператор GROUP BY используется для группировки строк по определённому столбцу с последующим применением агрегатных функций, таких как COUNT, SUM, AVG, MAX и MIN. В MapReduce этот процесс аналогичен: данные сначала группируются, а затем для каждой группы выполняются агрегатные операции.
На этапе Map задачи данных разбиваются на ключ-значение, где ключ – это значение, по которому будет производиться группировка, а значение – это данные, которые нужно агрегировать. Например, если нужно посчитать количество продаж по каждому продукту, ключом будет идентификатор продукта, а значением – количество продаж. Mapper анализирует входные данные и создаёт пары (ключ, значение), где ключом является объект группировки, а значением – данные для агрегирования.
После выполнения этапа Map данные передаются в Reducer, который собирает все значения по ключам. В этом этапе происходит собственно агрегация: для каждой группы значений вычисляются результаты, аналогичные SQL-функциям. Например, если ключом является идентификатор продукта, а значениями – объёмы продаж, то Reducer выполнит операцию подсчёта суммарных продаж или среднего значения по каждой группе.
В отличие от SQL, где агрегирование происходит в рамках одного этапа, в MapReduce важно обеспечить правильную сортировку и передачу данных между Mapper и Reducer. При этом задача не только заключается в группировке по ключу, но и в корректной передаче агрегированных значений для дальнейших вычислений.
Рекомендации:
- Используйте комбинированные функции MapReduce: для сложных операций агрегации, таких как подсчёт сумм и средних значений, можно применить дополнительные оптимизации на этапе Map, например, предварительную агрегацию.
- Оптимизируйте процесс сортировки: из-за больших объёмов данных важно минимизировать количество передаваемых промежуточных данных между мапперами и редьюсерами. Сортировка данных по ключу помогает ускорить агрегацию.
- Работа с большими наборами данных: при использовании MapReduce для агрегации убедитесь, что ваши данные разделены на эффективные блоки, что позволит уменьшить нагрузку на систему и ускорить обработку.
Таким образом, хотя MapReduce и SQL используют разные подходы к агрегации данных, принципы остаются схожими: в обоих случаях необходимо грамотно организовать группировку и выполнить агрегатные операции. В MapReduce агрегация реализуется через процессы сортировки, передачи и агрегации данных на этапах Map и Reduce, что требует дополнительной настройки для обеспечения высокой производительности при работе с большими объемами данных.
Трансформация SQL ORDER BY в MapReduce сортировку данных
В SQL запросах оператор ORDER BY используется для сортировки данных по определённым полям. При преобразовании таких запросов в MapReduce, задача сортировки данных делится на два этапа: этап Map и этап Reduce. На первом этапе, Map функции обрабатывают данные, а на втором – происходит их объединение и сортировка в Reduce шаге.
На стадии Map данные разбиваются на пары ключ-значение. Каждая пара передаётся в Map функцию, которая извлекает ключ (например, значение поля для сортировки) и формирует список значений, связанных с этим ключом. Однако, на этом этапе сортировка данных не производится. Map функции просто группируют данные по ключу, сохраняя их первоначальный порядок.
Сортировка данных происходит на стадии Reduce. Для реализации сортировки по ключу в MapReduce, необходимо обеспечить, чтобы все значения с одинаковыми ключами передавались на одну и ту же ноду, где будет происходить их окончательная обработка. На этапе Reduce выполняется сортировка значений для каждого ключа, что аналогично выполнению операции ORDER BY в SQL.
В случае, если требуется сортировка по нескольким полям, MapReduce выполняет сортировку по основному ключу, а затем по дополнительным полям внутри Reduce функции. Например, для сортировки по двум или более столбцам SQL запроса, ключи Map функции могут быть составными, что позволяет на этапе Reduce выполнить сортировку по нужному набору параметров.
Важно учитывать, что MapReduce не всегда предоставляет возможность прямого и оптимального выполнения сортировки, как это происходит в SQL. Сортировка в MapReduce может быть менее эффективной из-за необходимости передачи больших объёмов данных между узлами, что увеличивает нагрузку на сеть и процессор. Для повышения производительности часто применяют предварительную сортировку на этапе Map или использование более сложных алгоритмов сортировки в Reduce.
Обработка подзапросов SQL в контексте MapReduce
Подзапросы в SQL выполняют ключевую роль при сложных запросах, особенно в случаях, когда необходимо выполнить несколько шагов для получения данных. В контексте MapReduce, обработка подзапросов требует особого подхода из-за различий в парадигмах обработки данных.
Подзапросы могут быть использованы в различных формах: как часть SELECT, в WHERE или HAVING, а также в операциях JOIN. В традиционном SQL подзапросы выполняются синхронно и последовательно, что требует их интеграции в общую логику запроса. В MapReduce обработка подзапросов требует предварительного разделения задачи на этапы, которые могут быть параллельно обработаны в распределённой среде.
В MapReduce для реализации подзапросов SQL, каждый подзапрос часто преобразуется в отдельный этап обработки данных, состоящий из операций map и reduce. Рассмотрим пример обработки подзапроса в SELECT запросе:
SELECT name, (SELECT AVG(salary) FROM employees WHERE department = 'IT') AS avg_salary FROM employees;
В MapReduce этот запрос может быть разбит на два этапа:
- На этапе map данные из таблицы employees с сортировкой по департаментам группируются, и для каждого департамента производится вычисление среднего значения зарплаты. Это имитирует подзапрос, который ищет среднюю зарплату для определенного департамента.
- На этапе reduce результат из map этапа агрегируется и присоединяется к основным данным для каждого сотрудника, создавая окончательный результат, аналогичный итоговому запросу SQL.
Важно отметить, что подзапросы могут требовать выполнения промежуточных вычислений, что может увеличить время работы системы. Особенно это касается вложенных подзапросов, которые могут потребовать многократных вычислений на каждом этапе map-reduce. Например, при работе с подзапросами, содержащими агрегации, MapReduce должен выполнить обработку каждой группы данных на различных этапах, что может быть неэффективно при большом объеме данных.
Для оптимизации можно использовать технику предвычисления подзапросов. Это позволяет избежать повторных вычислений одного и того же подзапроса для каждого ключа, например, если подзапрос вычисляет агрегированные данные по группам, то эти данные можно сохранить в промежуточные файлы, которые используются на более поздних этапах обработки. Также возможно использование фильтров на этапе map для сокращения объема данных, передаваемых на этап reduce, что увеличивает производительность.
Другим важным моментом является обработка подзапросов с соединениями (JOIN). При выполнении запроса с подзапросами, которые соединяют несколько таблиц, MapReduce требует специальной обработки для объединения данных из различных источников. Это может быть реализовано путем использования метода соединения на основе ключей (например, Map-side join или Reduce-side join), в зависимости от размера данных и структуры подзапроса.
Таким образом, при обработке подзапросов в MapReduce необходимо учитывать особенности параллельной обработки, а также проводить предварительную оптимизацию, чтобы минимизировать избыточные вычисления и ускорить выполнение запросов.
Как оптимизировать MapReduce задания, полученные из SQL-запросов
Оптимизация MapReduce заданий, созданных на основе SQL-запросов, требует внимательного подхода к структуре данных, распределению вычислительных ресурсов и минимизации промежуточных этапов обработки. На основе типичных SQL-запросов можно выделить несколько стратегий для улучшения производительности MapReduce.
Первое, на что стоит обратить внимание – это выбор ключей для операции Map. При генерации MapReduce задания из SQL-запроса важно правильно выбрать ключи, по которым будут происходить разделение данных. Для этого нужно учитывать характер SQL-запроса. Например, если запрос выполняет соединение нескольких таблиц, то ключи для Map операции должны быть выбраны так, чтобы минимизировать количество данных, передаваемых между узлами. Это позволит сократить время, затраченное на шифрование и дешифровку данных, а также избежать излишней передачи больших объемов информации между задачами.
Второй аспект – это использование комбинированных и агрегированных данных на этапе Reduce. SQL-запросы, выполняющие агрегирование или сортировку, можно преобразовать в MapReduce задания с оптимизацией на этапе Reduce. Для этого полезно применять техники, такие как «Combiner», который выполняет агрегацию данных локально на каждом узле, до того как данные будут переданы на глобальный этап Reduce. Это позволяет снизить количество передаваемой информации и ускорить обработку.
Также стоит обратить внимание на оптимизацию хранения промежуточных данных. В SQL-запросах часто применяются временные таблицы или подзапросы, которые могут быть преобразованы в MapReduce задания, но в процессе их обработки важно контролировать использование промежуточных данных. Хранение таких данных на диске может сильно замедлить выполнение, поэтому лучше использовать оперативную память или системы хранения с быстрым доступом, если это возможно.
Особое внимание стоит уделить минимизации количества этапов MapReduce. Некоторые SQL-запросы могут генерировать избыточные промежуточные операции, такие как ненужные фильтрации, сортировки или агрегации. Чтобы избежать этого, стоит заранее проанализировать, какие этапы можно объединить или устранить. Например, несколько последовательных фильтраций можно объединить в одну, что сократит количество операций и ускорит выполнение.
Важно также учитывать стратегию разбиения данных. Когда SQL-запрос выполняет сложные операции, такие как соединение таблиц или фильтрацию больших объемов данных, лучше использовать более мелкие единицы работы на этапе Map. Это позволит значительно уменьшить время выполнения за счет параллельной обработки данных.
И, наконец, следует помнить о мониторинге и профилировании производительности. Инструменты, такие как Hadoop’s job tracker или Spark UI, позволяют анализировать работу MapReduce заданий в реальном времени. Они помогают выявить узкие места, такие как долго выполняющиеся задачи или перегрузка сети, что даёт возможность оптимизировать их выполнение через перераспределение ресурсов или изменение параметров задания.
Вопрос-ответ:
Что такое MapReduce и как он используется для обработки SQL запросов?
MapReduce — это параллельная вычислительная модель, используемая для обработки и генерации больших данных. В контексте обработки SQL запросов, MapReduce делит задачу на две фазы: «Map» и «Reduce». На этапе Map данные из исходных таблиц распределяются по множеству узлов, которые обрабатывают части данных параллельно. После этого, на этапе Reduce, результаты агрегируются и обрабатываются для получения итогового ответа. Такой подход помогает ускорить обработку больших объемов информации, что особенно важно при работе с базами данных с большими наборами данных.
Как SQL запросы преобразуются в задания MapReduce на практике?
Для преобразования SQL запросов в задания MapReduce используется несколько этапов. Во-первых, SQL запрос анализируется и разбивается на подзадачи, соответствующие операциям Map и Reduce. Например, запрос на агрегацию данных или группировку можно разбить на несколько этапов, где Map будет распределять данные по узлам для вычисления промежуточных результатов, а Reduce — собирать эти результаты и проводить финальную агрегацию. Такие системы, как Apache Hive, автоматически выполняют трансляцию SQL запросов в MapReduce задания, позволяя пользователям работать с данными на высоком уровне без необходимости вручную управлять процессом MapReduce.
Почему MapReduce эффективен для обработки больших SQL запросов?
MapReduce эффективен для обработки больших SQL запросов благодаря своей способности параллельно распределять вычисления между множеством узлов в кластере. Это позволяет ускорить обработку данных, уменьшить время выполнения запросов, особенно когда речь идет о больших объемах данных, которые не помещаются на одном сервере. В SQL запросах, например, при агрегации данных или сортировке, MapReduce позволяет обрабатывать части данных независимо, а затем агрегировать результаты. Это распределение нагрузки помогает снизить нагрузку на один сервер и сделать обработку более масштабируемой.
Какое влияние оказывает использование MapReduce на производительность SQL запросов?
Использование MapReduce существенно улучшает производительность SQL запросов при работе с большими объемами данных. Благодаря параллельной обработке данных, можно значительно ускорить выполнение сложных операций, таких как сортировка, фильтрация и агрегация, особенно в случае, когда данные распределены на нескольких серверах. Однако, стоит отметить, что для небольших объемов данных использование MapReduce может не дать значительного прироста производительности, так как накладные расходы на распределение задачи могут превышать выгоды от параллельной обработки.
Какие типы SQL запросов можно эффективно преобразовать в задания MapReduce?
MapReduce хорошо подходит для обработки SQL запросов, которые включают большие объемы данных и сложные операции, такие как агрегация, сортировка, фильтрация и группировка. Например, запросы типа SELECT с операциями GROUP BY или JOIN, которые могут быть трудоемкими при обработке больших таблиц, могут быть эффективно разделены на несколько подзадач MapReduce. Такие запросы часто применяются в аналитике больших данных, когда необходимо обрабатывать записи из нескольких источников или агрегировать большие массивы данных. Однако для простых запросов, таких как поиск конкретных значений в малых таблицах, MapReduce может быть избыточным и менее эффективным.