SQL (Structured Query Language) является стандартом для работы с реляционными базами данных и используется для выполнения различных операций: от извлечения данных до их обновления. Одним из главных преимуществ SQL является его универсальность. С помощью SQL можно работать с данными в любых реляционных системах управления базами данных (СУБД), таких как MySQL, PostgreSQL, Oracle и Microsoft SQL Server. Это позволяет пользователям и разработчикам выбирать наиболее подходящую СУБД, не привязываясь к конкретным инструментам для работы с данными.
Одной из ключевых особенностей SQL является его способность эффективно обрабатывать большие объемы данных. Благодаря продвинутым механизмам оптимизации запросов, СУБД могут выполнять сложные операции с минимальными затратами ресурсов. Например, индексация и использование продвинутых алгоритмов для поиска позволяют ускорить выборку данных в миллионы раз, что особенно важно для крупных компаний, работающих с большими объемами информации.
SQL предоставляет четкую структуру запросов, что делает язык доступным для обучения и использования. Запросы SQL имеют интуитивно понятный синтаксис, который легко понять даже новичкам в программировании. Это значительно ускоряет процесс интеграции новых сотрудников в рабочие процессы, так как для работы с базами данных не требуется глубоких знаний в области программирования.
Другим важным аспектом является высокая степень безопасности работы с данными. SQL позволяет настроить точный контроль доступа на уровне пользователей и ролей, а также реализовать механизмы защиты от SQL-инъекций, что существенно снижает риски при работе с конфиденциальной информацией. Дополнительно, регулярное обновление SQL-баз данных и их компонентов помогает минимизировать угрозы безопасности.
SQL поддерживает стандарты ACID, что означает высокую степень надежности транзакций. Это обеспечивает атомарность, консистентность, изоляцию и долговечность всех операций с данными, делая работу с базами данных стабильной и предсказуемой. В случае сбоя системы, данные не будут повреждены, и все транзакции можно будет восстановить до последнего успешного состояния.
Упрощение работы с большими объемами данных через SQL-запросы

Оптимизация поиска данных в больших объемах обеспечивается такими средствами, как индексы, которые значительно ускоряют выполнение запросов. Например, индексы на часто используемые поля (например, ключи и даты) позволяют уменьшить время на выборку данных в несколько раз, особенно при работе с таблицами, содержащими сотни тысяч или миллионы строк.
Использование агрегатных функций, таких как SUM(), AVG(), COUNT(), позволяет свести к минимуму количество операций, которые необходимо выполнить на уровне приложения. Это важно, когда нужно вычислить, например, среднее значение по большому числу записей или подсчитать количество записей, соответствующих определенному условию.
Для обработки больших объемов данных можно использовать параллельное выполнение запросов, что ускоряет операции. Многие современные СУБД поддерживают параллельную обработку запросов, что позволяет распределить нагрузку и ускорить выполнение операций над данными, особенно при работе с многопроцессорными системами.
Еще одно важное преимущество SQL – это поддержка объединений (JOIN), которые позволяют работать с несколькими таблицами одновременно. Это существенно упрощает работу с нормализованными данными, так как позволяет избежать дублирования информации и минимизировать ошибки при манипуляциях с большими объемами.
Фильтрация данных с помощью WHERE позволяет заранее исключить ненужные записи, что также ускоряет выполнение запросов. Применение сложных условий фильтрации снижает объем данных, которые необходимо обработать, что особенно важно при анализе больших баз данных.
Таким образом, использование SQL-запросов для работы с большими объемами данных дает возможность не только ускорить процессы обработки и анализа, но и значительно повысить их точность и надежность. Результаты, полученные с помощью SQL, могут быть интегрированы с другими инструментами аналитики и отчетности, что делает SQL незаменимым инструментом в современной работе с данными.
Как SQL помогает в обеспечении целостности данных
Первый важный механизм – это ограничения уникальности данных, такие как PRIMARY KEY и UNIQUE. Они гарантируют, что каждая запись в таблице имеет уникальный идентификатор. PRIMARY KEY не только обеспечивает уникальность, но и устанавливает обязательность заполнения столбца, что важно для идентификации данных и связи между таблицами.
Ограничение FOREIGN KEY поддерживает ссылочную целостность. Оно требует, чтобы значение в одном столбце соответствовало значениям в другом столбце другой таблицы. Это предотвращает создание «осиротевших» записей, которые не могут быть связаны с другими данными в базе. Например, если в таблице заказов используется столбец customer_id, то его значение должно совпадать с идентификатором клиента в таблице клиентов.
Ограничение CHECK позволяет задавать условия для значений в столбцах. Оно гарантирует, что данные, вводимые в таблицу, соответствуют заданным требованиям. Например, можно установить ограничение, чтобы возраст пользователя в базе данных был не меньше 18 лет. Это важный инструмент для предотвращения внесения неверных данных в таблицу на этапе их добавления.
Для обеспечения целостности данных в случае ошибок или сбоев используется механизм транзакций. SQL поддерживает атомарность операций, что позволяет выполнять несколько операций в рамках одной транзакции. Если одна из операций не удалась, можно откатить изменения, не нарушая целостности данных. Это особенно важно при работе с критичными данными, где любое нарушение может привести к серьезным последствиям.
Наконец, регулярные процедуры резервного копирования и восстановления данных также способствуют сохранению целостности. Хотя это и не является прямым механизмом SQL, использование встроенных функций для создания резервных копий данных и восстановления в случае ошибок помогает гарантировать безопасность и целостность данных.
Использование SQL для быстрой обработки запросов к базам данных

SQL (Structured Query Language) предоставляет мощные инструменты для работы с большими объемами данных, позволяя эффективно выполнять запросы и манипулировать данными. Применение SQL для обработки запросов в базах данных имеет ряд специфических преимуществ, особенно в контексте производительности и оптимизации.
Одним из основных факторов, влияющих на скорость обработки запросов, является правильная структура запросов. Эффективное использование индексов, грамотная формулировка запросов и использование определённых методов могут значительно сократить время отклика базы данных.
- Использование индексов: Индексы в SQL позволяют значительно ускорить поиск данных. Индексы создаются на столбцах, которые часто используются в условиях WHERE или JOIN, что помогает минимизировать количество строк, которые нужно обработать. Неправильное использование индексов, например, на столбцах с низкой кардинальностью, может привести к ухудшению производительности.
- Оптимизация запросов с использованием EXPLAIN: В SQL можно использовать команду EXPLAIN, чтобы оценить, как будет выполняться запрос. Это позволяет выявить проблемные места, такие как избыточные соединения таблиц или ненужные подзапросы, и оптимизировать их для повышения производительности.
- Использование агрегатных функций: Агрегатные функции, такие как COUNT, SUM, AVG, позволяют значительно сократить количество данных, которые обрабатываются запросом. Вместо того, чтобы возвращать все строки, агрегированные данные могут быть переданы, что ускоряет время отклика.
- Предварительная фильтрация данных: Эффективная фильтрация данных на ранних стадиях запроса помогает уменьшить объем данных, с которым система должна работать. Например, использование WHERE в начале запроса помогает исключить ненужные строки, снижая нагрузку на сервер.
- Оптимизация JOIN-ов: При выполнении соединений между таблицами важно тщательно выбирать порядок соединений. Использование правильного типа JOIN (INNER, LEFT, RIGHT) и оптимизация порядка таблиц может существенно повлиять на производительность.
Кроме того, существует ряд способов улучшить скорость работы с базой данных, включая использование кеширования, ограничения на размер выборки и другие методы. Важно понимать, что каждый запрос уникален, и подходы к его оптимизации должны зависеть от специфики задачи.
Поддержка сложных операций объединения данных в SQL
SQL предоставляет мощные средства для выполнения сложных операций объединения данных из нескольких таблиц. Это критически важно для работы с большими и распределенными базами данных, где информация часто хранится в разных местах и требует объединения для анализа и принятия решений.
Основные операции объединения данных в SQL включают:
- INNER JOIN – возвращает только те строки, которые имеют совпадения в обеих таблицах. Это самый часто используемый тип объединения, обеспечивающий получение релевантной информации без лишних данных.
- LEFT JOIN – сохраняет все строки из левой таблицы, даже если в правой таблице нет совпадений. Такой подход полезен при необходимости сохранить всю информацию о сущности, даже если дополнительные данные отсутствуют.
- RIGHT JOIN – аналогичен LEFT JOIN, но сохраняет все строки из правой таблицы. Применяется реже, но может быть полезен при анализе данных, где важнее информация из правой таблицы.
- FULL OUTER JOIN – возвращает все строки из обеих таблиц, независимо от того, есть ли совпадения. Это объединение полезно, когда требуется увидеть полный набор данных, включая строки без соответствующих пар.
- CROSS JOIN – выполняет декартово произведение строк из двух таблиц, что приводит к значительному увеличению объема данных. Этот тип объединения используется для формирования всех возможных сочетаний данных из двух таблиц, но требует осторожности из-за возможных больших объемов результатов.
Для более сложных сценариев объединения, SQL также поддерживает:
- UNION – используется для объединения результатов нескольких запросов, но возвращает только уникальные строки. Это полезно при необходимости агрегировать данные из разных источников, устраняя дублирование.
- UNION ALL – аналогичен UNION, но сохраняет все строки, включая дубликаты. Такой подход может быть эффективен в случаях, когда важна каждая строка и дублирование не критично.
- SELF JOIN – позволяет объединить таблицу с самой собой. Это используется для работы с иерархическими данными или при необходимости сравнения строк внутри одной таблицы, например, для поиска связей между сущностями.
Для оптимизации производительности при выполнении сложных операций объединения данных важно учитывать следующее:
- Использование индексов на столбцах, по которым выполняются объединения, значительно улучшает скорость выполнения запросов.
- Сложные операции объединения должны быть максимально ограничены в количестве обрабатываемых данных с помощью фильтрации (WHERE) и агрегации (GROUP BY).
- Применение агрегатных функций (например, COUNT, SUM, AVG) после объединения данных позволяет сократить объем возвращаемой информации, делая результаты более понятными и удобными для анализа.
Применение этих техник в SQL позволяет не только эффективно объединять данные, но и значительно повышать производительность запросов, что критично для работы с большими и сложными базами данных.
Как SQL облегчает управление правами доступа и безопасностью данных
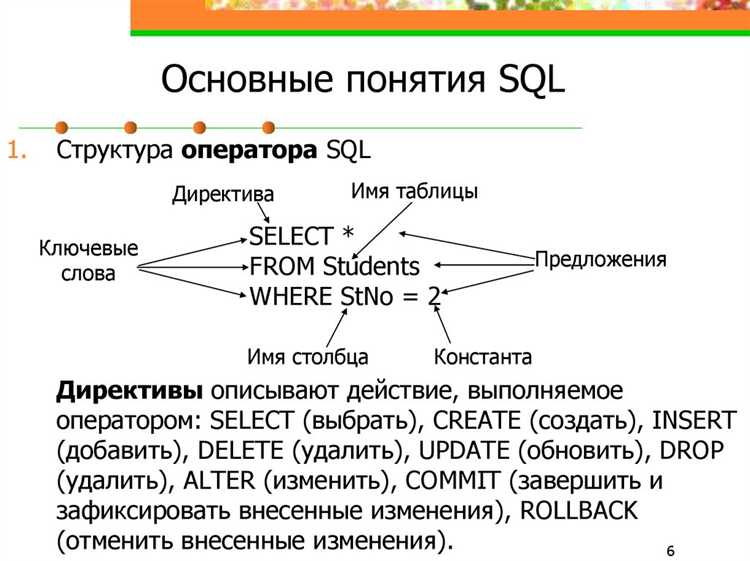
Для управления доступом SQL использует роли и права доступа. Роль – это набор прав, которые можно назначать пользователям. Это значительно упрощает администрирование, позволяя назначать несколько прав одновременно и избегать излишней детализации. Например, роль «read_only» предоставляет только права на чтение данных, ограничивая доступ к изменениям.
SQL также поддерживает механизм гранулированного доступа, позволяя устанавливать права на уровне отдельных таблиц, столбцов и строк. Это дает возможность настроить доступ не только ко всему набору данных, но и к его частям. Например, для работы с конфиденциальной информацией можно предоставить доступ только к определенным строкам таблицы через использование условий, таких как WHERE.
Еще одной важной функцией является использование авторизации через пароли и аутентификацию. SQL-серверы позволяют настроить многоуровневую аутентификацию, включая интеграцию с внешними сервисами (например, LDAP), что обеспечивает дополнительную защиту от несанкционированного доступа. Важно также регулярно менять пароли и использовать сложные методы шифрования для хранения учетных данных.
Для повышения безопасности SQL предлагает функции аудита, которые позволяют отслеживать действия пользователей в базе данных. Это помогает выявлять потенциальные угрозы и предотвращать несанкционированный доступ. Аудит может фиксировать, кто и когда выполнил определенные операции, например, изменения данных или настройки безопасности.
Системы SQL также поддерживают шифрование данных, как на уровне хранения, так и при передаче. Это минимизирует риски утечек информации при работе с конфиденциальными данными. Шифрование может быть настроено как на уровне столбцов, так и на уровне всей базы данных, что увеличивает защиту данных, особенно при работе через открытые сети.
В конечном итоге, использование SQL для управления правами доступа и безопасностью данных дает возможность создавать эффективные и безопасные системы, которые легко масштабируются и адаптируются к меняющимся требованиям безопасности.
Автоматизация задач по резервному копированию и восстановлению с SQL

Для автоматизации процесса резервного копирования в SQL можно использовать команду BACKUP DATABASE, которая позволяет создавать полные или инкрементальные резервные копии базы данных. Эти операции можно запланировать с помощью планировщика задач, такого как SQL Server Agent или Windows Task Scheduler, что гарантирует выполнение резервного копирования в заданное время без участия пользователя.
Пример скрипта для создания резервной копии базы данных:
BACKUP DATABASE имя_базы
TO DISK = 'путь_к_файлу_резервной_копии.bak'
WITH INIT;
Для восстановления данных можно использовать команду RESTORE DATABASE, которая позволяет не только восстановить полную копию, но и выполнить восстановление после частичных сбоев, используя точки восстановления. Для этого важно знать параметры восстановления, такие как WITH NORECOVERY для восстановления в нескольких этапах.
Пример скрипта для восстановления базы данных:
RESTORE DATABASE имя_базы
FROM DISK = 'путь_к_файлу_резервной_копии.bak'
WITH REPLACE;
Для более сложных сценариев, например, с использованием инкрементальных резервных копий, важно правильно настроить автоматическое создание и управление резервными копиями, используя расширенные параметры, такие как BACKUP LOG для бэкапов журналов транзакций. Это позволяет свести к минимуму возможные потери данных и ускорить восстановление до последних состояний системы.
Для дополнительной безопасности можно настроить уведомления о состоянии выполнения задач резервного копирования и восстановления с помощью SQL Server Agent. Это даст возможность оперативно реагировать на возможные сбои в процессе выполнения задач, что повышает надежность системы.
Автоматизация резервного копирования с помощью SQL минимизирует человеческий фактор, гарантируя регулярность и точность выполнения операций. Это особенно важно в условиях высоких требований к доступности данных и минимизации времени простоя системы.
SQL и интеграция с другими системами и приложениями
SQL предоставляет мощные инструменты для интеграции с различными внешними системами и приложениями. Один из главных аспектов – возможность работы с различными источниками данных через стандартные интерфейсы, такие как ODBC (Open Database Connectivity) и JDBC (Java Database Connectivity). Эти технологии обеспечивают универсальность и позволяют подключать SQL-базы данных к различным приложениям, независимо от их платформы.
Одним из ключевых преимуществ SQL является поддержка веб-сервисов и RESTful API, которые позволяют интегрировать базы данных с другими приложениями через интернет. Используя SQL-запросы в рамках этих сервисов, можно получать и обновлять данные в реальном времени, что особенно важно для систем с высокими требованиями к скорости и актуальности информации.
Кроме того, SQL может взаимодействовать с большими данными и аналитическими системами, такими как Apache Hadoop или Spark. Интеграция с такими платформами позволяет выполнять сложные аналитические запросы и обрабатывать огромные объемы данных, используя привычный язык SQL. Это важно для организаций, которые хотят объединить реляционные данные с неструктурированными данными для более глубокой аналитики.
Для удобства интеграции SQL с другими системами можно использовать технологии ETL (Extract, Transform, Load). Через ETL-процессы можно выгружать данные из различных источников, преобразовывать их в нужный формат и загружать в SQL-базы данных для дальнейшего анализа. Это особенно полезно для предприятий, работающих с данными из множества различных систем, например, CRM, ERP или бухгалтерских программ.
Также стоит отметить поддержку SQL в облачных платформах. Многие облачные сервисы предлагают свои версии SQL-баз данных, что упрощает их интеграцию с облачными приложениями и сервисами. Это открывает возможности для гибкой работы с базами данных в масштабируемых и высокодоступных облачных средах.
Для интеграции с корпоративными системами часто используются SQL-серверы, которые поддерживают функции репликации и синхронизации данных. Такие возможности позволяют поддерживать актуальность данных на разных серверах и устройствах, что критически важно для больших организаций с распределенной сетью.
Масштабируемость и гибкость баз данных при использовании SQL

Гибкость SQL заключается в способности адаптировать схему базы данных в соответствии с меняющимися требованиями бизнеса. Благодаря поддержке различных типов данных, включая текст, числа, даты и даже более сложные структуры, SQL дает возможность эффективно работать с разнообразными данными. Система позволяет легко добавлять новые поля, таблицы и индексы, не нарушая целостности данных.
Использование SQL для реализации резервного копирования и восстановления базы данных позволяет повысить отказоустойчивость системы. SQL-серверы поддерживают регулярное создание снимков и архивов данных, что облегчает восстановление после сбоев. Также для масштабируемости полезно использовать кластеризацию, что позволяет объединить несколько серверов в одну систему, обеспечивая балансировку нагрузки и минимизацию времени отклика.
При использовании SQL также можно настроить индексацию для ускорения выполнения запросов, что особенно актуально при работе с большими объемами данных. Индексы помогают SQL-системам эффективно искать записи, улучшая производительность запросов при росте данных и их сложности.
Наконец, SQL поддерживает создание хранимых процедур и триггеров, которые могут автоматизировать обработку данных, снижая нагрузку на сервер и упрощая управление базой. Это добавляет дополнительную гибкость в операциях с данными и позволяет легко масштабировать бизнес-логику на уровне базы данных.
Вопрос-ответ:
Какие преимущества дает использование SQL для работы с базами данных?
SQL (Structured Query Language) обладает рядом явных преимуществ при работе с базами данных. Во-первых, этот язык позволяет удобно и быстро извлекать данные из базы, а также обновлять их. Он стандартизирован, что делает его совместимым с различными СУБД (системами управления базами данных), такими как MySQL, PostgreSQL, Oracle и другие. Благодаря этому можно использовать один и тот же язык для работы с разными типами баз данных. Кроме того, SQL предоставляет мощные возможности для обработки больших объемов данных, позволяет эффективно искать и фильтровать информацию, а также осуществлять сложные вычисления.
Почему SQL является предпочтительным выбором для работы с данными в больших проектах?
SQL особенно подходит для больших проектов по нескольким причинам. Во-первых, он обеспечивает высокую производительность при работе с большими объемами данных. SQL позволяет эффективно управлять огромными таблицами, создавая индексы для ускорения поиска. Во-вторых, благодаря возможности создавать сложные запросы, можно решать задачи, которые требуют обработки данных из разных источников и их агрегации. Также важным аспектом является зрелость и развитая экосистема SQL: поддержка множества инструментов и документации облегчает работу разработчиков, а наличие широкого сообщества помогает решать возникающие вопросы.
В чем отличие SQL от других языков запросов, таких как NoSQL или GraphQL?
SQL отличается от других языков запросов, таких как NoSQL или GraphQL, в первую очередь своей структурой и подходом к организации данных. В SQL данные хранятся в таблицах, и запросы выполняются по заранее определенным схемам, что делает его особенно подходящим для работы с реляционными базами данных. В отличие от этого, NoSQL предназначен для работы с нереляционными данными, такими как JSON или документы, и используется для приложений, где важна гибкость в структуре данных. GraphQL, в свою очередь, позволяет клиентам точно указывать, какие данные им нужны, и получает их за один запрос, что повышает эффективность работы с API. SQL больше подходит для строгих, структурированных данных, в то время как NoSQL и GraphQL могут быть более гибкими в случаях, когда структура данных меняется.
Какие возможности SQL предоставляет для обеспечения безопасности данных?
SQL предоставляет несколько инструментов для обеспечения безопасности данных. Одним из основных механизмов является контроль доступа, когда пользователи получают определенные права на чтение, запись или изменение данных в базе. Это позволяет ограничить доступ к важной информации и предотвратить несанкционированные изменения. Также можно использовать шифрование данных, чтобы защитить их от несанкционированного просмотра. В SQL также поддерживаются транзакции, которые обеспечивают целостность данных, например, с помощью принципа «ACID» (атомарность, согласованность, изолированность и долговечность). Это помогает гарантировать, что изменения в базе данных будут выполнены корректно и не приведут к потере или повреждению информации.