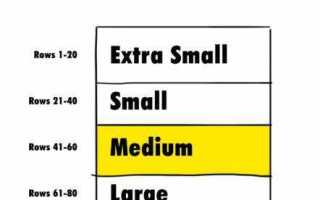
Кардинальное число в SQL обозначает количество строк, возвращаемых запросом в базе данных. Это ключевое понятие для оценки эффективности выполнения запросов и оптимизации работы с данными. В зависимости от сложности запроса, его кардинальное число может быть как маленьким, так и достаточно большим, что влияет на время выполнения операций и использование ресурсов системы.
Кардинальное число играет важную роль при проектировании запросов, особенно когда речь идет о JOIN операциях, группировке данных и агрегации. Например, при использовании INNER JOIN, кардинальное число может быть скорректировано на основе количества строк в каждой из участвующих таблиц. Это важный момент, который стоит учитывать для предотвращения ненужных вычислений и избыточных данных в результате.
Практически каждый разработчик сталкивается с необходимостью оценить кардинальность данных, чтобы улучшить производительность. Например, использование DISTINCT для устранения дублирующихся записей может существенно снизить кардинальное число в случае работы с большими объемами данных, что напрямую сказывается на скорости выполнения запроса.
Для эффективной работы с кардинальными числами важно учитывать индексирование, так как правильное индексирование может уменьшить нагрузку на систему при запросах с большим кардинальным числом. Индексы могут ускорить выборку строк, уменьшив время выполнения сложных запросов.
Как кардинальное число влияет на производительность запросов

Кардинальное число в SQL определяет количество уникальных значений в столбце. Это значение напрямую влияет на производительность запросов, особенно при выполнении операций фильтрации, сортировки и объединения данных.
Влияние кардинального числа зависит от нескольких факторов:
- Индексы: Если столбец с высоким кардинальным числом проиндексирован, это значительно ускоряет поиск данных. Однако для столбцов с низким кардинальным числом индекс может быть менее эффективным из-за большого количества дублирующихся значений.
- Запросы с группировкой: При агрегации данных запросы по столбцам с низким кардинальным числом (например, если значения повторяются часто) выполняются быстрее. В то время как столбцы с высоким кардинальным числом могут привести к необходимости обработать больше уникальных значений, что замедляет выполнение.
- Объединение таблиц: В операциях JOIN, где участвуют столбцы с высоким кардинальным числом, требуется больше времени на сопоставление значений. Это может привести к увеличению объема данных, которые нужно обработать и передать между таблицами.
- Оптимизация запросов: Использование кардинального числа может помочь в оптимизации запросов. Например, если в запросе участвуют фильтры на столбцы с высокой уникальностью, это позволяет СУБД быстрее сократить количество обрабатываемых строк.
Рекомендации для повышения производительности:
- Использовать индексы на столбцах с высоким кардинальным числом для ускорения поиска.
- Ограничивать использование JOIN на столбцах с высоким кардинальным числом, если это не критично для запроса.
- Агрегировать данные по столбцам с низким кардинальным числом, чтобы уменьшить время обработки.
- Использовать статистику кардинальности для планирования запросов и оптимизации работы СУБД.
Примеры использования кардинальных чисел в SQL-запросах
Кардинальные числа в SQL часто применяются для задания ограничений на количество строк, которые возвращает запрос. Это позволяет контролировать объем данных, с которым работает система. Рассмотрим несколько примеров их использования.
Пример 1: Ограничение выборки с помощью LIMIT (для MySQL, PostgreSQL)
Для того чтобы ограничить количество строк, возвращаемых запросом, используется директива LIMIT. Это особенно полезно, если нужно получить только первые несколько записей из результата.
SELECT name, age FROM users LIMIT 10;
Этот запрос вернет первые 10 записей из таблицы users.
Пример 2: Ограничение с помощью FETCH FIRST (для SQL Server, Oracle)
В SQL Server и Oracle для ограничения количества строк используется директива FETCH FIRST. Она более гибка и позволяет также указать сортировку для выборки.
SELECT name, age FROM users ORDER BY age DESC FETCH FIRST 5 ROWS ONLY;
Этот запрос вернет 5 записей, отсортированных по убыванию возраста.
Пример 3: Использование кардинального числа для пагинации
При пагинации кардинальные числа позволяют управлять страницами данных. Для этого обычно применяются LIMIT и OFFSET (или их аналоги в других СУБД).
SELECT name, age FROM users LIMIT 10 OFFSET 20;
Пример 4: Ограничение выборки на основе агрегатных функций
Кардинальные числа можно использовать и в сочетании с агрегатными функциями, чтобы выбрать только ограниченное количество результатов.
SELECT department, COUNT(*) FROM employees GROUP BY department HAVING COUNT(*) > 10;
Здесь мы выбираем только те департаменты, где количество сотрудников больше 10.
Пример 5: Ограничение выборки с помощью TOP (для SQL Server)
В SQL Server для получения ограниченного количества строк используется конструкция TOP. Это позволяет выбирать первые N строк на основе сортировки или других условий.
SELECT TOP 5 name, salary FROM employees ORDER BY salary DESC;
Этот запрос вернет 5 сотрудников с наибольшими зарплатами.
Как вычислить кардинальное число для разных типов данных
Кардинальное число для столбца в SQL обозначает количество уникальных значений в этом столбце. Вычисление этого числа зависит от типа данных, который используется в столбце. Рассмотрим методы вычисления кардинального числа для разных типов данных.
Для числовых типов данных, таких как INT, FLOAT или DECIMAL, кардинальное число можно определить с помощью функции COUNT(DISTINCT). Эта функция подсчитывает количество уникальных значений в столбце. Например, запрос:
SELECT COUNT(DISTINCT column_name) FROM table_name;Этот запрос вернёт количество уникальных чисел в столбце column_name. Для числовых данных важно учитывать, что NULL значения не учитываются в подсчете уникальных значений.
Для строковых типов данных, таких как VARCHAR, TEXT и CHAR, вычисление кардинального числа также выполняется через COUNT(DISTINCT). Важно помнить, что строки с разными регистрами считаются уникальными. Например, «apple» и «Apple» будут считаться двумя разными значениями.
Для дат и временных типов данных, например, DATE, DATETIME и TIMESTAMP, вычисление кардинального числа также производится с использованием COUNT(DISTINCT). Однако, стоит учитывать, что точность временных значений может повлиять на результат. Например, два значения '2025-04-22 10:00:00' и '2025-04-22 10:00:01' будут считаться уникальными, если различаются хотя бы в миллисекундах.
Для типов данных BOOLEAN или BIT кардинальное число обычно ограничено двумя значениями: TRUE и FALSE. В этом случае результат всегда будет равен 1 или 2, в зависимости от наличия уникальных значений в столбце.
При работе с большими данными может понадобиться оптимизация запросов для ускорения вычисления кардинального числа, например, использование индексов на столбцах или предварительное вычисление статистики. Это поможет избежать значительных затрат ресурсов при выполнении операций на больших объемах данных.
Проблемы, возникающие при неверном применении кардинального числа
Неверные связи между таблицами – это ещё одна проблема, с которой можно столкнуться при ошибочном применении кардинального числа. Когда кардинальное число неправильно настроено для связей между таблицами, это может вызвать как избыточные, так и пропущенные данные, что нарушает логику работы системы. Например, неправильное использование связей «один ко многим» вместо «многие ко многим» может привести к искажению информации.
Проблемы с производительностью часто возникают, когда запросы с неверным кардинальным числом пытаются обработать слишком большое количество данных за один раз. В таких случаях нагрузка на базу данных значительно увеличивается, что может замедлить выполнение операций и вызвать сбои. Если не учесть ограничения по кардинальному числу, индексирование таблиц может стать неэффективным, что замедлит работу всей системы.
Ошибки в логике работы приложения могут стать следствием неправильной интерпретации кардинальных чисел при реализации бизнес-логики. В случае, когда неправильно определено, сколько записей должно быть связано с объектом, приложение может не учесть важные данные или, наоборот, получить ненужные записи. Это приводит к логическим ошибкам, влияющим на пользовательский опыт и точность работы приложения.
Для предотвращения этих проблем важно тщательно проверять все отношения между таблицами и убедиться в корректности определения кардинальных чисел в запросах. Рекомендуется использовать подходы нормализации данных и регулярные тесты на целостность базы данных, чтобы минимизировать риск возникновения ошибок.
Как кардинальное число помогает в оптимизации индексов
Кардинальное число в контексте SQL указывает на количество уникальных значений в столбце. Оно играет важную роль в оптимизации индексов, так как позволяет системе управления базами данных (СУБД) принимать решения, влияющие на эффективность запросов.
При создании индекса СУБД учитывает кардинальное число для выбора типа индекса и стратегии его использования. Когда в столбце присутствует много уникальных значений, индекс на таком столбце будет более эффективным, так как позволяет быстро найти нужные данные. В таких случаях используется B-дерево или хеширование для ускорения поиска.
Если кардинальное число низкое, например, в столбце с ограниченным числом категорий (меньше 10 значений), создание индекса может быть нецелесообразным. СУБД может решить, что индекс не принесет значительного улучшения производительности, и вместо этого использовать таблицу с полной сканированием, что бывает быстрее на маленьких данных.
Оптимизация индексов зависит также от распределения данных. В случае, когда кардинальное число столбца высоко, важно также учитывать статистику по частоте появления значений. Если большинство значений встречается часто, индекс все равно может быть неэффективен из-за «перегрузки» данных, что приведет к дополнительным операциям для обработки таких случаев.
Для колонок с высоким кардинальным числом и большим объемом данных рекомендуется применять индекс с поддержкой сжатия или фильтрации. Это позволяет уменьшить размер индекса и повысить его эффективность при поиске и обновлении данных.
Кардинальное число помогает также при планировании обновлений индекса. СУБД может прогнозировать, как изменение кардинального числа (например, добавление нового уникального значения) повлияет на скорость выполнения запросов и необходимость перерасчета индекса.
Рекомендации по настройке кардинальных чисел для крупных баз данных

При работе с крупными базами данных кардинальные числа играют важную роль в определении оптимальных планов выполнения запросов. Настройка кардинальных чисел позволяет СУБД точно оценивать количество строк в таблицах и их отношениях, что влияет на выбор индексов и порядок соединений. Для баз данных с миллионами и более строк важно правильно определить эти значения.
1. Использование статистики. Регулярное обновление статистики позволяет СУБД точнее определять кардинальные числа. В случае крупных таблиц статистика должна обновляться хотя бы раз в неделю или чаще, если данные сильно меняются.
2. Учет скоординированных данных. Если в базе данных присутствуют очень большие таблицы с высокой корреляцией между полями, кардинальные числа могут значительно отличаться от реальных значений. В таких случаях полезно использовать специальные функции для анализа статистики или вручную корректировать данные с учетом фактических зависимостей.
3. Индексы. Для таблиц с большим количеством строк, создание индексов, особенно на колонках, используемых для фильтрации или сортировки, может существенно улучшить точность кардинальных чисел. Индексы позволяют ускорить операции подсчета строк и повышают точность оценки кардинальности.
4. Использование расширенных возможностей СУБД. Например, в PostgreSQL или SQL Server можно использовать опции для ручного задания кардинальных чисел в случаях, когда автоматическая оценка недостаточно точна.
5. Прогнозирование кардинальных чисел. В некоторых случаях для оптимизации работы с большими объемами данных полезно применять методы прогнозирования. Использование предсказанных значений кардинальности может значительно ускорить выполнение запросов, особенно в распределенных базах данных.
6. Разделение таблиц. При работе с большими данными, разумное разделение таблиц на партиции по определенным критериям позволяет уменьшить ошибочность кардинальных чисел, так как СУБД работает с меньшими объемами данных. Это особенно актуально для таблиц, которые часто обновляются или используют сложные соединения.
7. Мониторинг производительности. Настроенные кардинальные числа должны постоянно отслеживаться для оценки производительности запросов. Если система замечает, что реальные данные сильно расходятся с ожидаемыми, необходимо пересмотреть статистику и кардинальные числа для дальнейшей оптимизации.
Вопрос-ответ:
Что такое кардинальное число в SQL?
Кардинальное число в SQL – это количество уникальных значений в столбце таблицы. Оно позволяет определить, сколько различных значений присутствуют в указанном поле. Обычно кардинальное число используется для оптимизации запросов и анализа данных.
Как в SQL узнать кардинальное число для столбца?
Для получения кардинального числа столбца в SQL используется функция COUNT DISTINCT. Пример запроса: `SELECT COUNT(DISTINCT column_name) FROM table_name;`. Этот запрос возвращает количество уникальных значений в указанном столбце.
Зачем нужно использовать кардинальное число в SQL запросах?
Использование кардинального числа в SQL помогает определить, сколько уникальных значений содержит столбец, что важно для аналитики и оптимизации запросов. Оно может быть полезным при поиске дублирующихся данных или при необходимости упорядочить выборку по количеству уникальных записей.
Какие проблемы могут возникнуть при расчете кардинального числа в SQL?
При расчете кардинального числа могут возникнуть проблемы, связанные с большими объемами данных. Например, при использовании функции COUNT DISTINCT для таблиц с миллионами записей могут существенно увеличиться время выполнения запроса и нагрузка на сервер. В таких случаях можно рассмотреть использование индексов или более оптимизированных методов обработки данных.
Как кардинальное число влияет на производительность запросов в SQL?
Кардинальное число влияет на производительность запросов, так как операция подсчета уникальных значений может требовать значительных ресурсов при большом объеме данных. Чем больше уникальных значений в столбце, тем больше времени может занять выполнение запроса с COUNT DISTINCT. Для оптимизации стоит использовать индексы, особенно если нужно часто выполнять такие запросы.
Что такое кардинальное число в SQL?
Кардинальное число в SQL — это количество строк, которые могут быть возвращены запросом. Например, если запрос выбирает все записи из таблицы, то кардинальное число будет равно количеству этих записей. В контексте оператора DISTINCT оно определяет количество уникальных значений в столбце или наборе столбцов.