

Составной запрос SQL – это способ объединения нескольких операций в одном запросе для выполнения более сложных задач. Вместо того чтобы выполнять каждый запрос по отдельности, составной запрос позволяет обращаться к нескольким таблицам, использовать подзапросы или объединять результаты нескольких операций в одном запросе. Это значительно повышает гибкость и эффективность работы с базами данных.
Часто составные запросы используют для решения задач, которые требуют извлечения данных из нескольких источников или их комбинирования. Например, когда необходимо получить информацию, которая зависит от нескольких таблиц, или когда нужно обработать и агрегировать данные из разных источников. Одним из ключевых инструментов составных запросов является JOIN, который позволяет объединить таблицы на основе общих полей, и подзапросы, которые позволяют получать результаты внутри других запросов.
Использование составных запросов требует внимательности к логике объединений, корректному применению условий фильтрации и пониманию различий между типами объединений (INNER JOIN, LEFT JOIN и т.д.). Это важно для предотвращения ошибок в выборках и обеспечения правильных результатов. Например, неправильный выбор типа объединения может привести к потере данных или их дублированию. Знание этих аспектов поможет эффективно строить запросы, которые будут работать с оптимальной производительностью и точностью.
Как объединить несколько SELECT-запросов с помощью UNION
Команда UNION в SQL позволяет объединять результаты нескольких SELECT-запросов в один набор данных. Это особенно полезно, когда необходимо получить данные из разных таблиц или разных источников, при этом условие для объединения заключается в том, что количество и типы столбцов в запросах должны совпадать.
Пример синтаксиса с UNION:
SELECT столбец1, столбец2 FROM таблица1 UNION SELECT столбец1, столбец2 FROM таблица2;
В данном примере два запроса объединяются в один результат. Важно заметить, что UNION автоматически исключает дублирующиеся строки, так как по умолчанию применяется операция DISTINCT для результата. Если требуется сохранить все строки, включая дубли, нужно использовать UNION ALL.
Пример с UNION ALL:
SELECT столбец1, столбец2 FROM таблица1 UNION ALL SELECT столбец1, столбец2 FROM таблица2;
Использование UNION ALL позволяет получить все строки из объединённых запросов без фильтрации дубликатов, что может быть полезно, если необходимо работать с полными наборами данных, включая повторы.
Важно соблюдать следующие правила при использовании UNION:
- Количество и порядок столбцов в каждом
SELECT-запросе должны совпадать. - Типы данных в соответствующих столбцах должны быть совместимы. Например, нельзя объединять столбцы с текстовыми и числовыми типами данных.
- Результат объединения будет отсортирован по умолчанию в порядке возрастания первого столбца. Для явного указания порядка используется
ORDER BY.
Для оптимизации работы с большими объемами данных, стоит избегать излишних операций с UNION, так как это может привести к дополнительной нагрузке на сервер. В таких случаях лучше воспользоваться альтернативными методами, например, подзапросами или временными таблицами.
Использование оператора JOIN для комбинирования данных из разных таблиц

Оператор JOIN позволяет объединить строки из двух или более таблиц на основе общего поля, создавая таким образом новый набор данных. Это основной инструмент для работы с реляционными базами данных, когда необходимо получить информацию, распределённую по нескольким таблицам. JOIN используется в запросах, где данные логически связаны, но хранятся в разных местах.
Для выполнения соединения таблиц обычно используют ключевые поля, такие как ID. Например, при работе с таблицами «Пользователи» и «Заказы» можно объединить их по полю «user_id», чтобы получить заказы, сделанные конкретными пользователями. Этот процесс позволяет избавиться от дублирования данных, а также улучшить производительность запросов, разделяя информацию по логическим блокам.
Существует несколько типов JOIN, каждый из которых используется в зависимости от задачи:
INNER JOIN – объединяет только те строки, которые имеют соответствующие значения в обеих таблицах. Этот тип соединения полезен, когда нужно получить только те записи, которые имеют полные данные по обеим сторонам. Например, запрос на получение всех пользователей с их заказами, где у пользователя есть хотя бы один заказ.
LEFT JOIN (или LEFT OUTER JOIN) – возвращает все строки из левой таблицы и соответствующие строки из правой таблицы. Если соответствий в правой таблице нет, то для этих строк будут возвращены значения NULL. Этот тип соединения используется, когда важно получить все записи из одной таблицы, даже если для некоторых из них нет данных в другой таблице. Например, можно получить список всех пользователей, включая тех, кто не сделал ни одного заказа.
RIGHT JOIN (или RIGHT OUTER JOIN) – работает аналогично LEFT JOIN, но возвращает все строки из правой таблицы, а для строк без соответствий в левой таблице возвращает NULL. Этот тип соединения реже используется, но может быть полезен, если важно получить все записи из правой таблицы, даже если для них нет данных в левой.
FULL JOIN (или FULL OUTER JOIN) – объединяет все строки из обеих таблиц, заполняя NULL, если для строки нет соответствия в другой таблице. Этот оператор используется, когда требуется получить полный набор данных из обеих таблиц, включая строки, не имеющие совпадений. Например, для получения списка всех пользователей и всех заказов, где могут быть пользователи без заказов и заказы, не связанные с пользователями.
CROSS JOIN – производит декартово произведение двух таблиц, возвращая все возможные комбинации строк. Этот тип соединения используется реже и обычно применяется для выполнения операций, требующих сочетания каждой строки одной таблицы с каждой строкой другой.
Каждое соединение требует указания условия соединения через ключевое слово ON, которое определяет, по каким полям следует объединять данные. Например:
SELECT * FROM users INNER JOIN orders ON users.user_id = orders.user_id;
Для повышения производительности запросов и уменьшения нагрузки на базу данных рекомендуется использовать индексы на полях, участвующих в соединении, что ускоряет поиск и объединение строк.
Как применить подзапросы в составных SQL-запросах
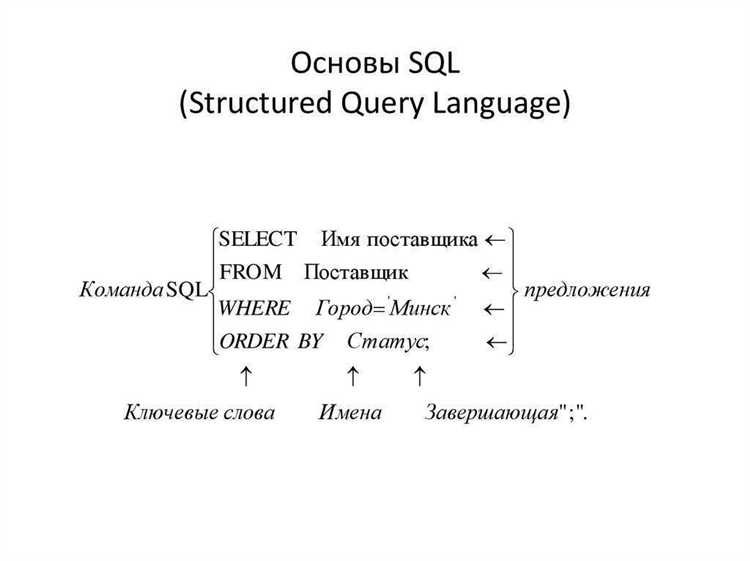
Подзапросы используются для выполнения операций внутри основного запроса. Это позволяет избежать необходимости создавать временные таблицы и работать с результатами другого запроса как с данными. Подзапросы могут быть использованы в различных частях SQL-запроса: в SELECT, WHERE, FROM, HAVING.
В зависимости от контекста, подзапросы могут быть:
- Коррелированные – зависят от внешнего запроса.
- Некоррелированные – выполняются независимо от основного запроса.
Основные рекомендации по применению подзапросов:
- WHERE: Подзапросы в условии WHERE полезны для фильтрации данных. Например, можно выбрать все заказы, сумма которых превышает среднее значение по всем заказам.
SELECT * FROM orders WHERE total > (SELECT AVG(total) FROM orders);
SELECT t.customer_id, SUM(t.amount) FROM (SELECT customer_id, amount FROM transactions WHERE status = 'completed') t GROUP BY t.customer_id;
SELECT customer_id, (SELECT COUNT(*) FROM orders WHERE customer_id = customers.customer_id) AS order_count FROM customers;
Важно помнить, что подзапросы могут значительно снизить производительность, особенно в случае использования коррелированных подзапросов. Рекомендуется тщательно анализировать запросы на предмет оптимизации и использования индексов.
Оптимизация составных запросов с использованием индексов
Индексы играют ключевую роль в ускорении выполнения составных запросов в SQL. Когда запрос включает несколько условий в WHERE, JOIN или других операторах, правильно настроенные индексы могут существенно снизить время выполнения, особенно при работе с большими объемами данных.
1. Индексы на нескольких колонках
Если запрос часто фильтрует по нескольким колонкам одновременно, целесообразно создавать составные индексы, которые охватывают эти колонки. Например, если запрос фильтрует по колонкам date и status, то индекс, который включает обе колонки, будет более эффективным, чем два отдельных индекса по каждой из них.
2. Порядок колонок в индексе
В составных индексах важен порядок колонок. Индекс, который начинается с самой селективной колонки (той, которая имеет наибольшее количество уникальных значений), позволит значительно ускорить выполнение запроса. Например, если колонка customer_id имеет 1 миллион уникальных значений, а колонка order_date только 100, индекс с customer_id первым будет более эффективен для поиска.
3. Использование индексов для операций JOIN
Индексы на колонках, участвующих в операциях JOIN, могут значительно ускорить выполнение составных запросов. Особенно это важно, если соединяются большие таблицы. Индекс на колонке, по которой происходит соединение, позволяет СУБД быстрее находить соответствующие строки, минимизируя количество операций поиска.
4. Оптимизация с помощью частичных индексов
Если запросы часто фильтруют данные по определенному значению или диапазону, можно использовать частичные индексы. Например, индекс на колонке status только для значений «active» может ускорить выполнение запросов, если это условие часто встречается в запросах.
5. Индексы и операции OR
Операции OR могут привести к полному сканированию таблицы, если индекс применяется только к одной из сторон выражения. Для оптимизации таких запросов можно использовать несколько индексов, а затем воспользоваться операцией UNION, чтобы объединить результаты, минимизируя нагрузку на систему.
6. Оценка и тестирование индексов
Прежде чем добавлять индексы, важно оценить их влияние на производительность. Индексы улучшают скорость выборки, но могут замедлить вставку, обновление и удаление данных. Поэтому перед применением индекса необходимо тестировать его влияние на реальные запросы с помощью EXPLAIN PLAN или других инструментов анализа выполнения запросов.
Преимущества и ограничения использования составных запросов в больших базах данных
Преимущества составных запросов
Одним из ключевых преимуществ составных запросов является возможность объединения данных из нескольких таблиц с минимальными усилиями. При работе с большими базами данных составные запросы позволяют эффективно агрегировать информацию, избегая необходимости повторного выполнения запросов и сокращая количество операций с данными. Это существенно снижает нагрузку на сервер и повышает общую производительность.
Кроме того, составные запросы позволяют значительно упростить структуру запросов, заменяя множество отдельных операций одной комплексной командой. В больших системах, где база данных может включать десятки и сотни таблиц, это особенно важно для упрощения поддержки и разработки новых функций. Такой подход повышает гибкость при изменении схемы базы данных и позволяет быстрее адаптироваться к изменениям в бизнес-логике.
Ограничения составных запросов
Однако, несмотря на преимущества, использование составных запросов в крупных базах данных связано с рядом ограничений. Одной из основных проблем является ухудшение производительности при сложных соединениях между таблицами. Когда количество записей в таблицах значительно увеличивается, запросы, содержащие несколько JOIN-операторов, могут стать чрезвычайно ресурсоемкими. Это приводит к увеличению времени обработки запросов и нагрузке на процессор, особенно если база данных не оптимизирована должным образом.
Другим ограничением является сложность оптимизации запросов. В больших системах, где составные запросы могут включать сотни условий и объединений, становится труднее предсказать поведение системы и эффективно индексировать таблицы для быстрого доступа. Это также делает отладку запросов более трудоемким процессом.
Наконец, составные запросы часто оказываются уязвимыми для ошибок в логике, особенно если запросы становятся слишком сложными. Малейшая ошибка в соединении таблиц или условии фильтрации может привести к некорректным результатам, что в свою очередь усложняет диагностику и исправление ошибок.
Рекомендации
Для оптимизации использования составных запросов рекомендуется правильно индексировать таблицы, обеспечивая быстрый доступ к данным. В случае работы с большими объемами информации стоит тщательно контролировать количество объединений и фильтров в запросах. Если составной запрос слишком сложен, его стоит разбить на несколько более простых запросов, которые можно выполнять поочередно, а затем объединить результаты. Также полезно использовать анализатор выполнения запросов для выявления узких мест и оптимизации процессов обработки данных.
Решение проблем с производительностью при использовании составных запросов
Первым шагом в оптимизации является использование подходящих индексов для колонок, участвующих в операциях соединения (JOIN) и фильтрации (WHERE). Индексы ускоряют поиск и сортировку данных, снижая время выполнения запросов. Однако важно учитывать, что избыточное количество индексов может негативно сказаться на скорости вставки и обновления данных, поэтому нужно соблюдать баланс.
Второй важный момент – это использование правильных типов соединений. Например, соединение типа INNER JOIN предпочтительнее, когда нужно получить данные, присутствующие в обеих таблицах. LEFT JOIN или RIGHT JOIN могут значительно увеличить время выполнения запроса, особенно если одна из таблиц имеет большие размеры и в ней много пустых значений.
Третья рекомендация – ограничить количество данных, обрабатываемых в запросе. Это можно сделать, используя операторы LIMIT или агрегатные функции. Например, для подсчета только нужных записей можно использовать COUNT с фильтрацией, исключая лишние строки с самого начала.
Использование подзапросов в составных запросах также может снижать производительность. Чтобы избежать излишней нагрузки, лучше заменить подзапросы на объединения (JOIN) или использовать оконные функции, которые часто выполняются быстрее.
Также стоит избегать работы с большими объемами данных, если это возможно. Например, разбиение запроса на несколько этапов с использованием временных таблиц может существенно улучшить производительность. При этом важно следить за тем, чтобы промежуточные данные не становились слишком громоздкими.
В случаях, когда составные запросы становятся слишком медленными, стоит рассмотреть возможность денормализации данных, то есть объединения часто запрашиваемых таблиц в одну. Это, однако, приведет к увеличению объема данных и сложности поддержания целостности, но может значительно ускорить выполнение запросов.
Наконец, использование оптимизатора запросов и анализ его рекомендаций может помочь выявить узкие места. Современные СУБД предлагают инструменты для анализа производительности, которые позволяют видеть, какие части запроса занимают больше всего времени, и оптимизировать их.
Вопрос-ответ:
Что такое составной запрос SQL?
Составной запрос SQL представляет собой запрос, состоящий из нескольких отдельных SQL-запросов, объединённых с помощью логических операторов, таких как `AND`, `OR`, или с использованием ключевых слов, например, `UNION` или `JOIN`. Составной запрос позволяет извлекать данные из нескольких таблиц или выполнять более сложные операции, комбинируя результаты различных запросов.
Как составные запросы могут помочь при анализе данных в базе данных?
Составные запросы значительно облегчают работу с базами данных, позволяя комбинировать результаты нескольких запросов в один. Например, используя операторы `JOIN`, можно объединить данные из разных таблиц, а с помощью `UNION` — объединить результаты нескольких запросов в один список. Это особенно полезно при анализе больших объёмов данных, где важно учитывать различные взаимосвязи и объединённые данные.
Что такое оператор JOIN и как он работает в составных запросах?
Оператор `JOIN` в SQL используется для объединения данных из двух или более таблиц по общим столбцам. Это позволяет извлекать связанные данные из разных таблиц в одном запросе. Например, если у вас есть таблица с заказами и таблица с клиентами, вы можете использовать `JOIN` для получения информации о заказах с данными о клиентах, если обе таблицы содержат общие поля, например, идентификатор клиента.
Чем отличается оператор UNION от оператора JOIN в составных запросах?
Операторы `UNION` и `JOIN` имеют различные цели. `JOIN` используется для объединения строк из двух таблиц на основе общего столбца, тогда как `UNION` комбинирует результаты двух или более запросов в одну таблицу, добавляя строки. В отличие от `JOIN`, `UNION` не требует общих столбцов и объединяет результат запросов по строкам, а не по столбцам.
Какие бывают типы соединений при использовании JOIN в составных запросах?
Существует несколько типов соединений в SQL: `INNER JOIN`, `LEFT JOIN`, `RIGHT JOIN`, и `FULL JOIN`. `INNER JOIN` возвращает только те строки, которые существуют в обеих таблицах. `LEFT JOIN` возвращает все строки из левой таблицы, даже если нет соответствующих строк в правой. `RIGHT JOIN` работает наоборот, возвращая все строки из правой таблицы. `FULL JOIN` возвращает все строки из обеих таблиц, заполняя пустые значения, где данных нет.





