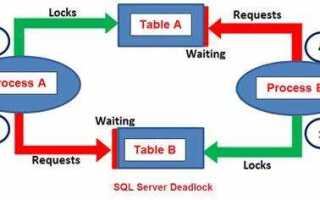
Deadlock (в переводе с английского – «мертвая блокировка») – это ситуация в базе данных, когда два или более процесса (транзакции) блокируют друг друга, ожидая освобождения ресурсов, которые уже заблокированы другими процессами. В результате ни одна из транзакций не может продолжить выполнение, что приводит к заторам в системе и снижению её производительности.
Одним из распространенных примеров deadlock является ситуация, когда транзакция A блокирует запись, которую транзакция B пытается изменить, в то время как транзакция B блокирует запись, которую транзакция A пытается изменить. В этом случае обе транзакции находятся в ожидании ресурсов друг друга, что и приводит к мертвой блокировке.
Для предотвращения deadlock важно понимать основные принципы, такие как порядок блокировки ресурсов, использование уровня изоляции транзакций и мониторинг блокировок. Например, чтобы минимизировать вероятность deadlock, можно устанавливать блокировки в одном и том же порядке, независимо от того, какие ресурсы запрашиваются. Это позволит избежать циклической зависимости между транзакциями.
Для улучшения производительности и надежности работы базы данных, также стоит настроить тайм-ауты для транзакций. В случае, если транзакция не может быть выполнена в течение заданного времени, её можно принудительно прервать, что позволит избежать затора и снизить риски deadlock.
В SQL-серверах существует множество инструментов для диагностики и предотвращения deadlock, таких как использование журналов блокировок, анализ планов запросов и применение функций, позволяющих отслеживать текущие блокировки и их длительность. Эти практики помогают эффективно управлять конкурентным доступом к данным и минимизировать риск возникновения deadlock.
Как deadlock влияет на производительность базы данных?
Deadlock возникает, когда два или более процесса в базе данных блокируют друг друга, ожидая ресурсы, которые заблокированы противоположным процессом. Это приводит к значительному снижению производительности, так как не только затормаживаются текущие запросы, но и возникает необходимость в дополнительных вычислениях для разрешения ситуации.
Когда в системе происходит deadlock, база данных вынуждена завершить один из процессов, чтобы разблокировать ресурсы. Это приводит к потере времени на повторную попытку выполнения операции и может нарушить целостность данных. Если deadlock происходит часто, это увеличивает нагрузку на сервер, снижая его способность обрабатывать запросы.
Пример: если два транзакционных запроса пытаются одновременно обновить одну и ту же строку в таблице, но каждый процесс ожидает, пока второй освободит ресурсы, оба запроса зависают. Это не только замедляет выполнение текущих операций, но и увеличивает вероятность возникновения блокировок в будущем, особенно при высоких нагрузках.
Для минимизации влияния deadlock на производительность можно применить следующие подходы:
1. Правильное проектирование транзакций: уменьшение длительности транзакций и выполнение их как можно быстрее снижает вероятность блокировок.
2. Порядок захвата ресурсов: всегда придерживайтесь фиксированного порядка доступа к таблицам или строкам. Это позволяет уменьшить вероятность циклических зависимостей, ведущих к deadlock.
3. Использование уровней изоляции: на выбор подходящего уровня изоляции влияет количество блокировок, что может снизить риск deadlock. Для простых операций можно использовать уровень «Read Committed», который минимизирует вероятность блокировок.
4. Мониторинг и оптимизация запросов: настройка инструментов мониторинга для отслеживания deadlock-ситуаций помогает оперативно выявлять и устранять причины их возникновения.
При отсутствии должной оптимизации deadlock может стать причиной значительных потерь в производительности, что особенно критично для высоконагруженных систем. Устранение deadlock позволяет повысить скорость выполнения запросов, уменьшить время отклика системы и обеспечить более эффективное использование ресурсов.
Причины возникновения deadlock в SQL-запросах
Deadlock в SQL-запросах происходит, когда два или более процесса блокируют друг друга, ожидая освобождения ресурсов, которые они сами держат. Это приводит к состоянию, в котором ни один из процессов не может завершиться. Основные причины deadlock в SQL-запросах следующие:
1. Порядок блокировок. Если два запроса захватывают блокировки на разных объектах в разном порядке, может возникнуть deadlock. Например, процесс A блокирует таблицу X, а затем пытается получить блокировку на таблице Y, в то время как процесс B уже захватил блокировку на Y и ожидает блокировку на X.
2. Длительные транзакции. Когда транзакция длится слишком долго, она увеличивает вероятность того, что другие запросы будут ожидать освобождения ресурсов. Это особенно актуально при наличии большого количества операций чтения и записи в рамках одной транзакции.
3. Высокая степень параллельности. Когда множество процессов одновременно пытаются получить доступ к базе данных, особенно в сложных запросах, это может привести к ситуации, когда ресурсы блокируются друг другом. Наличие нескольких запросов, использующих одни и те же ресурсы, но в разном порядке, часто вызывает deadlock.
4. Неоптимизированные запросы. Запросы с большими выборками или сложными операциями могут задерживать освобождение блокировок, создавая условия для deadlock. Например, запросы с большим числом джоинов, подзапросов или агрегаций могут занимать значительное время, в течение которого блокируются таблицы.
5. Взаимная зависимость между транзакциями. Deadlock часто возникает, когда несколько транзакций пытаются обновить одни и те же строки, но в другом порядке. Например, если транзакция A изменяет строку 1, а транзакция B – строку 2, после чего A пытается изменить строку 2, а B – строку 1, ни одна из транзакций не сможет завершиться.
6. Проблемы с уровнем изоляции транзакций. Использование более строгих уровней изоляции, таких как SERIALIZABLE, может увеличить вероятность deadlock. Это связано с тем, что такие уровни изоляции требуют, чтобы блокировки были удерживаемы дольше, что повышает шансы на создание взаимных зависимостей между транзакциями.
7. Невозможность предварительного анализа блокировок. В некоторых системах управления базами данных (СУБД) невозможно заранее предсказать, какие блокировки будут захвачены в процессе выполнения запроса, что делает deadlock трудным для предотвращения в реальном времени. Например, если запрос использует динамическое изменение структуры выборки, это может привести к неожиданным блокировкам.
Как обнаружить deadlock в системе?
Обнаружение deadlock в SQL-системах критично для обеспечения стабильности и производительности. Важно знать, как можно выявить блокировки, чтобы своевременно реагировать на проблему. Рассмотрим основные способы диагностики deadlock.
- Инструменты мониторинга. Для обнаружения deadlock можно использовать различные утилиты и панели мониторинга. Например, в SQL Server есть инструмент SQL Server Profiler, который позволяет отслеживать блокировки в реальном времени и записывать события, связанные с deadlock. В PostgreSQL можно использовать расширение
pg_stat_activity, чтобы мониторить активные запросы и их блокировки. - Настройка детекторов deadlock. Многие СУБД поддерживают автоматическое обнаружение deadlock. Например, в SQL Server существует параметр
deadlock_priority, который позволяет приоритетно завершать одну из транзакций в случае deadlock. В PostgreSQL можно настроить параметрlog_lock_waits, чтобы логировать ситуации, когда запросы ожидают блокировки. - Анализ трассировки стека. В случае deadlock можно использовать трассировку стека для понимания того, какие именно запросы блокируют друг друга. Это помогает выявить взаимные зависимости между процессами и облегчить решение проблемы.
- Повторные попытки и тайм-ауты. Многие системы предоставляют возможности для настройки тайм-аутов на запросы. Например, в MySQL можно установить
innodb_lock_wait_timeoutдля автоматического завершения транзакции, если она ожидает блокировку слишком долго. Эти параметры позволяют избегать ситуации, когда система полностью зависает из-за deadlock.
Внедрение таких методов диагностики помогает не только обнаружить deadlock, но и предотвратить его появление в будущем. Применение таких подходов в сочетании с хорошими практиками проектирования базы данных значительно повышает стабильность и производительность системы.
Использование механизма тайм-аутов для предотвращения deadlock
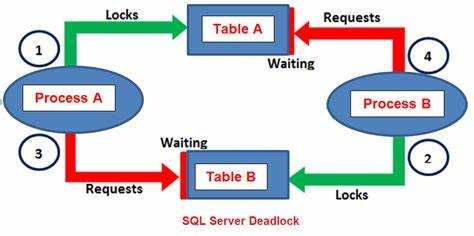
Тайм-ауты – один из эффективных инструментов для предотвращения deadlock в SQL-системах. Механизм тайм-аутов позволяет задать максимальное время ожидания для транзакции, после чего она автоматически прерывается, если не удалось завершить все операции. Это не устраняет сам deadlock, но позволяет минимизировать его влияние, предотвращая зависание системы.
Для реализации тайм-аутов важно правильно настроить параметры базы данных. В большинстве СУБД можно указать максимальное время для блокировки ресурсов или для выполнения транзакции. Например, в MySQL параметр innodb_lock_wait_timeout управляет временем ожидания транзакции, которое по умолчанию составляет 50 секунд. При превышении этого времени транзакция будет автоматически отменена, предотвращая зависание системы.
С другой стороны, SQL Server использует параметр LOCK_TIMEOUT, который позволяет задать временное ограничение на блокировки. Если транзакция не может захватить необходимые ресурсы в пределах заданного времени, она будет завершена с ошибкой, что позволяет системе продолжить обработку других запросов.
Важно помнить, что тайм-ауты должны быть настроены с учетом специфики приложения и нагрузки на базу данных. Слишком короткие тайм-ауты могут привести к преждевременным прерываниям транзакций, в то время как слишком длинные – не решат проблему deadlock, так как транзакции будут продолжать ожидание блокировки, создавая потенциальные точки зависания.
Для минимизации негативного воздействия тайм-аутов на производительность рекомендуется также анализировать и оптимизировать запросы, снижая вероятность их длительного выполнения. Например, можно использовать индексы для ускорения поиска и минимизации времени блокировок, а также тщательно планировать порядок выполнения транзакций.
Таким образом, использование тайм-аутов в сочетании с грамотной настройкой и оптимизацией запросов является важным шагом к снижению риска возникновения deadlock в SQL-системах, обеспечивая надежную работу и повышение производительности базы данных.
Как правильно проектировать транзакции, чтобы избежать deadlock?
Deadlock возникает, когда несколько транзакций блокируют друг друга, ожидая освобождения ресурсов. Чтобы минимизировать вероятность взаимоблокировок, необходимо учитывать следующие аспекты при проектировании транзакций:
- Всегда блокируйте объекты в одном и том же порядке. Если одна транзакция сначала обновляет таблицу A, а затем таблицу B, все остальные транзакции должны соблюдать тот же порядок.
- Минимизируйте объем операций внутри транзакции. Чем меньше данных обрабатывает транзакция, тем короче время удержания блокировок и ниже риск пересечений с другими транзакциями.
- Разделяйте операции чтения и записи. По возможности выполняйте все SELECT-запросы до начала UPDATE/INSERT/DELETE, чтобы избежать эскалации блокировок и конфликта с другими транзакциями.
- Избегайте пользовательского ввода и внешних API-вызовов внутри транзакций. Такие задержки увеличивают продолжительность блокировок и вероятность конкуренции за ресурсы.
- Используйте явное управление уровнем изоляции. Для операций, не требующих строгой консистентности, выбирайте уровень READ COMMITTED или SNAPSHOT, чтобы избежать блокировок на чтение.
- Предпочитайте фильтрацию по индексируемым колонкам в условиях WHERE. Это снижает число заблокированных строк и ускоряет выполнение транзакции.
- Избегайте UPDATE или DELETE без условий или с условиями, охватывающими большое число строк. Такие транзакции блокируют значительные объемы данных и увеличивают риск deadlock.
- Используйте TRY-CATCH блоки и повторный запуск транзакции при обнаружении deadlock. SQL Server, например, возвращает ошибку 1205 при взаимоблокировке, и повторная попытка часто проходит успешно.
Правильная структура транзакций – ключ к высокой доступности и предсказуемости поведения системы в условиях конкурентной нагрузки.
Использование индексов и их влияние на возникновение deadlock

Неправильное использование индексов может существенно повысить вероятность возникновения взаимоблокировок. Когда индексы отсутствуют или неэффективны, SQL-сервер вынужден выполнять полноскановые чтения строк (table scan), что приводит к захвату большего количества блокировок. Это увеличивает время удержания блокировок и расширяет область конкуренции между транзакциями.
Например, при отсутствии индекса по колонке, участвующей в условии WHERE, запрос блокирует множество строк, даже если фактически изменяется или читается только одна. При параллельном выполнении аналогичных операций это резко повышает риск перекрестных блокировок.
Индексы особенно важны при выполнении операций UPDATE и DELETE. Если фильтрация строк производится по неиндексированному полю, блокировки могут применяться ко всем строкам таблицы, в отличие от узконаправленного доступа при наличии подходящего индекса. Это приводит к увеличению длительности транзакций и росту вероятности deadlock.
Использование покрывающих индексов позволяет минимизировать число читаемых страниц и избежать эскалации блокировок. Такие индексы включают все поля, используемые в запросе, включая SELECT, WHERE и JOIN. Это снижает вероятность блокировок на уровне строк и страниц.
Важно регулярно анализировать планы выполнения запросов. Если сканирование выполняется вместо поиска по индексу, это сигнал к необходимости его оптимизации или пересмотра структуры запроса. Также следует избегать создания избыточных или перекрывающихся индексов – это увеличивает издержки на обновление данных и может провоцировать внутренние конфликты блокировок.
Для снижения вероятности deadlock критически важно проектировать индексы, исходя из сценариев конкурентного доступа, а не только из соображений производительности. Оптимизированные индексы уменьшают объем заблокированных данных и минимизируют вероятность перекрестного ожидания ресурсов между транзакциями.
Инструменты для анализа и устранения deadlock в SQL-сервере
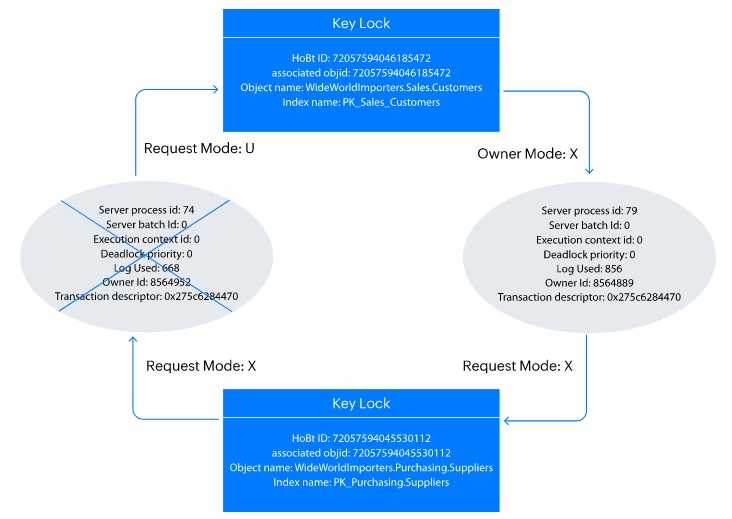
Для выявления deadlock в Microsoft SQL Server используйте трассировку событий с помощью Extended Events. Создайте сессию, включающую события xml_deadlock_report и deadlock_graph. Это позволит зафиксировать структуру блокировки, идентификаторы процессов, ресурсы и T-SQL-команды, вызвавшие конфликт.
Журнал ошибок SQL Server также фиксирует сведения о deadlock, если включено логирование. Настройка параметра сервера trace flag 1222 позволяет получить подробный граф в текстовом виде. Он отображает цепочку блокировок и порядок ожидания ресурсов, что помогает точно определить виновника и сценарий возникновения deadlock.
В SQL Server Management Studio (SSMS) используйте вкладку «Activity Monitor» и запрос sys.dm_tran_locks для отслеживания текущих блокировок. Совместно с sys.dm_os_waiting_tasks можно установить, какие задачи заблокированы и чего ожидают.
Для автоматизированного анализа используйте SQL Server Profiler, задав фильтр на событие Deadlock graph. Полученный граф можно визуализировать, чтобы увидеть узлы и взаимные зависимости между сессиями. Это особенно полезно при высоконагруженных системах с множественными параллельными транзакциями.
Для устранения deadlock пересмотрите порядок доступа к объектам в транзакциях. Если невозможно изменить бизнес-логику, используйте блокировку с тайм-аутом через параметр SET LOCK_TIMEOUT, чтобы избежать взаимных ожиданий. Также помогает разбиение операций на более мелкие транзакции или использование оптимистичной блокировки (snapshot isolation).