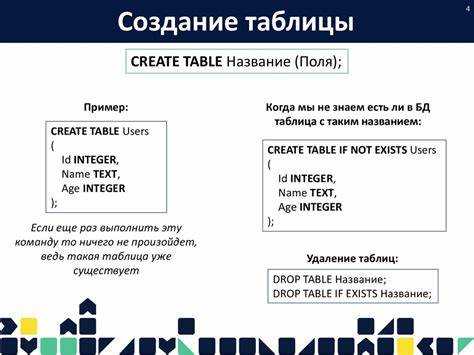
В SQL существует десять основных классов данных, которые играют важную роль в проектировании и эксплуатации баз данных. Эти классы данных включают как простые типы, такие как числа и строки, так и более сложные, такие как временные метки или географические объекты. Понимание этих типов данных позволяет разработчикам правильно выбирать типы для каждого столбца в таблицах, что напрямую влияет на производительность и гибкость системы.
Каждый класс данных имеет свою специфику, позволяя хранить информацию в разных форматах. Например, классы данных для работы с числами могут включать INTEGER, BIGINT или DECIMAL, в то время как текстовые данные могут быть представлены с помощью VARCHAR или TEXT. Важно помнить, что выбор между этими типами данных может существенно повлиять на хранение данных, их скорость обработки и использование памяти.
Оптимизация структуры базы данных часто требует знаний о том, какие классы данных обеспечивают наибольшую эффективность при работе с различными типами запросов. Например, для числовых значений, требующих точности до нескольких знаков после запятой, лучше использовать DECIMAL, тогда как для быстрого выполнения арифметических операций подойдут типы INTEGER или FLOAT.
Для правильного проектирования базы данных важно учитывать не только специфику данных, но и особенности работы с ними в контексте конкретной системы управления базами данных (СУБД). Разные СУБД могут иметь разные реализации тех же классов данных, что также влияет на их использование и совместимость. Поэтому всегда следует проверять документацию к конкретной СУБД для оптимального выбора типов данных в зависимости от требований проекта.
Как определить количество классов SQL в базе данных

Для определения количества классов SQL в базе данных можно воспользоваться системными представлениями или запросами, которые возвращают информацию о структуре базы данных. В большинстве СУБД (систем управления базами данных) существует набор таблиц, представляющих метаданные, включая данные о таблицах, индексах, процедурах и других объектах.
В случае SQL Server, информацию о классах можно получить через системное представление sys.objects, которое содержит данные обо всех объектах в базе данных. Для подсчета числа различных классов SQL (например, таблиц, представлений, хранимых процедур) можно использовать следующий запрос:
SELECT type, COUNT(*) AS count
FROM sys.objects
WHERE type IN ('U', 'V', 'P', 'FN', 'TF', 'IF', 'TR')
GROUP BY type;Этот запрос возвращает количество объектов по типам, где:
U– таблицы пользователяV– представленияP– хранимые процедурыFN– скалярные функцииTF– табличные функцииIF– инлайн-функцииTR– триггеры
В PostgreSQL для получения аналогичной информации можно использовать системную таблицу pg_catalog.pg_class, которая содержит данные о всех объектах базы данных. Пример запроса для подсчета классов:
SELECT relkind, COUNT(*)
FROM pg_catalog.pg_class
WHERE relkind IN ('r', 'v', 'm', 'f')
GROUP BY relkind;Здесь:
r– обычные таблицыv– представленияm– материальные представленияf– функции
В MySQL для подсчета количества объектов можно использовать запрос к таблице information_schema.tables и information_schema.routines, где хранятся данные о таблицах и процедурах соответственно:
SELECT COUNT(*)
FROM information_schema.tables
WHERE table_schema = 'имя_базы';SELECT COUNT(*)
FROM information_schema.routines
WHERE routine_schema = 'имя_базы';Количество классов SQL зависит от специфики СУБД, однако общий подход к подсчету остается схожим: необходимо искать объекты, связанные с таблицами, представлениями, функциями и процедурами, и использовать фильтрацию по типу объекта.
Методы создания классов SQL для организации данных
Для эффективного управления данными в базе данных применяются различные методы создания классов SQL. Эти классы играют важную роль в структуре данных, обеспечивая доступ к нужной информации и повышая производительность запросов. Основные методы включают:
1. Нормализация данных
Нормализация помогает избежать избыточности и аномалий данных. Создание классов SQL начинается с деления таблиц на несколько взаимосвязанных, что позволяет избежать повторений и упрощает обновления данных. Важно учитывать до какой нормальной формы нужно довести таблицу для достижения оптимальной структуры.
2. Использование индексов
Индексы ускоряют поиск и сортировку данных. При создании классов SQL нужно заранее продумать, какие поля будут использоваться для фильтрации, сортировки или объединения таблиц. Индексы на эти поля значительно ускорят работу с базой данных, но они также могут замедлить операции вставки и обновления.
3. Внешние ключи
Внешние ключи обеспечивают целостность данных, связывая таблицы между собой. При проектировании классов SQL необходимо определить, какие таблицы будут иметь связи с другими, а также гарантировать целостность при удалении или обновлении записей, чтобы избежать «осиротевших» записей.
4. Использование представлений
Представления (views) позволяют создавать логические представления данных без их дублирования. Они особенно полезны, когда нужно скрыть сложные запросы или объединить данные из нескольких таблиц в одном объекте. Важно помнить, что представления могут негативно влиять на производительность при больших объемах данных.
5. Хранимые процедуры
Хранимые процедуры – это наборы SQL-запросов, которые выполняются на сервере. Они помогают автоматизировать операции, такие как вставка, обновление или удаление данных. Хранимые процедуры также повышают безопасность, ограничивая доступ к данным только через определенные механизмы обработки.
6. Разбиение таблиц (partitioning)
Когда данные становятся слишком большими, разбиение таблиц может повысить производительность. В SQL можно разделить большие таблицы на более мелкие, что ускоряет обработку запросов. Разбиение может быть выполнено по диапазону значений, по списку значений или по хешированию.
7. Триггеры
Триггеры позволяют автоматически выполнять действия в ответ на изменения данных. Они полезны для реализации бизнес-логики или аудита. Однако важно использовать триггеры с осторожностью, так как они могут замедлить выполнение транзакций.
Каждый из этих методов может быть использован в зависимости от требований к базе данных, объема информации и типа приложений, работающих с данными. Для достижения оптимальной производительности и удобства работы важно грамотно комбинировать несколько методов, учитывая специфику проекта.
Применение классов SQL для оптимизации запросов
Использование классов SQL может значительно улучшить производительность запросов за счёт правильного структурирования и выполнения операций с данными. Рассмотрим несколько подходов, которые помогут достичь оптимизации.
1. Индексация и выбор классов для запросов
Классы, такие как PRIMARY KEY, UNIQUE, INDEX позволяют базе данных быстро находить нужные строки, снижая нагрузку на процессор при выполнении запросов. Наличие индексов на полях, часто используемых в условиях WHERE, значительно сокращает время выполнения. Однако важно избегать избыточных индексов, так как они могут замедлить операции вставки и обновления данных.
При взаимодействии с классами SQL важно грамотно обрабатывать ошибки для предотвращения сбоев и утечек данных. Прежде всего, нужно уделить внимание правильной настройке механизмов отлова ошибок на уровне самого SQL-класса. Обычно ошибки можно разделить на две категории: синтаксические и логические.
Для синтаксических ошибок важно проверять SQL-запросы перед их выполнением. Один из подходов – использовать механизмы параметризации запросов, чтобы избежать SQL-инъекций и улучшить обработку исключений. В случае с логическими ошибками полезно применять обработку ошибок с помощью транзакций. Это позволит откатить изменения, если операция не завершилась корректно.
Для обработки ошибок на уровне классов SQL стоит использовать блоки try-catch (или аналогичные механизмы, доступные в языке программирования). В блоке catch необходимо не только вывести сообщение об ошибке, но и зарегистрировать все подробности, включая исходный SQL-запрос, параметры и стек вызовов. Это поможет в будущем устранить ошибки и ускорить поиск причин сбоя.
Для работы с транзакциями важно убедиться в наличии механизмов автоматического отката при возникновении ошибок. В случае, если класс SQL выполняет несколько операций, нужно гарантировать, что все они будут либо успешно завершены, либо откатятся без частичных изменений в базе данных. Это достигается с помощью команд COMMIT и ROLLBACK, которые необходимо правильно размещать в коде.
Особое внимание стоит уделить обработке ошибок при подключении к базе данных. Часто проблема кроется в неверных учетных данных, недоступности базы или ошибках в настройке соединений. В таких случаях важна не только генерация сообщения об ошибке, но и восстановление соединения, если это возможно, или же корректное завершение работы с соответствующим уведомлением.
Важным аспектом является логирование ошибок. Все исключения, возникающие в классе SQL, должны записываться в лог-файлы, с указанием типа ошибки, времени её возникновения и контекста. Это не только поможет в диагностике проблем, но и обеспечит возможность анализа производительности системы в будущем.
Наконец, стоит помнить о производительности. Постоянная проверка ошибок может значительно замедлить выполнение операций, особенно при частых запросах к базе. Поэтому важно выстраивать баланс между тщательной обработкой исключений и быстродействием системы, используя, например, отложенное логирование или оптимизацию частых операций.
Влияние классов SQL на производительность базы данных
При проектировании базы данных выбор классов SQL может значительно повлиять на её производительность. Важно учитывать типы запросов, их частоту и сложность, чтобы правильно распределить нагрузку между классами и минимизировать избыточные операции.
Каждый класс SQL отвечает за выполнение определённых операций, таких как выборка данных, их вставка, обновление или удаление. Оптимизация этих операций критична для производительности системы, особенно при работе с большими объёмами данных.
- Класс 1: SELECT – основной класс для выборки данных. Эффективность запросов в этом классе зависит от индексов, структуры данных и наличия фильтров. Некорректно построенные SELECT-запросы могут привести к излишним операциям поиска и увеличению времени ответа.
- Класс 2: INSERT – вставка данных. При большом объёме вставок важно избегать блокировок и использовать пакетные вставки, что снижает нагрузку на сервер.
- Класс 3: UPDATE – обновление данных. Оптимизация таких запросов требует внимательного подхода к индексированию и минимизации пересчёта данных, особенно при большом объёме строк.
- Класс 4: DELETE – удаление данных. Плохое управление удалением может привести к фрагментации таблиц, что увеличивает время выполнения операций. Регулярная оптимизация таблиц необходима для предотвращения деградации производительности.
Негативное влияние на производительность может возникнуть, если запросы в разных классах SQL выполняются без должной оптимизации. Например, частые полные сканирования таблиц или использование избыточных соединений может вызвать значительные задержки в работе базы данных.
Рекомендации по улучшению производительности:
- Использование индексов для ускорения SELECT-запросов и минимизации сканирования таблиц.
- Применение транзакций для сокращения накладных расходов при массовых вставках и обновлениях.
- Периодическая очистка и реорганизация таблиц для уменьшения фрагментации после частых удалений.
- Использование параметризированных запросов и кэширования для уменьшения повторных вычислений и обращения к базе данных.
Классы SQL могут значительно повлиять на работу базы данных как в положительную, так и в отрицательную сторону. Важно грамотно подходить к проектированию запросов и их оптимизации для повышения общей производительности системы.
Лучшие практики использования классов SQL в крупных проектах

В крупных проектах использование классов SQL позволяет значительно упростить управление запросами и повысить производительность. Для эффективного применения классов SQL в таких проектах важно придерживаться ряда рекомендаций.
1. Строгая структура классов помогает избежать дублирования кода. Разделяйте классы по функционалу: один класс для операций с пользователями, другой – для работы с заказами и так далее. Это не только улучшает читаемость, но и упрощает сопровождение кода.
2. Использование ORM в сочетании с классами SQL значительно ускоряет разработку. Важно грамотно настроить ORM-связи, чтобы запросы выполнялись эффективно, а код оставался чистым и легко расширяемым. Ручные SQL-запросы должны использоваться только в тех случаях, когда ORM не может предоставить нужную производительность или функциональность.
3. Обработка ошибок в классах SQL требует особого внимания. Каждый запрос должен быть обернут в обработчик исключений. Это позволяет избежать потери данных при сбоях и обеспечивает более точное локализование проблем в коде.
4. Кэширование результатов для часто выполняемых запросов позволяет значительно снизить нагрузку на базу данных. Для этого можно использовать внутренние механизмы кэширования, встроенные в классы, или сторонние библиотеки. Кэширование особенно эффективно для запросов с одинаковыми параметрами, которые часто повторяются.
5. Параметризация запросов защищает от SQL-инъекций и улучшает производительность. Всегда используйте параметры вместо конкатенации строк для создания запросов. Это повышает безопасность и упрощает работу с динамическими запросами.
6. Логирование запросов необходимо для мониторинга работы системы. Включайте логирование SQL-запросов для отслеживания медленных или ошибочных запросов, что поможет вовремя выявить узкие места в базе данных.
7. Индексация – ключ к повышению скорости выполнения запросов. Правильное использование индексов на часто используемых полях позволяет уменьшить время ответа запросов. Однако важно избегать излишней индексации, так как это может замедлить вставку или обновление данных.
8. Использование транзакций для обеспечения целостности данных. В крупных проектах, где данные могут обновляться несколькими пользователями одновременно, важно правильно использовать транзакции для поддержания консистентности базы данных.
9. Профилирование запросов помогает выявить узкие места в работе с базой данных. Регулярное использование инструментов для анализа времени выполнения запросов позволяет оперативно оптимизировать их.
10. Обновление классов SQL должно проводиться с учётом изменений в бизнес-логике. Периодическое ревью и рефакторинг классов позволяет обеспечить их актуальность и улучшить производительность при масштабировании проекта.
Вопрос-ответ:
Что такое 10 классов SQL в базе данных?
10 классов SQL в базе данных — это набор различных типов операций и структур, используемых для организации и обработки данных. Каждый класс включает в себя определённые команды и методы, такие как манипуляции с таблицами, индексами, запросами и транзакциями. Эти классы помогают структурировать взаимодействие с базой данных и упрощают её управление.
Как 10 классов SQL влияют на производительность базы данных?
Производительность базы данных напрямую зависит от того, как используются 10 классов SQL. Например, правильное использование индексов, нормализация данных и оптимизация запросов может значительно улучшить скорость обработки. В то же время неэффективное использование некоторых команд может привести к замедлению работы системы, так как определённые операции требуют больших ресурсов.
Могут ли 10 классов SQL влиять на безопасность базы данных?
Да, классы SQL могут играть важную роль в обеспечении безопасности базы данных. Например, работа с транзакциями позволяет гарантировать целостность данных, а правильное использование механизмов доступа помогает ограничить права пользователей. Также важно следить за тем, чтобы запросы не приводили к уязвимостям, таким как SQL-инъекции.
Как можно организовать работу с 10 классами SQL в большой базе данных?
Для работы с 10 классами SQL в крупных базах данных требуется тщательное проектирование. Это включает в себя создание индексов для ускорения поиска, нормализацию данных для устранения избыточности и использование эффективных запросов для минимизации нагрузки на сервер. Также важно правильно распределять нагрузку и использовать механизмы кеширования для повышения производительности.
Какие классы SQL более важны при разработке сложных приложений?
Для сложных приложений важны те классы SQL, которые обеспечивают эффективное управление данными и минимизацию ошибок. Особенно это касается транзакций для обеспечения целостности данных и использования подзапросов и объединений для сложных выборок. Оптимизация запросов также играет ключевую роль в поддержании стабильной работы системы.