

Создание таблиц – это первый шаг в организации данных в базе. Для успешной работы с SQL важно понимать, как правильно создавать таблицы, чтобы они были логичны и удобны для дальнейшей работы. Каждая таблица состоит из строк и столбцов, где строки содержат данные, а столбцы определяют типы этих данных. Рассмотрим основные моменты, которые стоит учитывать при создании таблиц в SQL.
Определение структуры таблицы начинается с использования команды CREATE TABLE, за которой следует название таблицы. Важно заранее планировать, какие данные будут храниться, какие поля обязательны, а какие могут быть пустыми. Например, если вам нужно создать таблицу пользователей, важно определить, что каждый пользователь должен иметь уникальный идентификатор, имя и дату регистрации.
Типы данных в SQL играют ключевую роль. Для каждого столбца выбирается соответствующий тип данных: INT для числовых значений, VARCHAR для строк, DATE для дат. Правильный выбор типа данных не только ускоряет выполнение запросов, но и минимизирует ошибки в будущем.
После указания типов данных можно задать ограничения. Это включает в себя NOT NULL для обязательных полей, PRIMARY KEY для уникальных идентификаторов и FOREIGN KEY для связей между таблицами. Не стоит пренебрегать этими ограничениями, так как они обеспечивают целостность данных и предотвращают появление дублирующих записей.
Чтобы создать таблицу, достаточно использовать следующую команду:
CREATE TABLE users ( id INT PRIMARY KEY, name VARCHAR(100) NOT NULL, registration_date DATE );
При добавлении данных в таблицу можно использовать команду INSERT INTO, а для извлечения – SELECT. Это основные операции, которые нужно освоить после создания таблицы, чтобы эффективно работать с базой данных.
Создание таблицы с помощью команды CREATE TABLE
Команда CREATE TABLE используется для создания новой таблицы в базе данных. Важно правильно указать все необходимые параметры, чтобы структура таблицы соответствовала требованиям и обеспечивала эффективное хранение данных.
Основной синтаксис команды выглядит следующим образом:
CREATE TABLE имя_таблицы (
имя_столбца1 тип_данных [ограничения],
имя_столбца2 тип_данных [ограничения],
...
);Где:
имя_таблицы– название создаваемой таблицы;имя_столбца– название столбца;тип_данных– тип данных для столбца (например,INT,VARCHAR,DATEи т.д.);ограничения– дополнительные ограничения, такие какNOT NULL,PRIMARY KEY,UNIQUEи другие.
Пример создания таблицы с несколькими столбцами:
CREATE TABLE Employees (
id INT PRIMARY KEY,
name VARCHAR(100) NOT NULL,
birth_date DATE,
hire_date DATE,
salary DECIMAL(10, 2)
);В этом примере создается таблица Employees с пятью столбцами:
id– целочисленный идентификатор сотрудника, который является основным ключом (PRIMARY KEY);name– строка, не может быть пустой (NOT NULL);birth_date– дата рождения сотрудника;hire_date– дата приема на работу;salary– зарплата сотрудника, с точностью до двух знаков после запятой.
Рекомендуется при создании таблиц использовать следующее:
- Выбор подходящего типа данных для каждого столбца, чтобы избежать ошибок при вставке данных;
- Использование ограничений
NOT NULLдля обязательных полей; - Определение
PRIMARY KEYдля столбцов, которые будут уникальными идентификаторами записей; - Учет индексов для ускорения запросов (их можно добавлять позднее).
Важное замечание: при создании таблицы можно также добавить внешний ключ (FOREIGN KEY), который устанавливает связь между таблицами, а также индексы для ускорения запросов.
Пример добавления внешнего ключа:
CREATE TABLE Orders (
order_id INT PRIMARY KEY,
order_date DATE,
employee_id INT,
FOREIGN KEY (employee_id) REFERENCES Employees(id)
);Здесь внешний ключ employee_id связывает таблицу Orders с таблицей Employees, обеспечивая целостность данных.
Определение типов данных для столбцов таблицы
При создании таблиц в SQL важно правильно выбрать типы данных для каждого столбца, так как это влияет на производительность, точность и ограничения хранения данных. Типы данных делятся на несколько категорий: числовые, строковые, дата и время, логические и бинарные.
Для числовых значений чаще всего используются типы INT, FLOAT, DECIMAL, где INT предназначен для целых чисел, а FLOAT и DECIMAL – для чисел с плавающей запятой. DECIMAL следует выбирать, когда необходима высокая точность, например, для финансовых данных. Тип FLOAT может использоваться для данных, где точность не столь критична, но важна скорость обработки.
Строковые данные представляют типы CHAR, VARCHAR и TEXT. CHAR используется для строк фиксированной длины, что подходит для кодов, номеров и других строк с постоянной длиной. VARCHAR эффективен для строк переменной длины, так как использует меньше памяти. TEXT применяется для хранения больших объемов текста, например, описаний или комментариев.
Типы данных для дат и времени включают DATE, TIME, DATETIME и TIMESTAMP. DATE хранит только дату, TIME – только время, DATETIME и TIMESTAMP – как дату, так и время. Разница между DATETIME и TIMESTAMP заключается в том, что TIMESTAMP хранит данные относительно времени на сервере, учитывая часовой пояс.
Логические значения хранятся с помощью типа BOOLEAN, который принимает значения TRUE или FALSE, и используется для хранения флагов или состояний.
Для бинарных данных применяются типы BINARY и VARBINARY, которые предназначены для хранения данных в виде последовательностей байтов, таких как изображения, файлы или другие неструктурированные данные.
Важно помнить, что выбор типа данных влияет на производительность системы. Например, использование VARCHAR вместо CHAR позволяет сэкономить память и улучшить производительность при работе с переменными по длине строками. Аналогично, тип INT предпочтительнее, чем BIGINT, если предполагаемый диапазон значений небольшой.
В некоторых СУБД могут быть дополнительные типы данных, такие как ENUM (ограниченный список значений) или UUID (универсально уникальный идентификатор), которые также могут быть полезны в зависимости от потребностей проекта.
Установка ограничений на столбцы: PRIMARY KEY и NOT NULL
Ограничения PRIMARY KEY и NOT NULL обеспечивают целостность данных в базе данных и помогают предотвратить ошибочные или неконсистентные записи. Эти ограничения применяются к столбцам при создании таблиц или могут быть добавлены позже через ALTER TABLE.
PRIMARY KEY – это ограничение, которое уникально идентифицирует каждую строку в таблице. Столбец, имеющий это ограничение, должен содержать уникальные значения и не может быть пустым. В случае многоколоночного ключа (композитного) все указанные столбцы в совокупности должны быть уникальными. PRIMARY KEY не может содержать NULL-значений, и в таблице может быть только один столбец с этим ограничением.
Пример создания таблицы с PRIMARY KEY:
CREATE TABLE employees ( employee_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50) );
NOT NULL – это ограничение, которое запрещает столбцу содержать NULL-значения. Оно часто используется для обязательных данных, таких как идентификаторы или ключевые атрибуты, которые должны быть всегда предоставлены. Важно помнить, что NOT NULL не гарантирует уникальности значений, оно лишь обеспечивает наличие данных в столбце.
Пример использования NOT NULL в определении столбца:
CREATE TABLE products ( product_id INT PRIMARY KEY, product_name VARCHAR(100) NOT NULL, price DECIMAL(10, 2) NOT NULL );
При добавлении данных в таблицу с ограничениями PRIMARY KEY и NOT NULL важно соблюдать правила. Например, если попытаться вставить строку с NULL-значением в столбец, на который наложено ограничение NOT NULL, система выдаст ошибку. Также вставка дублирующихся значений в столбец с PRIMARY KEY будет невозможна.
Рекомендуется использовать эти ограничения для обеспечения точности данных и предотвращения ошибок при вставке, обновлении или удалении записей в базе данных.
Добавление внешних ключей для связи таблиц
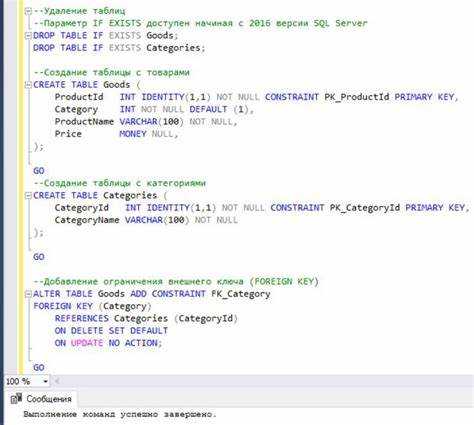
Внешний ключ (FOREIGN KEY) используется для создания связи между таблицами базы данных. Он обеспечивает ссылочную целостность данных, предотвращая появление записей с неверными ссылками на другие таблицы. Внешний ключ ссылается на первичный ключ (или уникальный ключ) другой таблицы и гарантирует, что значения в поле внешнего ключа будут существовать в таблице, на которую ссылаются.
Для добавления внешнего ключа в таблицу используется ключевое слово FOREIGN KEY в запросе CREATE TABLE или ALTER TABLE. Внешний ключ может быть добавлен сразу при создании таблицы или после, если таблица уже существует.
Пример создания таблиц с внешним ключом:
CREATE TABLE departments (
department_id INT PRIMARY KEY,
department_name VARCHAR(100)
);
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
employee_name VARCHAR(100),
department_id INT,
FOREIGN KEY (department_id) REFERENCES departments(department_id)
);
В этом примере таблица employees ссылается на таблицу departments через поле department_id, которое является внешним ключом. Это гарантирует, что каждый сотрудник будет привязан к существующему департаменту.
Добавление внешнего ключа в уже существующую таблицу:
ALTER TABLE employees
ADD CONSTRAINT fk_department
FOREIGN KEY (department_id)
REFERENCES departments(department_id);
Если внешние ключи уже используются, важно учитывать несколько факторов. Например, при удалении записи из таблицы, на которую ссылаются, база данных может автоматически удалять или обновлять связанные записи, если это предусмотрено при создании внешнего ключа. Эти операции контролируются через параметры ON DELETE и ON UPDATE.
Пример с каскадным удалением и обновлением:
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
employee_name VARCHAR(100),
department_id INT,
FOREIGN KEY (department_id)
REFERENCES departments(department_id)
ON DELETE CASCADE
ON UPDATE CASCADE
);
Каскадное удаление (ON DELETE CASCADE) означает, что если удаляется департамент, все сотрудники, относящиеся к этому департаменту, также будут удалены. Каскадное обновление (ON UPDATE CASCADE) позволяет автоматически обновлять значения внешнего ключа, если первичный ключ в родительской таблице изменился.
Добавление ограничений внешних ключей помогает поддерживать целостность данных и упрощает работу с многими таблицами в одной базе данных, обеспечивая связи между сущностями.
Использование автоинкремента для уникальных идентификаторов
Для реализации автоинкремента в различных СУБД существуют свои особенности синтаксиса. В MySQL, PostgreSQL и SQLite автоинкремент чаще всего используется для целочисленных полей. В MySQL это достигается с помощью ключевого слова AUTO_INCREMENT, в PostgreSQL – через тип данных SERIAL, а в SQLite автоинкремент реализуется с помощью типа данных INTEGER PRIMARY KEY.
Пример создания таблицы с автоинкрементируемым полем в MySQL:
CREATE TABLE users ( id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(100) );
В приведённом примере поле id будет автоматически увеличиваться на 1 при каждой вставке новой строки в таблицу. Таким образом, вы получаете уникальный идентификатор для каждой записи без необходимости вручную указывать его значение.
Важно учитывать, что автоинкремент всегда работает по принципу увеличения значений. В случае удаления строки, значение идентификатора для следующей записи не будет уменьшаться. Это позволяет избежать дублирования, но может привести к незначительному «пустому» пространству в последовательности идентификаторов.
Автоинкремент удобно использовать, когда нужно обеспечить уникальность идентификаторов и упростить управление данными, избавляя от необходимости отслеживать и вручную увеличивать значения. Однако, для некоторых случаев, например, при распределённых системах или при необходимости использования определённых значений идентификаторов, автоинкремент может быть не лучшим решением.
Для контроля над последовательностью автоинкремента в MySQL можно использовать команду ALTER TABLE для изменения начального значения или шага увеличения. Например:
ALTER TABLE users AUTO_INCREMENT = 1000;
В случае, если нужно сбросить автоинкремент и начать нумерацию с первого значения, это также можно сделать с помощью команды:
ALTER TABLE users AUTO_INCREMENT = 1;
В PostgreSQL и SQLite управление последовательностью автоинкремента возможно через работу с последовательностями (sequence). Эти подходы более гибкие и позволяют вручную задавать минимальные и максимальные значения, а также шаг увеличения.
Редактирование структуры таблицы с помощью ALTER TABLE
Команда ALTER TABLE в SQL используется для изменения структуры уже существующих таблиц. С её помощью можно добавлять, удалять или изменять столбцы, а также менять типы данных и ограничения. Все эти изменения можно выполнить без потери данных, однако, следует учитывать, что некоторые операции могут повлиять на производительность и требовать блокировки таблицы.
Добавление столбца: Чтобы добавить новый столбец в таблицу, используется синтаксис:
ALTER TABLE имя_таблицы ADD имя_столбца тип_данных;
Пример:
ALTER TABLE employees ADD date_of_birth DATE;
В этом примере добавляется новый столбец с именем date_of_birth, который будет хранить дату рождения сотрудников.
Удаление столбца: Для удаления столбца используется команда DROP COLUMN. Удаление столбца невозможно, если на него есть ссылки через внешние ключи или индексы.
ALTER TABLE имя_таблицы DROP COLUMN имя_столбца;
Пример:
ALTER TABLE employees DROP COLUMN date_of_birth;
Изменение типа данных столбца: Если требуется изменить тип данных уже существующего столбца, используется команда MODIFY COLUMN. Важно помнить, что изменение типа данных может привести к потере информации, если новый тип не может содержать данные старого типа.
ALTER TABLE имя_таблицы MODIFY COLUMN имя_столбца новый_тип;
Пример:
ALTER TABLE employees MODIFY COLUMN salary DECIMAL(10, 2);
В этом примере изменяется тип столбца salary на DECIMAL с точностью до двух знаков после запятой.
Переименование столбца: В некоторых СУБД для переименования столбца используется команда RENAME COLUMN. Однако, этот функционал доступен не во всех системах, и в некоторых случаях может потребоваться выполнение дополнительных операций, таких как создание нового столбца и перенос данных.
ALTER TABLE имя_таблицы RENAME COLUMN старое_имя TO новое_имя;
Пример:
ALTER TABLE employees RENAME COLUMN date_of_birth TO birth_date;
Изменение ограничений: Для изменения или удаления ограничений (например, уникальности или ограничения на NULL) используются отдельные команды. Например, для удаления ограничения уникальности:
ALTER TABLE имя_таблицы DROP CONSTRAINT имя_ограничения;
Пример:
ALTER TABLE employees DROP CONSTRAINT unique_email;
Важно: При работе с ALTER TABLE важно учитывать, что не все операции поддерживаются в каждой СУБД, а также возможны ограничения по типам данных или наличию связей с другими таблицами. Рекомендуется всегда проверять документацию вашей СУБД перед выполнением изменения.
Удаление таблицы: когда и как правильно использовать DROP TABLE
Команда DROP TABLE используется для удаления таблицы из базы данных. Это необратимая операция, поэтому важно понимать, когда и как правильно применять эту команду. Ниже приведены ключевые моменты, которые помогут избежать ошибок при удалении таблиц.
Когда следует использовать DROP TABLE?
- Когда таблица больше не нужна для хранения данных или для других операций в базе данных.
- Когда требуется удалить таблицу для освобождения ресурсов базы данных (например, пространства на диске).
- Когда таблица была создана для тестирования, и ее данные больше не актуальны.
Как использовать DROP TABLE?
- Основной синтаксис команды:
DROP TABLE имя_таблицы;
- Удаление нескольких таблиц:
DROP TABLE таблица1, таблица2;
- Для предотвращения ошибок можно использовать оператор
IF EXISTS, который проверяет существование таблицы перед удалением:DROP TABLE IF EXISTS имя_таблицы;
Что нужно учитывать перед удалением таблицы?
- Удаление таблицы приводит к потере всех данных в ней. Если данные важны, сделайте резервную копию перед удалением.
- Все зависимости, такие как внешние ключи или индексы, связанные с удаляемой таблицей, будут также удалены, что может повлиять на другие таблицы.
- В некоторых случаях может потребоваться удалить связи между таблицами через команды
DROP CONSTRAINTили удалить индексы с помощьюDROP INDEX.
Риски и лучшие практики:
- Будьте осторожны при использовании команды в продакшн-среде. Лучше заранее протестировать операцию на копии базы данных.
- Проверьте, нет ли внешних зависимостей или ссылок на таблицу, которые могут вызвать ошибку или неожиданное поведение.
- Регулярно делайте бэкапы перед удалением данных, особенно если таблица содержит критически важную информацию.
Команда DROP TABLE – мощный инструмент, который следует использовать с осторожностью. При правильном подходе она позволяет эффективно управлять схемой базы данных, избегая накопления ненужных объектов.
Вопрос-ответ:
Можно ли создать таблицу без указания первичного ключа?
Да, можно создать таблицу без первичного ключа, но это не рекомендуется. Хотя SQL позволяет создать таблицу без этого ограничения, отсутствие первичного ключа может привести к проблемам с уникальностью строк и затруднить работу с таблицей в будущем. Если вам не нужно уникальное ограничение для строк, вы можете не указывать первичный ключ, но все равно важно контролировать уникальность данных с помощью других средств, например, через ограничения или индексы.





