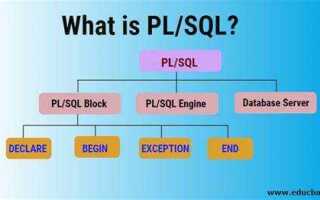
PL SQL (Procedural Language for SQL) – это расширение SQL, разработанное компанией Oracle для выполнения процедурных операций в базах данных. Этот язык позволяет интегрировать SQL-запросы с логикой программирования, обеспечивая более высокую гибкость и мощность работы с данными. Основное отличие PL SQL от стандартного SQL заключается в поддержке процедурных конструкций: циклов, условий, обработки исключений и переменных, что делает его идеальным инструментом для сложных операций в базе данных.
PL SQL активно используется в корпоративных приложениях для автоматизации работы с базами данных, таких как обработка транзакций, выполнение повторяющихся задач и создание сложных бизнес-логик. Основные возможности PL SQL включают создание хранимых процедур, функций, триггеров и пакетов. Это позволяет не только улучшить производительность системы за счет уменьшения количества запросов к базе данных, но и сделать код более структурированным и поддерживаемым.
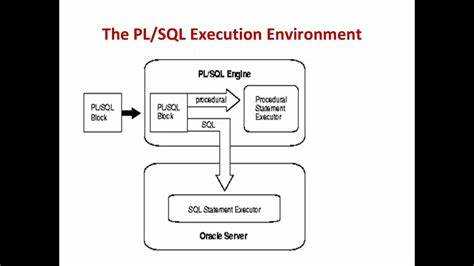
Для начала работы с PL SQL достаточно иметь установленную базу данных Oracle и доступ к SQL*Plus или другому инструменту для взаимодействия с базой данных. Создание программных блоков в PL SQL начинается с объявления переменных, обработки логики с использованием стандартных операторов, а также завершения блока с помощью ключевого слова END;. Важно помнить, что для эффективного использования языка PL SQL необходимы знания SQL и понимание архитектуры баз данных.
Основы синтаксиса PL SQL для новичков

Структура PL SQL-блока включает три основные части: объявление, выполнение и обработку исключений. Эти части разделяются с помощью ключевых слов:
1. Объявление переменных
В блоке PL SQL переменные объявляются в разделе DECLARE. Здесь можно задать типы данных, такие как VARCHAR2, NUMBER, DATE, и другие. Пример:
DECLARE v_name VARCHAR2(50); v_age NUMBER; BEGIN v_name := 'Иван'; v_age := 30; END;
2. Основной блок выполнения
После объявления переменных начинается блок BEGIN…END, который содержит основную логику программы. Все операторы и запросы выполняются внутри этого блока. Например, выполнение SQL-запроса может выглядеть так:
BEGIN
SELECT name INTO v_name FROM employees WHERE id = 101;
DBMS_OUTPUT.PUT_LINE('Имя сотрудника: ' || v_name);
END;
3. Обработка исключений
Для обработки ошибок используется блок EXCEPTION. Это необходимо, чтобы перехватывать ошибки, такие как отсутствие данных или нарушение ограничений, и обрабатывать их корректно. Пример:
BEGIN
-- Код выполнения
EXCEPTION
WHEN NO_DATA_FOUND THEN
DBMS_OUTPUT.PUT_LINE('Данные не найдены');
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE('Ошибка выполнения');
END;
Основные операторы и конструкции:
- IF…THEN…ELSE – условные операторы для выполнения различных блоков кода в зависимости от условий.
- LOOP – используется для организации циклов. Возможны варианты FOR, WHILE и обычный LOOP.
- CURSOR – указатель на набор данных, который позволяет извлекать и обрабатывать результаты запросов.
Пример условного оператора:
BEGIN
IF v_age >= 18 THEN
DBMS_OUTPUT.PUT_LINE('Совершеннолетний');
ELSE
DBMS_OUTPUT.PUT_LINE('Несовершеннолетний');
END IF;
END;
Переменные и типы данных:
Типы данных в PL SQL включают NUMBER для чисел, VARCHAR2 для строк, DATE для дат и времени, а также типы для работы с большими объемами данных, такие как CLOB и BLOB.
Пример цикла:
BEGIN
FOR i IN 1..5 LOOP
DBMS_OUTPUT.PUT_LINE('Число: ' || i);
END LOOP;
END;
Это лишь базовые элементы синтаксиса PL SQL, однако они позволяют строить полноценные программы для работы с базами данных. Для более сложных приложений рекомендуется изучать работу с процедурами, функциями, а также принципами оптимизации кода.
Как создавать и работать с переменными в PL SQL
Объявление переменной осуществляется с помощью ключевого слова VARIABLE_NAME TYPE, где VARIABLE_NAME – это имя переменной, а TYPE – тип данных, который эта переменная будет хранить. Например:
DECLARE
v_employee_name VARCHAR2(50);
v_salary NUMBER(10, 2);
BEGIN
-- Код программы
END;В этом примере переменные v_employee_name и v_salary объявлены с типами VARCHAR2 и NUMBER, соответственно. Переменные могут быть инициализированы значениями прямо в разделе DECLARE, либо позднее, в разделе BEGIN.
Инициализация переменной происходит с помощью оператора присваивания. Например:
BEGIN
v_employee_name := 'Иван Иванов';
v_salary := 50000.00;
END;Для присваивания значений можно использовать как литералы, так и результаты SQL-запросов. Например, чтобы присвоить значение переменной на основе данных из базы, можно использовать оператор SELECT INTO:
DECLARE
v_employee_name VARCHAR2(50);
BEGIN
SELECT first_name INTO v_employee_name FROM employees WHERE employee_id = 101;
END;Работа с переменными в PL SQL осуществляется так же, как и с любыми другими значениями. Переменные могут быть использованы в арифметических операциях, условных операторах или в циклах. Например:
BEGIN
v_salary := v_salary * 1.05; -- увеличение зарплаты на 5%
IF v_salary > 100000 THEN
DBMS_OUTPUT.PUT_LINE('Высокая зарплата');
END IF;
END;Типы данных для переменных в PL SQL могут быть различными, включая:
- VARCHAR2 – строковые данные, максимальная длина 4000 символов.
- NUMBER – числовые данные, поддерживающие целые и дробные числа.
- DATE – для хранения даты и времени.
- CLOB – для хранения больших объемов текстовой информации.
Преобразование типов также возможно в PL SQL, например, с использованием функции TO_NUMBER, TO_DATE или TO_CHAR. Это полезно, когда необходимо преобразовать данные между типами:
DECLARE
v_string VARCHAR2(20);
v_date DATE;
BEGIN
v_string := '2025-04-22';
v_date := TO_DATE(v_string, 'YYYY-MM-DD');
END;Локальные и глобальные переменные в PL SQL отличаются областью видимости. Локальные переменные, объявленные внутри блока BEGIN…END, доступны только в пределах этого блока. Глобальные переменные, объявленные в пакете или в качестве параметров процедуры, доступны на протяжении всей программы.
Работа с переменными в PL SQL – это основа для более сложных процедур и функций, а правильное использование типов данных и присваивания значений позволяет эффективно управлять логикой обработки данных.
Использование операторов условных переходов в PL SQL
В PL SQL операторы условных переходов позволяют управлять логикой выполнения программы в зависимости от определённых условий. Это позволяет создавать более гибкие и динамичные скрипты для работы с базами данных. В языке PL SQL существует несколько видов операторов условных переходов: IF, CASE, а также конструкции LOOP с условием выхода.
Оператор IF используется для выполнения блоков кода, если выполняется заданное условие. Он бывает нескольких типов:
- Простой IF: проверяется одно условие.
- IF-ELSE: выполняются разные блоки кода в зависимости от истинности условия.
- IF-ELSIF-ELSE: позволяет проверять несколько условий поочередно.
Пример простого использования:
IF условие THEN
-- действия
END IF;
Пример с несколькими проверками условий:
IF условие_1 THEN
-- действия для условия_1
ELSIF условие_2 THEN
-- действия для условия_2
ELSE
-- действия для остальных случаев
END IF;
Оператор CASE используется, когда необходимо выполнить одну из множества альтернативных операций, что делает код компактным и читаемым. Он бывает двух типов:
- CASE в виде выражения: возвращает результат на основе сравнения.
- CASE в виде оператора: используется для выбора одного из нескольких блоков кода в зависимости от значения переменной.
Пример использования CASE:
CASE выражение
WHEN значение_1 THEN
-- действия для значение_1
WHEN значение_2 THEN
-- действия для значение_2
ELSE
-- действия для других значений
END CASE;
Рекомендации: Используйте оператор IF-ELSIF для проверок нескольких условий, чтобы избежать излишних вложенных блоков IF, что улучшит читаемость кода. Для сценариев с большим количеством вариантов предпочтительнее использовать CASE, так как он делает код более структурированным и сокращает количество проверок в отдельных блоках.
Оптимизация: Старайтесь минимизировать количество вложенных конструкций IF в одном блоке. Когда условия становятся слишком сложными, это может затруднить поддержку и чтение кода. В таких случаях лучше использовать дополнительные функции или процедуры для изоляции логики.
Заключение: Операторы условных переходов являются важным инструментом в PL SQL, позволяющим эффективно управлять потоком выполнения программы. Понимание их использования и правильная организация кода позволяет создавать более устойчивые и масштабируемые решения для работы с данными.
Как работать с курсорами в PL SQL
В PL/SQL существует два типа курсоров: неявные и явные. Неявные курсоры автоматически создаются при выполнении SQL-запросов через SQL-операторы, такие как SELECT INTO, INSERT, UPDATE и DELETE. Явные курсоры же создаются вручную, что дает больше контроля над процессом обработки данных.
1. Создание явного курсора
Явный курсор создается с помощью инструкции CURSOR, где указывается SQL-запрос. После этого курсор нужно открыть, обработать и закрыть.
DECLARE
CURSOR c_example IS
SELECT name, age FROM employees WHERE department_id = 10;
v_name employees.name%TYPE;
v_age employees.age%TYPE;
BEGIN
OPEN c_example;
LOOP
FETCH c_example INTO v_name, v_age;
EXIT WHEN c_example%NOTFOUND;
-- Обработка данных
DBMS_OUTPUT.PUT_LINE('Name: ' || v_name || ', Age: ' || v_age);
END LOOP;
CLOSE c_example;
END;
В данном примере курсор c_example выбирает имя и возраст сотрудников, работающих в департаменте с ID 10. После того как данные извлекаются с помощью оператора FETCH, они могут быть использованы в теле цикла.
2. Операторы с курсорами
Курсоры поддерживают несколько важных операторов:
- OPEN – инициирует выполнение SQL-запроса, связанного с курсором.
- FETCH – извлекает данные из курсора и записывает их в переменные.
- CLOSE – завершает работу с курсором, освобождая ресурсы.
Оператор EXIT WHEN используется для выхода из цикла, когда все строки были обработаны (проверка c_example%NOTFOUND). Это важно для предотвращения бесконечных циклов, если в результате запроса нет данных.
3. Параметры и передача данных в курсоры
Для того чтобы сделать курсор динамичным, его можно параметризовать. Параметры передаются в курсор через объявление и могут быть использованы в SQL-запросе.
DECLARE
CURSOR c_example(p_dept_id IN NUMBER) IS
SELECT name, age FROM employees WHERE department_id = p_dept_id;
v_name employees.name%TYPE;
v_age employees.age%TYPE;
BEGIN
OPEN c_example(10); -- Параметр передается при открытии курсора
LOOP
FETCH c_example INTO v_name, v_age;
EXIT WHEN c_example%NOTFOUND;
DBMS_OUTPUT.PUT_LINE('Name: ' || v_name || ', Age: ' || v_age);
END LOOP;
CLOSE c_example;
END;
В этом примере курсор принимает параметр p_dept_id, который позволяет передавать значения при его открытии, что делает код более универсальным и гибким.
4. Обработка ошибок при работе с курсорами
Работа с курсорами требует учета возможных ошибок, таких как отсутствие данных или проблемы с выполнением запроса. Для обработки таких ситуаций можно использовать конструкцию EXCEPTION.
DECLARE
CURSOR c_example IS
SELECT name, age FROM employees WHERE department_id = 10;
v_name employees.name%TYPE;
v_age employees.age%TYPE;
BEGIN
OPEN c_example;
LOOP
FETCH c_example INTO v_name, v_age;
EXIT WHEN c_example%NOTFOUND;
DBMS_OUTPUT.PUT_LINE('Name: ' || v_name || ', Age: ' || v_age);
END LOOP;
CLOSE c_example;
EXCEPTION
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE('Error: ' || SQLERRM);
END;
Это позволяет поймать ошибки, возникающие при выполнении запроса или в процессе работы с курсором, и вывести информацию об ошибке для дальнейшего анализа.
5. Использование курсоров с динамическими запросами
PL/SQL также позволяет использовать динамические SQL-запросы в курсорах с помощью функции EXECUTE IMMEDIATE, что полезно при необходимости строить запросы на лету в зависимости от входных параметров.
DECLARE CURSOR c_dynamic IS EXECUTE IMMEDIATE 'SELECT name FROM employees WHERE department_id = :dept_id' USING 10; v_name employees.name%TYPE; BEGIN OPEN c_dynamic; LOOP FETCH c_dynamic INTO v_name; EXIT WHEN c_dynamic%NOTFOUND; DBMS_OUTPUT.PUT_LINE(v_name); END LOOP; CLOSE c_dynamic; END;
В данном примере курсор использует динамический SQL-запрос, где параметр передается через конструкцию USING. Это удобно при построении запросов, которые зависят от внешних условий.
Курсоры в PL/SQL позволяют эффективно работать с результатами сложных запросов, предоставляют гибкость при обработке данных и могут быть настроены для разных типов операций в зависимости от конкретных задач.
Обработка ошибок и исключений в PL SQL
В PL SQL обработка ошибок и исключений осуществляется с помощью конструкции EXCEPTION, которая позволяет перехватывать и обрабатывать ошибки, возникшие в процессе выполнения блока кода. Это важно для обеспечения стабильности и предсказуемости работы программных приложений.
Когда возникает ошибка, PL SQL автоматически прекращает выполнение текущего блока и передает управление в блок EXCEPTION, если таковой имеется. Важно понимать, что ошибки могут быть разных типов: от синтаксических до логических и исключений, связанных с выполнением SQL-запросов.
Основные типы ошибок
- Ошибка выполнения SQL: Например, нарушение уникальности в таблице или деление на ноль.
- Ошибка в логике программы: Ошибки, не связанные напрямую с SQL-запросами, такие как неверные вычисления или неправильные условия.
- Пользовательские исключения: Можно задать собственные ошибки с помощью оператора
RAISE.
Синтаксис блока EXCEPTION
Типичная структура обработки ошибок в PL SQL выглядит следующим образом:
BEGIN -- основной код EXCEPTION WHEN <тип_исключения> THEN -- обработка ошибки WHEN OTHERS THEN -- обработка всех других ошибок END;
После ключевого слова WHEN указывается тип исключения, которое должно быть перехвачено. Если ошибка не была обработана явно, применяется блок WHEN OTHERS, который перехватывает все исключения, не указанные ранее.
Обработчики ошибок

NO_DATA_FOUND: Ошибка, возникающая, если запрос не возвращает результатов, например, при использованииSELECT INTO.TOO_MANY_ROWS: Возникает, если запрос возвращает больше одной строки при использованииSELECT INTO.ZERO_DIVIDE: Ошибка деления на ноль.VALUE_ERROR: Ошибка, когда происходит несоответствие типов данных (например, попытка присвоить строку числовой переменной).
Пример обработки ошибок
BEGIN
-- Попытка выполнить запрос
SELECT name INTO v_name FROM employees WHERE employee_id = 100;
EXCEPTION
WHEN NO_DATA_FOUND THEN
DBMS_OUTPUT.PUT_LINE('Сотрудник с таким ID не найден.');
WHEN TOO_MANY_ROWS THEN
DBMS_OUTPUT.PUT_LINE('Найдено больше одного сотрудника с таким ID.');
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE('Произошла ошибка: ' || SQLERRM);
END;
Логирование ошибок

Важно не только корректно обрабатывать ошибки, но и сохранять информацию о них для дальнейшего анализа. Для этого можно использовать встроенные процедуры, такие как DBMS_OUTPUT, или сохранять ошибки в таблицах базы данных для последующего анализа. Например:
BEGIN -- основной код EXCEPTION WHEN OTHERS THEN INSERT INTO error_log (error_message, error_time) VALUES (SQLERRM, SYSDATE); RAISE; END;
Этот подход позволяет сохранять ошибки в таблице error_log с временем их возникновения.
Пользовательские исключения

Можно создавать собственные исключения для обработки специфичных ошибок. Для этого необходимо объявить исключение с помощью ключевого слова EXCEPTION и выбрасывать его с помощью RAISE:
DECLARE
insufficient_balance EXCEPTION;
v_balance NUMBER := 100;
BEGIN
IF v_balance < 200 THEN
RAISE insufficient_balance;
END IF;
EXCEPTION
WHEN insufficient_balance THEN
DBMS_OUTPUT.PUT_LINE('Недостаточно средств на счете.');
END;
Рекомендации по обработке ошибок
- Не обрабатывайте все ошибки с помощью
WHEN OTHERS, если не уверены в причине возникновения ошибки. Лучше указывать конкретные типы ошибок. - Используйте логирование для отслеживания ошибок, особенно в продуктивных системах.
- Избегайте использования
RAISE_APPLICATION_ERRORв коде, если это не требуется, так как это ограничивает отладку.
Эффективная обработка ошибок помогает поддерживать стабильность работы системы, упрощает отладку и минимизирует влияние непредвиденных ситуаций на выполнение программ.
Применение транзакций в PL SQL для обеспечения целостности данных
Транзакции в PL SQL играют ключевую роль в поддержании целостности данных. Основная задача транзакции – обеспечить выполнение набора операций как атомарного целого, где все изменения данных либо сохраняются, либо откатываются. Это необходимо для предотвращения частичного применения изменений, которое может привести к непредсказуемым результатам или нарушению логической целостности базы данных.
Основными операциями для работы с транзакциями в PL SQL являются: COMMIT, ROLLBACK и SAVEPOINT. Эти операторы позволяют контролировать начало, завершение или откат транзакций, а также создавать точки восстановления в процессе выполнения.
COMMIT используется для подтверждения всех изменений, сделанных в рамках транзакции. После выполнения этого оператора изменения становятся постоянными и видимыми для других пользователей. Это важно в сценариях, где требуется гарантировать, что данные были обработаны полностью и корректно.
ROLLBACK откатывает все изменения, сделанные в транзакции, до момента начала транзакции или до точки, указанной в операторе SAVEPOINT. Это позволяет вернуть данные в исходное состояние при возникновении ошибок или других нежелательных ситуаций.
SAVEPOINT позволяет создать точку восстановления внутри транзакции. Это удобно, когда необходимо откатить изменения только до определенного момента, не отменяя всю транзакцию целиком. SAVEPOINT особенно полезен при сложных операциях с несколькими этапами, где важно сохранить часть выполненных изменений, если дальнейшая работа с данными не удалась.
При проектировании системы важно правильно использовать транзакции для обеспечения целостности данных. Например, при обновлении нескольких связанных таблиц необходимо обернуть все операции в одну транзакцию. Если какая-то из операций не удалась, откат транзакции вернет базу данных в предыдущее согласованное состояние.
Транзакции также играют роль в управлении блокировками. Они помогают избежать конфликтов между параллельно выполняющимися запросами. Использование явных блокировок (например, SELECT FOR UPDATE) в сочетании с транзакциями позволяет избежать ситуации, когда одни запросы перезаписывают данные, измененные другими запросами.
Для обеспечения высокой производительности системы важно учитывать минимизацию времени, в течение которого транзакция блокирует ресурсы. Неоправданно длительные транзакции могут привести к блокировкам и снижению производительности. Поэтому рекомендуется завершать транзакции как можно быстрее, исключая ненужные операции в рамках одной транзакции.
Применение транзакций в PL SQL – это не только инструмент для обеспечения целостности данных, но и способ организации надежного и производительного взаимодействия с базой данных в многозадачной среде. Их грамотное использование позволяет свести к минимуму риски, связанные с потерей данных и ошибками в процессе выполнения бизнес-логики.
Как писать и использовать функции и процедуры в PL SQL
Для создания функции или процедуры в PL SQL используется структура блоков. Основной блок включает в себя разделы DECLARE, BEGIN, EXCEPTION и END. Важно понимать, что использование этих блоков позволяет задавать локальные переменные, выполнять основную логику и обрабатывать ошибки.
Пример создания процедуры:
CREATE OR REPLACE PROCEDURE update_employee_salary ( emp_id IN NUMBER, salary IN NUMBER ) IS BEGIN UPDATE employees SET salary = salary WHERE employee_id = emp_id; COMMIT; END;
Этот пример демонстрирует процедуру, которая обновляет зарплату сотрудника по его идентификатору. Важно помнить, что процедуры не возвращают значений, но могут изменять данные в базе данных.
Пример создания функции:
CREATE OR REPLACE FUNCTION get_employee_salary ( emp_id IN NUMBER ) RETURN NUMBER IS emp_salary NUMBER; BEGIN SELECT salary INTO emp_salary FROM employees WHERE employee_id = emp_id; RETURN emp_salary; END;
Функция get_employee_salary возвращает зарплату сотрудника по его идентификатору. Функции обычно используются для вычислений и возврата значений, которые могут быть использованы в других выражениях или запросах.
Функции и процедуры могут быть вызваны как из SQL-запросов, так и из других программных блоков PL SQL. Для вызова процедуры используется команда EXECUTE, а для вызова функции – выражение или SELECT-запрос.
Пример вызова функции:
SELECT get_employee_salary(100) FROM dual;
Пример вызова процедуры:
EXECUTE update_employee_salary(100, 5000);
При написании функций и процедур важно учитывать особенности обработки исключений. Использование блока EXCEPTION позволяет корректно обрабатывать ошибки, не прерывая выполнение программы. Например, если запрос на обновление данных не может быть выполнен, можно добавить обработчик исключений:
CREATE OR REPLACE PROCEDURE update_employee_salary (
emp_id IN NUMBER,
salary IN NUMBER
) IS
BEGIN
UPDATE employees
SET salary = salary
WHERE employee_id = emp_id;
COMMIT;
EXCEPTION
WHEN OTHERS THEN
ROLLBACK;
DBMS_OUTPUT.PUT_LINE('Ошибка: ' || SQLERRM);
END;
Вопрос-ответ:
Что такое PL SQL?
PL SQL — это расширение языка SQL, разработанное для работы с базами данных Oracle. Этот язык программирования позволяет создавать сложные запросы, процедуры и функции, которые могут выполнять операции с данными, управлять ими и обеспечивать взаимодействие между различными компонентами базы данных. PL SQL сочетает в себе возможности SQL для работы с данными и функционал обычных языков программирования, таких как переменные, циклы, условия и обработка ошибок.
Как PL SQL отличается от обычного SQL?
Основное отличие заключается в том, что PL SQL предоставляет возможность писать программный код с использованием переменных, циклов и условных операторов. В отличие от обычного SQL, который применяется для выполнения запросов к базе данных и работы с данными, PL SQL позволяет создавать более сложные сценарии с обработкой ошибок, условиями и логикой. Например, в PL SQL можно создавать функции, процедуры и пакеты, которые можно многократно использовать в разных частях приложения.
Что такое PL SQL и для чего его используют?
PL SQL (Procedural Language/Structured Query Language) — это процедурный язык программирования, который используется в базах данных Oracle для расширения возможностей SQL. В отличие от обычного SQL, который предназначен для выполнения отдельных запросов, PL SQL позволяет создавать более сложные процедуры, такие как функции, триггеры и пакеты. Этот язык поддерживает управление потоком выполнения, обработку ошибок и работу с переменными, что делает его удобным для создания сложных программных решений, работающих с данными в базе. Он используется для автоматизации процессов в базах данных, улучшения производительности запросов и обеспечения безопасности данных.
Какие преимущества использования PL SQL в разработке баз данных?
PL SQL имеет несколько преимуществ для разработчиков и администраторов баз данных. Во-первых, он позволяет выполнять сложные вычисления и бизнес-логику прямо в базе данных, что может снизить нагрузку на клиентские приложения и ускорить обработку данных. Во-вторых, PL SQL поддерживает создание хранимых процедур и функций, что позволяет повторно использовать код и облегчает поддержку системы. Кроме того, язык предлагает встроенные средства обработки ошибок, что повышает надежность приложений. Важным аспектом является также высокая интеграция с Oracle, что делает PL SQL предпочтительным выбором для работы с этой СУБД. Все эти факторы вместе помогают повышать производительность и устойчивость приложений, а также снижают риски при работе с большими объемами данных.