Нормализация базы данных – это методология, направленная на организацию данных таким образом, чтобы минимизировать избыточность и предотвратить аномалии при вставке, обновлении и удалении данных. Процесс нормализации включает в себя разбиение больших таблиц на более мелкие, что улучшает структуру базы данных и делает её более гибкой и масштабируемой. Особенно важно соблюдать баланс между нормализацией и производительностью, так как чрезмерная нормализация может повлиять на скорость работы запросов.
Основная цель нормализации – это устранение дублирования информации, что снижает потребность в обновлениях данных, предотвращая возможные несоответствия в различных частях базы данных. Это достигается путем введения дополнительных таблиц и установления четких связей между ними, что позволяет обеспечить целостность данных. Однако стоит помнить, что каждая степень нормализации требует внимательного анализа, поскольку увеличение количества таблиц может затруднить выполнение сложных запросов.
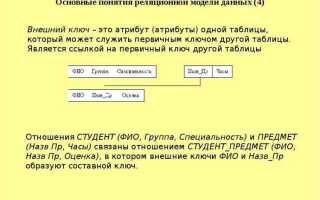
Процесс нормализации обычно включает несколько стадий, от первой нормальной формы (1NF) до пятой (5NF), каждая из которых решает определенные задачи по устранению избыточности. Однако на практике чаще всего используют нормализацию до третьей нормальной формы (3NF), так как она сочетает оптимизацию с допустимыми затратами на выполнение запросов. Для большинства бизнес-приложений этого уровня нормализации вполне достаточно, чтобы обеспечить эффективное хранение данных и их обработку.
Важно: При проектировании базы данных необходимо также учитывать характер запросов, которые будут выполняться. В некоторых случаях может быть оправдано создание денормализованных таблиц или использование индексов для ускорения чтения данных, особенно если система требует высокой производительности при больших объемах информации.
Рекомендация: Прежде чем приступать к нормализации, стоит четко определить требования к системе и проводить анализ типичных запросов, чтобы избежать излишней сложности в проектировании и последующих проблем с производительностью.
Что такое нормализация базы данных и зачем она нужна?
Нормализация основывается на разбиении данных на связанные таблицы, каждая из которых фокусируется на отдельной категории данных. Это снижает количество повторяющихся данных и повышает эффективность запросов.
Зачем нужна нормализация?
- Избежание избыточности данных. При неправильной структуре базы данных может возникнуть ситуация, когда одинаковая информация хранится в нескольких местах, что увеличивает объём хранимых данных и вероятность ошибок при их обновлении.
- Упрощение обновлений. Если данные структурированы правильно, то изменения, например, в адресе клиента, необходимо вносить только в одном месте. Это ускоряет процесс внесения изменений и исключает несоответствия данных в разных частях базы.
- Снижение вероятности аномалий данных. Избыточность может приводить к различным аномалиям: дублированию, несоответствиям и инконсистентности. Нормализация помогает свести эти риски к минимуму.
- Увеличение производительности. Нормализованные данные требуют меньшего объема памяти и могут быть более эффективно обработаны сервером, так как каждый запрос взаимодействует с меньшими объемами данных.
Процесс нормализации делится на несколько форм, каждая из которых решает определённые проблемы:
- Первая нормальная форма (1NF): Каждое поле в таблице должно содержать атомарные (неделимые) значения, а сама таблица – уникальные строки. Это решает проблему многозначных атрибутов.
- Вторая нормальная форма (2NF): Все атрибуты, которые не являются частью первичного ключа, должны зависеть от всего ключа. Это устраняет частичные зависимости.
- Третья нормальная форма (3NF): Каждое ненулевое поле должно зависеть только от первичного ключа. Это помогает избежать транзитивных зависимостей.
Применение нормализации помогает создать более гибкую, масштабируемую и логичную структуру базы данных, что в свою очередь повышает её надёжность и эффективность при работе с большими объёмами данных.
Основные формы нормализации: от 1NF до 5NF
Нормализация базы данных представляет собой процесс организации данных таким образом, чтобы минимизировать избыточность и улучшить их структуру для эффективного хранения и извлечения. В SQL нормализация происходит через ряд форм, каждая из которых решает специфические проблемы с данными. Рассмотрим основные формы нормализации от 1NF до 5NF.
1NF (Первая нормальная форма)

1NF требует, чтобы все атрибуты в таблице содержали атомарные (неделимые) значения. Это означает, что каждый столбец должен содержать только одно значение для каждой строки, а не набор значений или список.
- Удаляются повторяющиеся группы данных.
- Каждый столбец таблицы должен быть уникален и содержать данные одного типа.
Пример: если у вас есть столбец с несколькими номерами телефонов, их нужно разделить на несколько столбцов или создать отдельную таблицу для телефонов.
2NF (Вторая нормальная форма)
Для достижения 2NF необходимо, чтобы таблица была в 1NF и все неключевые атрибуты зависели от полного первичного ключа. Это устраняет частичные зависимости, когда атрибуты зависят только от части составного ключа.
- Если таблица имеет составной ключ, все неключевые атрибуты должны зависеть от всего ключа.
- Не допускается зависимость только от одной части составного ключа.
Пример: если у вас есть таблица с заказами, в которой зависимость между адресом клиента и номером заказа частично зависит только от номера заказа, таблицу нужно разделить.
3NF (Третья нормальная форма)

Для 3NF таблица должна быть в 2NF, и в ней не должно быть транзитивных зависимостей. Это означает, что неключевые атрибуты не должны зависеть от других неключевых атрибутов.
- Все неключевые атрибуты должны напрямую зависеть от первичного ключа, а не через другие атрибуты.
- Убираются транзитивные зависимости, когда один неключевой атрибут зависит от другого неключевого.
Пример: если в таблице «Сотрудники» есть зависимость между городом и почтовым индексом, это нужно вынести в отдельную таблицу.
BCNF (Нормальная форма Бойса-Кодда)
BCNF является улучшением 3NF. В BCNF каждая детерминирующая переменная должна быть кандидатом в первичный ключ. Это означает, что для каждой функциональной зависимости, левая часть зависимости должна быть уникальным идентификатором строки.
- Каждое детерминирующее множество должно быть суперключом.
- Исключаются случаи, когда атрибуты определяют другие атрибуты, но не являются частью первичного ключа.
Пример: если в таблице о студентах и курсах имеется зависимость между студентом и преподавателем, это требует создания отдельной таблицы для преподавателей и студентов.
4NF (Четвёртая нормальная форма)
4NF решает проблему многозначных зависимостей. Для того чтобы таблица находилась в 4NF, она должна быть в BCNF и не содержать многозначных зависимостей, когда один атрибут зависит от нескольких значений другого атрибута.
- Убираются ситуации, когда один атрибут зависит от множества значений другого атрибута.
- Все многозначные зависимости должны быть приведены к отдельным таблицам.
Пример: если один студент может быть записан на несколько курсов, и каждый курс имеет несколько преподавателей, создаётся новая таблица для записи студентов на курсы и таблица для преподавателей.
5NF (Пятая нормальная форма)
5NF устраняет проблему зависимостей, которые связаны с разложением данных на более мелкие части. Для того чтобы таблица находилась в 5NF, она должна быть в 4NF и не содержать зависимостей, которые можно выразить через объединение.
- Все данные должны быть атомарными и не могут быть разделены дальше.
- 5NF касается ситуации, когда несколько зависимых данных могут быть получены через операции с другими зависимыми данными.
Пример: если один человек может быть одновременно участником нескольких проектов, а проект может включать несколько сотрудников, создаётся отдельная таблица для связи сотрудников и проектов, чтобы исключить избыточность данных.
Как выбрать оптимальный уровень нормализации для конкретной задачи?
Определение уровня нормализации базы данных зависит от множества факторов, включая требования к производительности, частоте обновлений данных и объёму хранимой информации. Важно понимать, что процесс нормализации направлен на устранение избыточности и снижение рисков аномалий при обновлении данных. Однако, излишняя нормализация может привести к ухудшению производительности из-за множества JOIN-операций при запросах. Для выбора оптимального уровня нормализации нужно учитывать следующие аспекты:
1. Степень изменения данных
Если в системе часто происходят изменения данных (вставки, обновления, удаления), то высокие формы нормализации (3NF и выше) будут предпочтительнее. Это снижает вероятность аномалий и уменьшает дублирование данных. Однако для систем с редкими изменениями, где важнее быстрые чтения, можно использовать денормализацию, что ускоряет запросы за счёт уменьшения количества соединений таблиц.
2. Частота и тип запросов
Если запросы преимущественно ориентированы на извлечение данных с множеством соединений, нормализация до 3NF обеспечит чистоту структуры и уменьшит избыточность, но приведёт к необходимости использования сложных JOIN-запросов. Для систем с большим количеством отчётов или сложных запросов оптимальным решением может стать нормализация до 3NF, с минимальной денормализацией для ускорения чтения данных. В случае простых запросов, с небольшой нагрузкой на базу данных, можно применить более низкие формы нормализации (1NF или 2NF).
3. Масштабируемость системы
При проектировании базы данных для большого объёма данных или для распределённых систем нормализация до 3NF или выше помогает избежать избыточности и упрощает поддержание целостности данных. В распределённых системах с высокими требованиями к скорости записи и чтения часто используется комбинация нормализованных и денормализованных таблиц, чтобы сбалансировать целостность данных и производительность.
4. Потребности в целостности данных
Если требования к целостности данных являются приоритетом, более высокая степень нормализации будет предпочтительнее. Например, в банковских или медицинских системах важно минимизировать ошибки, связанные с избыточностью данных, поэтому нормализация до 3NF и выше поможет обеспечить строгие ограничения целостности.
5. Размер и сложность базы данных
Для небольших баз данных (до нескольких гигабайт) нормализация до 2NF или 3NF может быть вполне достаточной, и производительность не будет сильно зависеть от дополнительных операций JOIN. В больших системах с миллионами записей нужно учитывать, что высоко нормализованные таблицы могут привести к значительным задержкам из-за большого числа соединений, поэтому здесь может потребоваться денормализация для повышения производительности.
6. Уровень пользовательского взаимодействия
Если в системе предполагается наличие большого числа запросов от конечных пользователей, то нормализация до 3NF или выше помогает обеспечить быстрые и точные ответы. В противном случае, если система предполагает ограниченное количество запросов и фокусируется на редких изменениях данных, можно использовать более низкие уровни нормализации или денормализацию для уменьшения сложности запросов и улучшения скорости работы.
Таким образом, оптимальный уровень нормализации зависит от конкретной задачи, и универсального решения не существует. Важно адаптировать степень нормализации с учётом требований к производительности, целостности данных и масштабируемости системы.
Влияние нормализации на производительность запросов в SQL
Нормализация базы данных часто воспринимается как способ уменьшения избыточности данных, но её влияние на производительность запросов не всегда очевидно. Степень нормализации оказывает существенное воздействие на скорость выполнения запросов и нагрузку на систему. Процесс нормализации сводит к минимуму дублирование данных, что в большинстве случаев улучшает эффективность обновлений, вставок и удаления. Однако для сложных запросов, особенно при использовании объединений (JOIN), нормализация может приводить к необходимости выполнения большего числа операций, что снижает производительность.
На первых этапах нормализации (1NF, 2NF) значительных изменений в производительности обычно не наблюдается, так как структура таблиц остаётся относительно простой. Однако при переходе к 3NF и выше, где создаются дополнительные связи между таблицами, запросы начинают требовать более сложных операций с объединениями. Чем больше таблиц участвует в запросе, тем выше вероятность ухудшения времени отклика, особенно в случае больших объёмов данных.
Чтобы избежать ухудшения производительности, необходимо тщательно продумывать структуру запросов и индексацию. Использование правильных индексов на полях, участвующих в JOIN, может значительно улучшить время выполнения запросов. Индексы позволяют ускорить поиск соответствующих записей, сокращая затраты на объединения. Тем не менее, индексация требует дополнительных затрат на время вставки, удаления и обновления данных, что также следует учитывать при оптимизации базы данных.
Кроме того, при нормализации важно учитывать типы запросов, которые будут выполняться чаще всего. Например, если база данных предполагает множество сложных аналитических запросов, объединяющих множество таблиц, денормализация может оказаться более эффективным решением. В таких случаях целесообразно ограничить нормализацию до 3NF или даже оставить некоторые дублирующиеся данные в целях оптимизации запросов.
Опыт показывает, что баланс между нормализацией и производительностью запросов зависит от специфики задач и объёма данных. В некоторых случаях, например, для OLAP-систем, денормализация и использование материализованных представлений может быть более продуктивным выбором, чем полная нормализация базы данных. Таким образом, выбор стратегии нормализации должен учитывать не только теоретические принципы, но и реальную нагрузку на систему в процессе эксплуатации.
Как избежать излишней нормализации при проектировании базы данных?
Излишняя нормализация может привести к избыточной сложности структуры базы данных, усложнив запросы и снижая производительность. Чтобы избежать этого, важно соблюдать баланс между нормализацией и требованиями производительности системы.
Первым шагом является понимание бизнес-логики. При проектировании базы данных нужно учитывать, какие данные часто обновляются, а какие – редко. Для часто изменяемых данных избыточная нормализация может быть неэффективной, так как приводит к необходимости большого количества JOIN-операций. В таких случаях разумно использовать денормализацию или частичную нормализацию.
Следующий момент – оценка объема данных. Если база данных содержит огромные объемы информации, глубокая нормализация может привести к значительным накладным расходам при выполнении запросов. В таких случаях можно остановиться на 3-й нормальной форме, если этого достаточно для обеспечения целостности данных, или использовать денормализацию для ускорения чтения данных.
Также стоит учитывать типы запросов. Если система требует большого числа сложных аналитических запросов с агрегацией и фильтрацией данных, денормализация может снизить нагрузку на базу данных. В таких случаях избыточное разделение данных может увеличить время выполнения запросов и создать дополнительные проблемы при масштабировании.
Одной из стратегий является использование гибридных моделей, где для критичных данных применяется нормализация, а для редко изменяющихся и часто запрашиваемых данных – денормализация. Также стоит рассматривать использование индексов для оптимизации работы с большим количеством данных.
Наконец, при проектировании базы данных важно поддерживать тесную связь с разработчиками приложения. Это позволит оперативно выявить проблемы производительности и определить, где необходима денормализация для улучшения отклика системы. В идеале проектирование должно быть итеративным процессом с регулярным тестированием производительности.
Практические ошибки при нормализации и как их избежать
Еще одной ошибкой является игнорирование избыточных зависимостей между атрибутами. При проектировании базы данных важно правильно идентифицировать функциональные зависимости и разделять данные таким образом, чтобы исключить повторение информации. Ошибки в определении зависимостей могут привести к аномалиям при обновлениях, вставках или удалениях данных. Для этого необходимо тщательно проанализировать каждое поле и его зависимости от других, а также обеспечить, чтобы эти зависимости были логичными и не нарушали принципы нормализации.
Неправильная обработка частичных зависимостей также является распространенной ошибкой. Частичная зависимость возникает, когда атрибут зависит от части составного ключа, но не от всего ключа. Это приводит к нарушению второй нормальной формы (2NF). Чтобы избежать этой ошибки, важно разделять таблицы таким образом, чтобы каждый атрибут зависел от всего первичного ключа, а не от его части. Например, в таблице с составным ключом следует убедиться, что атрибуты, которые зависят только от одного элемента ключа, переносятся в отдельную таблицу.
Также стоит обратить внимание на несоответствие между нормализацией и производительностью. Иногда, в целях улучшения производительности, базы данных приходится денормализовать, то есть объединять данные, которые изначально были бы разделены по разным таблицам в процессе нормализации. Это может быть оправдано, если приложение работает с большими объемами данных и производительность запросов становится критичной. Однако денормализация должна быть обоснована реальными требованиями к производительности, а не выполнена наугад. Важно провести анализ текущей нагрузки на систему и оценить возможное ухудшение производительности при введении нормализации или денормализации.
Неоправданное добавление уникальных ограничений или сложных связей между таблицами также может привести к излишней жесткости структуры данных. Строгие ограничения на уровне базы данных ограничивают гибкость системы и могут затруднить будущие изменения в модели данных. Важно тщательно взвесить необходимость каждого ограничения, чтобы избежать чрезмерной нагрузки на систему при изменении или расширении функционала.
Для предотвращения таких ошибок нужно подходить к нормализации с учетом специфики бизнеса, реальных требований к данным и нагрузки на систему. Базу данных следует проектировать таким образом, чтобы она была удобной для масштабирования и обслуживания, а не только для выполнения теоретически правильной нормализации. В конечном счете, нормализация должна служить целям, а не становиться самоцелью.
Нормализация и денормализация: когда стоит применить каждую?
Нормализация и денормализация – два противоположных подхода к проектированию базы данных, которые преследуют разные цели. Нормализация направлена на устранение избыточности данных и улучшение их согласованности, тогда как денормализация используется для повышения производительности запросов, часто за счет увеличения дублирования данных.
Нормализация применяется, когда важно избежать аномалий при изменении данных, таких как обновление, удаление или вставка. Она подходит для систем, в которых целостность данных важнее скорости запросов. Этот подход эффективен в условиях сложных транзакций и когда данные подвержены частым изменениям. Например, для финансовых приложений или систем, требующих строгого учета, нормализация помогает поддерживать точность и согласованность данных на всех этапах работы базы.
Денормализация же используется в ситуациях, когда приоритетом является скорость выполнения запросов, а не строгое соблюдение нормальных форм. Этот подход актуален для аналитических систем или тех приложений, где время отклика критично и данные не изменяются слишком часто. Денормализация снижает количество соединений таблиц и позволяет запросам обрабатывать большие объемы данных быстрее. Такой подход широко используется в системах, работающих с большими объемами данных, таких как хранилища данных или системы бизнес-анализа (BI).
Нормализация будет оправдана, если важна высокая степень согласованности и возможность безопасных обновлений. Например, если база данных содержит чувствительную информацию, такую как персональные данные клиентов или сведения о транзакциях, нормализация поможет избежать дублирования данных и облегчить их контроль. В таких случаях изменение данных в одной записи автоматически обновит все связанные записи, что способствует предотвращению ошибок и несоответствий.
С другой стороны, денормализация имеет смысл в случаях, когда база данных содержит часто запрашиваемые данные, требующие быстрого доступа. Например, в электронной коммерции, где нужно часто извлекать и отображать информацию о товарах, заказах и клиентах, денормализация может существенно повысить производительность. Однако, этот подход увеличивает сложность при обновлении данных, поскольку любые изменения могут потребовать синхронизации нескольких копий данных.
В реальных проектах часто используется комбинированный подход: в транзакционных системах предпочтительнее нормализация, а в системах для анализа данных – денормализация. Ключевым моментом является четкое определение требований к системе: если ваша система работает с большим количеством сложных операций записи, нормализация снизит вероятность ошибок. Если же вам необходима скорость обработки больших объемов данных с минимальными задержками, денормализация поможет достичь этой цели, несмотря на увеличение сложности при обновлениях.
Вопрос-ответ:
Что такое нормализация базы данных в SQL и зачем она нужна?
Нормализация базы данных в SQL — это процесс структурирования данных таким образом, чтобы минимизировать избыточность и предотвратить аномалии при обновлении данных. В процессе нормализации используются различные формы нормальных форм, каждая из которых решает конкретные проблемы, такие как зависимость данных или избыточность. Это позволяет улучшить организацию данных и облегчить их поддержку в будущем.
Почему нормализация может негативно повлиять на производительность базы данных?
Хотя нормализация помогает избежать избыточности и аномалий, она может привести к ухудшению производительности, особенно в случае сложных запросов, которые требуют объединения множества таблиц. Нормализованные базы данных часто нуждаются в большем количестве соединений между таблицами, что может замедлить выполнение запросов. В таких случаях иногда используется денормализация, когда избыточные данные сохраняются в таблицах для ускорения запросов.
Когда стоит использовать нормализацию в базе данных, а когда — денормализацию?
Нормализация предпочтительна, когда требуется поддерживать целостность данных, уменьшить избыточность и упростить процессы обновления. Это особенно важно для транзакционных систем, где поддержка актуальности данных является приоритетом. Денормализация, с другой стороны, может быть полезна, если производительность запросов становится критичной, и необходимо уменьшить количество соединений между таблицами. Денормализация помогает ускорить выполнение запросов, но увеличивает риск избыточности и сложности в поддержке данных.