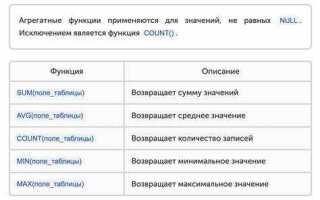
Агрегатные функции SQL позволяют выполнять вычисления на основе данных, собранных из нескольких строк, и возвращать единственное значение. Эти функции незаменимы при анализе больших объемов данных, когда необходимо получить сводную информацию, например, сумму, среднее значение или количество записей. В отличие от обычных функций, которые работают с отдельными строками данных, агрегатные функции обрабатывают группы строк, что делает их мощным инструментом в работе с базами данных.
Одной из основных агрегационных функций является COUNT(), которая используется для подсчета количества строк, удовлетворяющих заданным условиям. Это полезно при анализе частоты встречаемости определенных данных или оценке размера выборки. Например, с помощью COUNT() можно подсчитать количество заказов для каждого клиента в системе, что дает представление о загрузке и активности пользователей.
Функции SUM(), AVG() и MIN()/MAX() позволяют работать с числовыми данными, предоставляя сумму, среднее значение или экстремальные значения в группе строк. Эти функции часто используются для финансового анализа или при обработке статистических данных. Например, SUM() может быть использована для расчета общей выручки по каждому региону, а AVG() – для получения средней стоимости товаров или услуг в выбранной категории.
Особенность применения агрегатных функций заключается в их взаимодействии с оператором GROUP BY, который позволяет группировать данные по определенному признаку. Это особенно важно при анализе структурированных данных, где необходимо получить показатели по категориям или регионам, например, для построения отчетов по продажам по месяцам или по категориям товаров.
Использование функции COUNT для подсчета записей в SQL
Функция COUNT в SQL используется для подсчета количества строк, соответствующих определенному условию. Это одна из самых часто применяемых агрегатных функций, которая возвращает количество записей в результате запроса. COUNT может работать как с полями, так и с набором строк в целом.
Для базового использования COUNT достаточно указать колонку или использовать символ «*», чтобы посчитать все строки. Пример простого запроса:
SELECT COUNT(*) FROM employees;
Этот запрос вернет общее количество строк в таблице employees.
Если нужно посчитать записи с учетом фильтрации, можно использовать WHERE. Например, чтобы подсчитать количество сотрудников в отделе продаж:
SELECT COUNT(*) FROM employees WHERE department = 'Sales';
Важно отметить, что COUNT(
SELECT COUNT(salary) FROM employees;
Этот запрос посчитает количество строк, где значение в колонке salary не NULL.
В случае подсчета уникальных значений используется конструкция COUNT(DISTINCT
SELECT COUNT(DISTINCT job_title) FROM employees;
COUNT применим и в контексте группировки данных. Например, если необходимо посчитать количество сотрудников в каждом отделе, можно использовать GROUP BY:
SELECT department, COUNT(*) FROM employees GROUP BY department;
Этот запрос вернет количество сотрудников в каждом отделе, сгруппированное по значению в колонке department.
Функция COUNT эффективно используется для анализа данных и является основным инструментом при работе с большими объемами информации, позволяя быстро получить статистику и обрабатывать данные для дальнейшего анализа.
Применение SUM для вычисления суммы числовых значений

Функция SUM() в SQL используется для вычисления общей суммы значений в числовых столбцах. Она активно применяется для агрегации данных, когда требуется получить суммарную информацию, например, для подсчета общей выручки, суммарного объема продаж или других финансовых показателей.
Для корректного использования SUM() важно учитывать несколько аспектов:
- Исключение NULL-значений: Функция автоматически игнорирует строки, в которых значения столбца равны NULL. Это поведение полезно при анализе данных, где не все записи могут содержать числовые значения.
- Группировка данных: Когда требуется вычислить сумму для каждой категории данных (например, для каждого региона или клиента), необходимо использовать оператор GROUP BY. Это позволяет получать суммы по отдельным группам.
- Фильтрация данных: Для работы с подмножествами данных, к примеру, чтобы вычислить сумму по определенному промежутку времени, следует использовать оператор WHERE.
Пример использования SUM() для подсчета общей суммы заказов:
SELECT customer_id, SUM(order_amount) FROM orders WHERE order_date BETWEEN '2023-01-01' AND '2023-12-31' GROUP BY customer_id;
В данном примере функция SUM() суммирует значения столбца order_amount для каждого клиента в заданный промежуток времени. Группировка по customer_id позволяет получить итоговую сумму заказов по каждому клиенту.
Еще один распространенный случай использования SUM() – подсчет общей выручки для определенного товара в разные периоды. В таких случаях важно правильно задать условия выборки, чтобы результат был точным и соответствовал бизнес-целям.
Таким образом, SUM() является мощным инструментом для анализа и обобщения числовых данных в SQL, позволяя не только вычислять сумму, но и адаптировать запросы под конкретные требования анализа.
Как использовать AVG для нахождения среднего значения в наборе данных
Функция AVG в SQL позволяет вычислить среднее значение для набора данных в столбце. Это полезно для анализа числовых данных, таких как цены, баллы, зарплаты и другие метрики. Чтобы использовать AVG, необходимо указать столбец, по которому нужно вычислить среднее значение, а также при необходимости применить дополнительные фильтры или условия.
Пример использования AVG для нахождения среднего значения в столбце «salary» в таблице «employees»:
SELECT AVG(salary) FROM employees;
Этот запрос вернёт среднюю зарплату всех сотрудников из таблицы. Однако, если нужно найти среднее значение только для определённой группы, например, для сотрудников из определённого отдела, следует использовать WHERE:
SELECT AVG(salary) FROM employees WHERE department = 'IT';
Кроме того, AVG можно комбинировать с другими агрегатными функциями, такими как COUNT, MIN и MAX, для более сложных анализов. Например, чтобы узнать среднюю зарплату в разных департаментах:
SELECT department, AVG(salary) FROM employees GROUP BY department;
Этот запрос вернёт среднее значение зарплаты для каждого отдела. При использовании AVG важно помнить, что функция игнорирует значения NULL, что позволяет получать точные результаты, даже если в наборе данных есть пропущенные значения.
Для повышения точности можно округлять результат, используя функцию ROUND. Например, чтобы округлить среднее значение до двух знаков после запятой:
SELECT ROUND(AVG(salary), 2) FROM employees;
Использование MIN и MAX для поиска минимального и максимального значения
Функция MIN возвращает наименьшее значение из указанного столбца, а MAX – наибольшее. Их применяют для анализа числовых, строковых и датированных данных. Например, для определения самой низкой и высокой температуры в данных о погоде, минимальной и максимальной стоимости товара на складе или самой ранней и поздней даты события.
Пример использования функции MIN для нахождения самой низкой цены товара:
SELECT MIN(price) FROM products;Аналогично, для нахождения самой высокой цены:
SELECT MAX(price) FROM products;Для более сложных запросов, например, чтобы найти минимальное или максимальное значение по определенному набору данных, можно использовать GROUP BY. Например, если нужно найти минимальную и максимальную цену для каждого производителя, запрос будет следующим:
SELECT manufacturer, MIN(price), MAX(price)
FROM products
GROUP BY manufacturer;Этот запрос покажет минимальную и максимальную цену для каждого производителя, что полезно при анализе ценовых категорий разных брендов.
Функции MIN и MAX могут работать и с датами. Например, для нахождения самой ранней и самой поздней даты события:
SELECT MIN(event_date), MAX(event_date)
FROM events;Кроме того, использование этих функций помогает оптимизировать запросы. Вместо того, чтобы извлекать все значения и обрабатывать их на уровне приложения, агрегатные функции позволяют вычислять минимальные и максимальные значения непосредственно на сервере базы данных, что значительно ускоряет процесс и снижает нагрузку на клиентскую сторону.
Важно учитывать, что функции MIN и MAX игнорируют значения NULL. Это означает, что если столбец содержит значения NULL, они не будут учтены при вычислении минимального или максимального значения. Если нужно учитывать NULL значения, можно использовать дополнительные проверки в запросах.
Для эффективного применения этих функций важно правильно индексировать столбцы, по которым выполняются агрегатные операции. Это обеспечит быстрое выполнение запросов, особенно при работе с большими объемами данных.
Группировка данных с помощью GROUP BY и агрегатных функций
Группировка данных в SQL позволяет обрабатывать данные в агрегированные наборы, что особенно полезно для анализа и получения сводной информации. Команда GROUP BY используется для разделения строк в таблице на группы по одному или нескольким столбцам, а агрегатные функции, такие как COUNT(), SUM(), AVG(), MIN() и MAX(), применяются к этим группам для вычисления обобщающих значений.
Основная цель GROUP BY – создание подмножеств данных, которые имеют одинаковые значения в указанных столбцах. Например, можно сгруппировать продажи по регионам или посчитать количество заказов для каждого клиента.
Применение агрегатных функций вместе с GROUP BY позволяет выполнить следующие задачи:
- Подсчет количества записей: Функция COUNT() позволяет подсчитать количество строк в каждой группе. Например, чтобы узнать, сколько заказов сделано каждым клиентом, можно использовать следующий запрос:
SELECT customer_id, COUNT(*) FROM orders GROUP BY customer_id;
- Вычисление сумм: Функция SUM() используется для подсчета суммы значений в группе. Например, для подсчета общей суммы заказов по регионам запрос будет выглядеть так:
SELECT region, SUM(order_total) FROM orders GROUP BY region;
- Среднее значение: AVG() помогает вычислить среднее значение по каждой группе. Это полезно для анализа, например, среднего чека клиента:
SELECT customer_id, AVG(order_total) FROM orders GROUP BY customer_id;
- Поиск минимального и максимального значения: MIN() и MAX() позволяют найти наименьшее или наибольшее значение в каждой группе. Например, для определения самого маленького и самого большого заказа по каждому региону:
SELECT region, MIN(order_total), MAX(order_total) FROM orders GROUP BY region;
GROUP BY может использоваться в сочетании с другими фильтрами, например, с условием WHERE для ограничения данных до применения группировки. Также часто применяется HAVING, чтобы фильтровать уже сгруппированные данные по результатам агрегатных функций.
Пример запроса, который сначала фильтрует данные по сумме заказов, а затем группирует их по регионам:
SELECT region, SUM(order_total) FROM orders WHERE order_date > '2024-01-01' GROUP BY region HAVING SUM(order_total) > 10000;
Такое использование HAVING позволяет исключать группы с небольшими суммами, что полезно для анализа значимых данных.
Важно помнить, что все столбцы, которые не являются частью агрегатной функции, должны быть указаны в GROUP BY. Если этого не сделать, SQL вернет ошибку.
Применение HAVING для фильтрации результатов агрегирования

В SQL оператор HAVING используется для фильтрации результатов после применения агрегатных функций, таких как SUM(), AVG(), COUNT(), MAX(), MIN(). Он позволяет отфильтровать группы данных, которые были собраны с помощью оператора GROUP BY, основываясь на результатах этих функций. Важно, что HAVING работает только после выполнения агрегирования, в отличие от WHERE, который применяется до агрегации данных.
Применение HAVING обычно необходимо, когда нужно применить фильтрацию на основе агрегированных данных. Например, если нужно выбрать все продукты, для которых общая сумма продаж превышает 10000 единиц, то без HAVING это было бы невозможно, так как фильтрация по агрегированным данным до выполнения агрегации невозможна.
Пример запроса с использованием HAVING:
SELECT category, SUM(sales) FROM products GROUP BY category HAVING SUM(sales) > 10000;
В данном примере данные о продажах продуктов группируются по категориям, и фильтрация по сумме продаж происходит только после того, как агрегирование данных завершено. Без оператора HAVING такая фильтрация была бы невозможна.
Следует учитывать, что фильтрация с помощью HAVING может существенно повлиять на производительность запросов, особенно при работе с большими объемами данных. Поэтому важно понимать, что HAVING не является заменой WHERE, и его следует использовать только тогда, когда необходимо фильтровать агрегированные данные.
Применение HAVING также полезно при комплексных запросах, например, для вычисления статистических показателей по группам данных, с последующей фильтрацией этих групп на основе условий, зависящих от агрегатных значений. Однако важно избегать излишней сложности в запросах, так как это может привести к снижению их читаемости и производительности.
Комбинирование агрегатных функций с подзапросами для сложных анализов
Для выполнения более глубоких и точных анализов в SQL часто применяется сочетание агрегатных функций с подзапросами. Это позволяет не только вычислять обобщенные данные, но и обрабатывать их в контексте конкретных условий или ограничений. Подзапросы могут быть использованы для предварительной фильтрации данных, агрегации по специфическим группам или даже для сравнения результатов.
Подход с агрегатными функциями и подзапросами используется в случаях, когда требуется анализировать данные, которые не могут быть получены простыми группировками. Рассмотрим основные сценарии применения.
- Фильтрация данных до агрегации: Подзапросы могут быть использованы для фильтрации записей до применения агрегатных функций. Это позволяет снизить объем данных, с которыми работает основная агрегация. Например, можно сначала выбрать только те записи, которые соответствуют определенному диапазону значений, и затем применить к ним агрегатные функции.
- Агрегация по результатам подзапросов: В некоторых случаях необходимо сначала выполнить подзапрос для вычисления некой суммы, средней или другой метрики, а затем использовать этот результат в основном запросе. Это полезно, когда данные агрегируются на основе динамических условий.
- Использование агрегатных функций в подзапросах: Подзапросы могут быть настроены таким образом, чтобы агрегировать данные внутри них. Например, можно подсчитать среднее значение по всем записям, а затем использовать это значение в основном запросе для вычислений.
Пример использования агрегатных функций и подзапросов:
SELECT department_id, AVG(salary) AS avg_salary, (SELECT MAX(salary) FROM employees WHERE department_id = d.department_id) AS max_salary FROM employees d GROUP BY department_id;
В данном примере подзапрос вычисляет максимальную зарплату в каждом департаменте, а основной запрос – среднюю. Это позволяет получить данные о среднем уровне зарплаты и наивысшей зарплате в одном запросе, используя подзапросы для сравнения.
Еще один пример: подзапрос может быть использован для нахождения данных по определенному критерию и передавать их в основной запрос для вычисления статистики.
SELECT product_id, COUNT(*) AS sales_count, (SELECT AVG(price) FROM products WHERE category = p.category) AS avg_category_price FROM sales s JOIN products p ON s.product_id = p.product_id GROUP BY product_id;
Здесь подзапрос сначала вычисляет среднюю цену для всех товаров из той же категории, а затем основная агрегация определяет количество продаж для каждого товара. Это позволяет эффективно проводить сравнение каждого товара с его категорией по цене.
Важно учитывать производительность таких запросов, так как использование подзапросов может повлиять на время выполнения, особенно при работе с большими объемами данных. Поэтому оптимизация подзапросов и индексация соответствующих полей играют ключевую роль в повышении эффективности.
Для выполнения сложных аналитических запросов комбинирование агрегатных функций и подзапросов может значительно улучшить точность анализов, но требует внимательного подхода к структуре запроса и использованию индексов.
Вопрос-ответ:
Что такое агрегатные функции в SQL и как они работают?
Агрегатные функции в SQL используются для выполнения операций над набором данных, которые возвращают единственный результат. К таким функциям относятся: COUNT (подсчет строк), SUM (сумма значений), AVG (среднее значение), MIN (минимальное значение), MAX (максимальное значение). Они часто используются в сочетании с оператором GROUP BY, чтобы обрабатывать данные по группам. Например, можно подсчитать количество сотрудников в каждом отделе или вычислить среднюю зарплату в компании.
Как применяются агрегатные функции для анализа данных в SQL?
Агрегатные функции полезны для выполнения статистических вычислений и анализа данных. Например, с их помощью можно находить максимальные и минимальные значения в таблице, рассчитывать сумму или среднее значение по группам. Часто такие функции применяются при составлении отчетов или анализе больших объемов данных, например, для расчета общего дохода компании по регионам или средней температуры в разных городах. Используя агрегатные функции, можно быстро получить сводные данные без необходимости вручную обрабатывать все записи.
Какие ограничения существуют при использовании агрегатных функций в SQL?
При использовании агрегатных функций необходимо учитывать, что они не могут работать с NULL-значениями, если не предусмотрено специально обработка этих значений. Например, в функции SUM не будут учитываться NULL. Также агрегатные функции обычно применяются в контексте оператора GROUP BY, который группирует данные по определенному столбцу. Без этого оператора агрегатные функции могут работать только с полными данными таблицы. Кроме того, они могут быть ресурсоемкими при обработке очень больших объемов данных.
Какая разница между функциями COUNT и SUM в SQL?
Функции COUNT и SUM выполняют разные задачи в SQL. COUNT подсчитывает количество строк, которые соответствуют определенному условию, включая строки с NULL, если это не исключено в запросе. Эта функция полезна для подсчета количества записей в таблице или в группе. В свою очередь, SUM суммирует значения в числовых столбцах, игнорируя NULL, что позволяет вычислять общую сумму для группы или всей таблицы. Например, с помощью COUNT можно посчитать количество сотрудников, а с помощью SUM — вычислить общую сумму продаж.
Как можно использовать агрегатные функции для вычисления средней зарплаты в SQL?
Для вычисления средней зарплаты в SQL обычно используется функция AVG. Например, если в таблице сотрудников есть столбец с зарплатами, запрос будет выглядеть так: `SELECT AVG(зарплата) FROM сотрудники;`. Этот запрос вернет среднее значение зарплат по всем сотрудникам. Если необходимо посчитать среднюю зарплату по группам, например, по отделам, можно использовать GROUP BY: `SELECT отдел, AVG(зарплата) FROM сотрудники GROUP BY отдел;` Такой запрос вернет среднюю зарплату для каждого отдела.