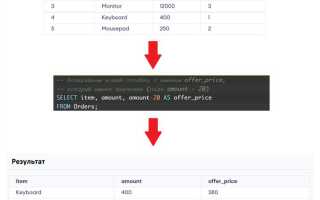
Оператор OVER в SQL представляет собой мощный инструмент, который позволяет выполнять аналитические операции без необходимости использования подзапросов или агрегации. Он используется в сочетании с функциями окна, такими как ROW_NUMBER(), RANK(), SUM(), AVG(), и другими, чтобы выполнить операции над набором строк, не сводя их к одному результату. В отличие от стандартных агрегатных функций, которые возвращают одно значение для каждой группы строк, OVER позволяет работать с данными в контексте всей выборки или ее части, предоставляя более гибкие и точные результаты.
Одним из ключевых преимуществ использования OVER является возможность вычисления таких показателей, как скользящие суммы, ранги или процентные доли, без необходимости переписывать запросы с дополнительными подзапросами. Для этого достаточно указать подходящее окно – область строк, для которых будет выполнена операция. Например, можно вычислить сумму по каждому заказу в пределах конкретного региона или ранжировать сотрудников по количеству выполненных задач в рамках одной компании.
Правильное использование OVER требует понимания структуры и назначения PARTITION BY и ORDER BY, которые задают, как будет делиться набор данных и в каком порядке будут вычисляться функции. PARTITION BY делит данные на группы, а ORDER BY определяет порядок строк внутри каждой группы. Эти компоненты позволяют реализовать более сложные аналитические запросы, например, вычисление среднего значения по каждой категории или сравнение текущего значения с предыдущим.
Основы оператора OVER: как работает в SQL
Оператор OVER в SQL используется для расширения функциональности аналитических функций. Он позволяет выполнять вычисления по определенному набору строк в рамках результата запроса, не изменяя его структуры. Вместо того, чтобы возвращать одно агрегированное значение для всей таблицы, OVER вычисляет результаты для каждого ряда на основе окна, которое определяется пользователем.
Основное назначение оператора – выполнение вычислений, таких как ранжирование, суммирование, вычисление скользящих средних и другие, в пределах заданного окна строк. Оператор OVER может быть использован с такими аналитическими функциями, как ROW_NUMBER(), RANK(), DENSE_RANK(), SUM(), AVG() и другие.
Для использования OVER необходимо указать, что именно должно быть включено в окно, а также, если нужно, как строки должны быть сгруппированы или упорядочены. Окно можно задать с помощью PARTITION BY для разделения строк на группы и ORDER BY для задания порядка строк в пределах каждого окна.
Пример использования:
SELECT
employee_id,
department_id,
salary,
AVG(salary) OVER (PARTITION BY department_id) AS avg_salary_by_dept
FROM employees;
В этом примере для каждого сотрудника из таблицы employees будет рассчитана средняя зарплата по его отделу. Оператор PARTITION BY разделяет сотрудников на группы по отделам, и функция AVG() вычисляет среднюю зарплату в каждой группе.
Важно помнить, что оператор OVER не изменяет количество строк в результирующем наборе данных. Он лишь добавляет вычисления для каждой строки, не создавая дополнительных агрегированных строк, как это делает обычная функция агрегации.
Использование OVER эффективно при необходимости выполнить аналитические вычисления в запросах, где нужно сохранить подробности по каждой строке, например, при анализе данных о продажах, оценке производительности сотрудников или расчете рейтингов.
Использование OVER для оконных функций в SQL

В SQL оконные функции позволяют производить вычисления по строкам в пределах определенной группы без изменения структуры результата запроса. Для этого используется конструкция OVER, которая определяет «окно» – набор строк, к которому применяется оконная функция. Это окно может быть задано с помощью различных параметров, включая PARTITION BY для разбиения на группы и ORDER BY для упорядочивания строк в каждой группе.
Основное отличие оконных функций от агрегатных заключается в том, что они не сводят результат к одной строке, а вычисляют значения для каждой строки в исходной таблице, учитывая строки в пределах окна. Это делает оконные функции мощным инструментом для анализа данных в реальном времени.
Пример использования оконной функции ROW_NUMBER() для нумерации строк в пределах каждой группы:
SELECT
department,
employee_name,
ROW_NUMBER() OVER (PARTITION BY department ORDER BY salary DESC) AS rank
FROM employees;В этом примере для каждого сотрудника внутри отдела будет присвоен уникальный номер, основанный на их зарплате, с наивысшим значением у сотрудника с самой высокой зарплатой. Использование PARTITION BY делит данные по отделам, а ORDER BY упорядочивает сотрудников по зарплате в каждом отделе.
Некоторые оконные функции, такие как RANK(), NTILE(), SUM() и AVG(), позволяют более гибко работать с данными, вычисляя агрегированные значения по всему окну или по его части. Например, использование SUM() с OVER может подсчитать накопительную сумму в пределах окна:
SELECT
order_date,
amount,
SUM(amount) OVER (ORDER BY order_date) AS cumulative_sum
FROM orders;Здесь для каждой строки будет вычисляться сумма всех заказов, сделанных до текущей строки, с учетом даты заказа. Это удобно для анализа динамики продаж или других временных рядов.
Одной из важных особенностей оконных функций является возможность применения оконных фреймов. С помощью ROWS BETWEEN можно уточнить, какие строки будут включены в окно. Например:
SELECT
order_date,
amount,
SUM(amount) OVER (ORDER BY order_date ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS moving_sum
FROM orders;Здесь суммируются значения текущей и предыдущей строки, что полезно для расчета скользящих сумм или других статистических показателей.
Оконные функции в SQL – это мощный инструмент для проведения сложного анализа данных без необходимости менять структуру таблицы или выполнять дополнительные подзапросы. Использование OVER позволяет значительно упростить запросы, сделав их более читаемыми и эффективными.
Пример применения OVER с агрегатными функциями
Функция OVER в SQL используется для выполнения операций с агрегатными функциями, не сводя результат к единому значению по всему набору данных. Это особенно полезно, когда требуется выполнять агрегацию по окну строк, например, для вычисления суммы, среднего или ранга в пределах определенной группы данных.
Пример 1: Для вычисления суммы продаж по каждому сотруднику, но без сворачивания результата в одну строку, можно использовать OVER с функцией SUM(). С помощью этого подхода можно видеть сумму для каждой строки, но данные не теряются.
SELECT employee_id, sales_amount, SUM(sales_amount) OVER (PARTITION BY employee_id) AS total_sales FROM sales;
Здесь SUM(sales_amount) суммирует значения для каждого сотрудника (PARTITION BY employee_id). Таким образом, для каждой строки возвращается сумма продаж этого сотрудника, но не теряется информация по каждой строке.
Пример 2: Для вычисления среднего значения с использованием AVG() можно добавить фильтрацию по окну строк с помощью OVER. Например, если нужно вычислить среднее значение продаж по каждому месяцу:
SELECT employee_id, sales_month, sales_amount, AVG(sales_amount) OVER (PARTITION BY sales_month) AS avg_sales_per_month FROM sales;
В этом примере для каждой строки вычисляется средняя сумма продаж за месяц, но каждый сотрудник по-прежнему видит свою индивидуальную строку с соответствующими значениями.
Пример 3: С помощью функции ROW_NUMBER() и OVER можно добавлять нумерацию строк в пределах каждой группы. Это полезно, например, для ранжирования сотрудников по объему продаж:
SELECT employee_id, sales_amount, ROW_NUMBER() OVER (PARTITION BY sales_month ORDER BY sales_amount DESC) AS rank FROM sales;
В данном случае каждому сотруднику присваивается номер в пределах месяца на основе величины продаж. Чем больше продаж, тем выше ранг.
OVER позволяет эффективно использовать агрегатные функции, сохраняя детали на уровне строк и не сводя их в единую итоговую строку. Это расширяет возможности аналитики в SQL, позволяя работать с большими объемами данных с высокой точностью и гибкостью.
Как применять ORDER BY с оператором OVER
Оператор OVER в SQL используется для выполнения аналитических функций, таких как ROW_NUMBER(), RANK(), DENSE_RANK(), SUM() и других, которые работают по оконным функциям. Когда к этим функциям добавляется ORDER BY, они начинают учитывать порядок строк в рамках определённого окна.
Применение ORDER BY внутри оператора OVER позволяет изменить способ обработки данных внутри окна, сортируя их по нужному полю. Это важно для таких функций, как ROW_NUMBER(), где порядок строк определяет их уникальные номера. Например, для нумерации строк в упорядоченном списке можно использовать следующий запрос:
SELECT id, name, ROW_NUMBER() OVER (ORDER BY salary DESC) AS row_num FROM employees;
В данном случае строки будут нумероваться по убыванию значения в поле salary. Таким образом, использование ORDER BY позволяет точно контролировать порядок обработки строк в окне, что критично для правильной работы аналитических функций.
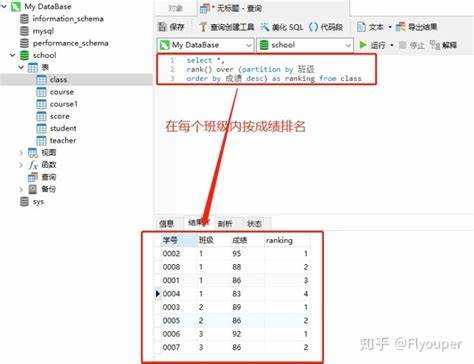
Еще одно важное применение заключается в комбинировании PARTITION BY с ORDER BY. В этом случае данные разбиваются на части (партиции), а внутри каждой части выполняется сортировка. Например, если нужно посчитать ранк сотрудников в каждой должности, запрос будет следующим:
SELECT id, name, position, RANK() OVER (PARTITION BY position ORDER BY salary DESC) AS rank FROM employees;
Здесь данные сначала делятся по полю position, а внутри каждой группы сортируются по salary, и присваивается ранг. Такой подход позволяет проводить более точный анализ данных по подмножествам, сохраняя контроль над порядком строк.
Использование ORDER BY с OVER критично, когда необходимо точно определить порядок вычислений внутри оконных функций. Без сортировки результаты могут быть непредсказуемыми, особенно если необходимо учитывать приоритеты или классификацию строк в пределах определённых групп данных.
Использование PARTITION BY в сочетании с OVER
Оператор PARTITION BY используется внутри функции OVER для разделения набора строк на группы, которые обрабатываются отдельно в рамках аналитической функции. Это позволяет выполнять вычисления или агрегации, но только в пределах каждой группы данных, не затрагивая остальные строки.
Вместо того чтобы вычислять результат по всему набору данных, как это делает обычная агрегация, PARTITION BY делит данные на логические сегменты, и аналитическая функция применяется к каждой группе по отдельности.
Пример:
SELECT
department,
employee_name,
salary,
RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS rank_within_dept
FROM employees;
В этом примере функция RANK() вычисляет ранг каждого сотрудника в пределах его отдела (группы), сортируя сотрудников по зарплате в убывающем порядке. Каждый отдел рассматривается как отдельная группа, и сотрудник с самой высокой зарплатой в каждом отделе получит ранг 1.
Особенности использования PARTITION BY:
- Группировка данных: Функция делит данные на группы по одному или нескольким столбцам. Например, для разделения по годам и месяцам можно использовать
PARTITION BY YEAR(date), MONTH(date). - Совмещение с сортировкой:
PARTITION BYработает в сочетании сORDER BYдля корректной обработки данных внутри каждой группы. Это важно для функций, требующих сортировки, таких какRANK(),DENSE_RANK()и других. - Без влияния на результат агрегирования: Часто
PARTITION BYиспользуется для добавления вспомогательных аналитических данных, таких как ранжирование, без изменения самой структуры таблицы.
Кроме того, можно комбинировать несколько столбцов в PARTITION BY, что позволяет создать более детализированные группы для анализа. Например, если нужно анализировать данные по отделам и типам сотрудников, можно использовать:
SELECT
department,
employee_type,
employee_name,
SUM(salary) OVER (PARTITION BY department, employee_type) AS total_salary_by_type
FROM employees;
Здесь для каждого типа сотрудника в рамках отдела будет посчитана общая сумма зарплаты, но при этом данные сотрудников не будут перемешиваться между отделами.
Использование PARTITION BY в сочетании с OVER важно для выполнения сложных аналитических запросов, когда нужно сохранить группировку данных, но при этом выполнить вычисления по отдельным подмножествам строк.
Рассмотрение примеров с ROWS и RANGE в оконных функциях
Оконные функции в SQL позволяют выполнять вычисления над набором строк, связанных с текущей строкой. Для этого используется конструкция OVER, которая может быть настроена с различными опциями, такими как ROWS и RANGE. Эти два параметра определяют, какие строки будут включены в «окно» для выполнения функции.
ROWS и RANGE различаются в том, как они определяют границы окна. ROWS использует физическое смещение строк относительно текущей, тогда как RANGE опирается на значения в столбцах для определения набора строк.
Пример с ROWS:
Предположим, у нас есть таблица с продажами по дням, и мы хотим вычислить скользящее среднее за последние 3 дня. Мы можем использовать конструкцию ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING, чтобы указать, что окно должно включать одну строку до текущей и одну строку после текущей.
SELECT sale_date, sales_amount, AVG(sales_amount) OVER (ORDER BY sale_date ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS moving_avg FROM sales;
В этом примере для каждой строки в таблице вычисляется среднее значение за текущую строку и одну строку до и после неё. Это обеспечит плавное скользящее среднее.
Пример с RANGE:
Теперь предположим, что мы хотим вычислить скользящее среднее по продажам за последние 100 единиц продаж, а не за количество строк. В этом случае можно использовать RANGE, чтобы окно зависело от значения столбца, например, от суммы продаж.
SELECT sale_date, sales_amount, AVG(sales_amount) OVER (ORDER BY sale_date RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS avg_sales FROM sales;
Здесь окно для вычисления среднего значения будет включать все строки, где сумма продаж меньше или равна текущей строке. Использование RANGE позволяет более гибко работать с диапазонами значений, а не с конкретными строками.
Важным отличием является то, что ROWS работает на уровне строк, а RANGE – на уровне значений, что делает их выбор зависимым от типа задачи. ROWS подходит для задач, где нужно учитывать физическое количество строк, а RANGE – для анализа данных, где важен диапазон значений, например, для скользящих средних, сумм и других агрегатных функций.
Как комбинировать несколько оконных функций с OVER
Комбинирование нескольких оконных функций с OVER позволяет вычислять различные аналитические метрики в одном запросе, не разделяя их на несколько отдельных операций. Оконные функции используются для выполнения расчетов в пределах «окна», определенного набором строк, что позволяет эффективно обрабатывать сложные задачи без необходимости группировки данных. Например, можно одновременно вычислять скользящие средние, ранги и агрегатные функции.
Для комбинирования нескольких оконных функций важно точно указать, какие функции нужно применить и как они должны взаимодействовать. Рассмотрим пример, где нужно одновременно вычислить суммарный доход и его процент от общего дохода для каждого клиента, а также порядковый номер клиента в каждом регионе. В данном случае могут быть использованы такие оконные функции, как SUM(), PERCENT_RANK() и ROW_NUMBER().
Пример запроса:
SELECT
client_id,
region,
SUM(income) OVER (PARTITION BY region) AS total_region_income,
PERCENT_RANK() OVER (PARTITION BY region ORDER BY income DESC) AS income_percent_rank,
ROW_NUMBER() OVER (PARTITION BY region ORDER BY income DESC) AS client_rank
FROM
clients;
В этом запросе:
- SUM(income) OVER (PARTITION BY region) – вычисляет общий доход по каждому региону.
- PERCENT_RANK() OVER (PARTITION BY region ORDER BY income DESC) – возвращает процентное положение дохода клиента в рамках региона.
- ROW_NUMBER() OVER (PARTITION BY region ORDER BY income DESC) – генерирует уникальный номер для каждого клиента, отсортированного по доходу внутри региона.
Для правильного использования нескольких оконных функций важно понимать, что каждая функция имеет свое «окно», которое может быть ограничено с помощью PARTITION BY или ORDER BY. Размещение этих функций в одном запросе позволяет избежать излишних вычислений и повышает производительность запросов. Например, использование PARTITION BY region разделяет данные по регионам, что оптимизирует расчеты для каждого региона отдельно.
При комбинировании оконных функций важно следить за правильной последовательностью. Например, если используется ROW_NUMBER(), его результаты могут быть использованы в других функциях, как критерий сортировки. В этом случае выполнение функций в правильном порядке имеет решающее значение для получения корректных результатов.
Таким образом, комбинирование нескольких оконных функций с OVER открывает широкие возможности для аналитических запросов, позволяя эффективно извлекать несколько показателей из одного набора данных без дополнительной агрегации или сложных подзапросов.
Ошибки и ограничения при использовании OVER в SQL
Функция OVER в SQL предоставляет мощные возможности для работы с оконными функциями, но при неправильном использовании могут возникать различные ошибки и ограничения, которые существенно осложняют процесс работы с данными. Вот основные из них:
- Отсутствие ORDER BY: При использовании оконных функций важно правильно определить порядок строк с помощью
ORDER BY. Если порядок не указан, результат может быть непредсказуемым. Например, функцииROW_NUMBER()иRANK()могут возвращать неожиданные значения, если порядок строк не явно задан. - Неправильное использование PARTITION BY: В случае, если в запросе используется
PARTITION BY, необходимо внимательно следить за разделением данных. Ошибки могут возникать, если разделение данных не соответствует логике запроса. Например, если не определен нужный столбец для partitioning, это приведет к ошибке или неверным результатам. - Перегрузка вычислений: Использование оконных функций может привести к перегрузке вычислений, особенно при больших объемах данных. Операции внутри окна могут замедлить выполнение запроса, если не использовать индексы или не оптимизировать запросы должным образом.
- Несоответствие с агрегатами: Некоторые агрегатные функции (например,
SUM(),AVG()) могут конфликтовать с оконными функциями, если они используются в одном и том же запросе. В таких случаях необходимо тщательно продумать, как правильно распределить вычисления, чтобы избежать ошибок выполнения. - Невозможность использования в подзапросах: В большинстве СУБД нельзя использовать оконные функции внутри подзапросов, если они не находятся в основном запросе. Это ограничение может стать проблемой при сложных запросах, где требуется агрегация и оконные функции одновременно.
- Проблемы с производительностью: Использование оконных функций может привести к замедлению работы системы, особенно на больших таблицах. Без правильной индексации и оптимизации запросов производительность может снизиться в несколько раз.
Для минимизации этих ошибок важно тщательно тестировать запросы, следить за правильной индексацией и учитывать возможные проблемы с производительностью. Также стоит внимательно читать документацию по оконным функциям для каждой конкретной СУБД, так как синтаксис и поведение могут немного различаться в зависимости от платформы.
Вопрос-ответ:
Что такое OVER в SQL?
OVER в SQL — это ключевое слово, которое используется в оконных функциях для выполнения вычислений, касающихся строк в наборе данных, но без изменения количества строк в результирующем наборе. Оно позволяет создавать вычисления на основе определённого окна строк, которые могут быть сгруппированы по различным признакам или отсортированы. Например, с помощью OVER можно вычислять скользящие суммы или ранжировать записи в рамках одной группы.
Как применяются оконные функции с использованием OVER?
Для того чтобы использовать оконные функции с OVER, необходимо указать область, в рамках которой будет выполняться операция. Например, при использовании функции ROW_NUMBER() можно создать нумерацию строк в пределах каждой группы данных. Пример: `SELECT id, name, ROW_NUMBER() OVER (PARTITION BY department ORDER BY salary DESC) FROM employees;` Этот запрос нумерует сотрудников внутри каждого отдела по убыванию зарплаты.
Можно ли использовать несколько окон с одним OVER в SQL?
Да, можно использовать несколько окон в одном запросе, комбинируя разные оконные функции в одном выражении. Например, можно одновременно вычислять сумму по окну и ранжировать строки. Пример: `SELECT id, department, salary, SUM(salary) OVER (PARTITION BY department) AS dept_total, RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS rank FROM employees;`. Это вычислит общую сумму зарплат для каждого отдела и определит ранг каждого сотрудника внутри его отдела.
Как использовать ORDER BY внутри оператора OVER?
ORDER BY внутри оператора OVER позволяет отсортировать строки в рамках окна перед применением оконной функции. Это особенно полезно, если нужно рассчитать, например, скользящие суммы или вычислить ранг записей. Пример: `SELECT id, salary, SUM(salary) OVER (ORDER BY salary ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) FROM employees;`. В данном случае строки будут отсортированы по зарплате, а сумма будет вычисляться от первой строки до текущей.
Что такое PARTITION BY и как это работает с OVER?
PARTITION BY используется для разделения набора данных на группы, внутри которых будет выполняться оконная функция. Если PARTITION BY не указан, оконная функция будет применяться ко всему набору данных. Например, если нужно посчитать сумму зарплат по отделам, можно использовать запрос: `SELECT id, department, salary, SUM(salary) OVER (PARTITION BY department) FROM employees;`. В этом случае для каждого отдела будет вычисляться своя сумма зарплат, а сама строка останется неизменной.
Что такое OVER в SQL и для чего он используется?
Оператор OVER в SQL позволяет выполнять оконные функции, которые обрабатывают набор строк, связанных с текущей строкой, без изменения результатов выборки. Это полезно, когда необходимо выполнить агрегирование или вычисления, такие как ранжирование, подсчет, суммирование или вычисление скользящих средних, но без группировки данных. OVER определяет окно, которое используется для выполнения вычислений, при этом строки не сгруппированы, и результат остается в исходном порядке.