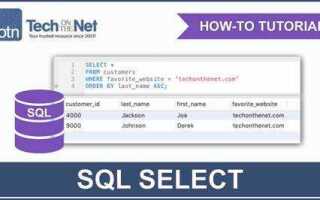
Оператор SELECT – основная команда в SQL, предназначенная для извлечения данных из базы данных. Его возможности далеко выходят за рамки простого извлечения записей, предлагая множество вариантов фильтрации, сортировки и агрегации данных. Понимание правильного использования SELECT – это ключевая часть освоения SQL и эффективной работы с базами данных.
Основной синтаксис команды выглядит следующим образом: SELECT * FROM таблица. Однако, в реальной практике чаще всего используется более сложный подход с указанием конкретных столбцов, условий фильтрации с помощью WHERE, сортировки через ORDER BY и других опций. Знание этих возможностей помогает не только ускорить выполнение запросов, но и сделать их более гибкими, удобными и читаемыми.
В этой статье рассмотрим, как правильно использовать SELECT для получения данных, какие параметры могут быть полезны для фильтрации, и как комбинировать различные операторы для решения сложных задач. Речь пойдет о таких ключевых концепциях, как объединение данных, использование подзапросов, а также оптимизация запросов для работы с большими объемами информации.
Основные функции оператора SELECT в SQL
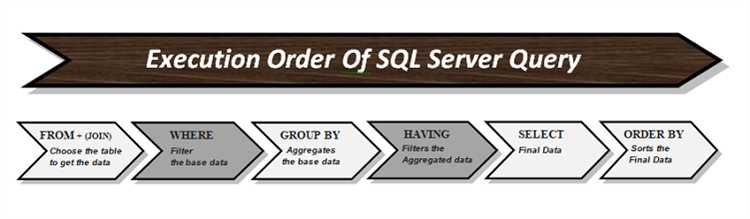
Оператор SELECT в SQL предоставляет мощные инструменты для извлечения данных из баз данных. Он позволяет не только выбирать данные, но и выполнять их фильтрацию, сортировку и агрегацию. Рассмотрим основные функции оператора SELECT, которые чаще всего используются на практике.
1. Выборка данных
Основная функция оператора SELECT – извлечение данных из одной или нескольких таблиц. Запрос может включать в себя конкретные столбцы или все данные, если используется символ *. Например:
SELECT name, age FROM users;Данный запрос выберет данные только из столбцов name и age таблицы users.
2. Условная фильтрация данных
С помощью оператора WHERE можно фильтровать строки на основе заданных условий. Условие может включать различные операторы, такие как =, !=, >, <, а также логические операторы AND, OR, NOT. Например:
SELECT * FROM employees WHERE salary > 50000 AND department = 'HR';Этот запрос вернет все строки из таблицы employees, где зарплата больше 50 000 и отдел равен "HR".
3. Сортировка данных
Функция ORDER BY позволяет сортировать результаты по одному или нескольким столбцам. По умолчанию сортировка происходит в порядке возрастания, но можно использовать ключевое слово DESC для сортировки по убыванию. Например:
SELECT name, salary FROM employees ORDER BY salary DESC;Этот запрос отсортирует данные по зарплате сотрудников в порядке убывания.
4. Группировка данных
Когда необходимо агрегировать данные, используется ключевое слово GROUP BY. Оно группирует строки по указанным столбцам и позволяет применять агрегатные функции, такие как COUNT, SUM, AVG, MAX, MIN. Например:
SELECT department, AVG(salary) FROM employees GROUP BY department;Этот запрос вычислит среднюю зарплату для каждого отдела в таблице employees.
5. Ограничение количества строк
Для ограничения количества возвращаемых строк используется ключевое слово LIMIT (в некоторых СУБД – TOP). Это полезно, когда нужно получить только часть данных. Например:
SELECT * FROM employees LIMIT 10;Этот запрос вернет первые 10 строк из таблицы employees.
6. Объединение таблиц
Оператор SELECT позволяет объединять данные из нескольких таблиц с помощью оператора JOIN. Он поддерживает различные типы объединений: INNER JOIN, LEFT JOIN, RIGHT JOIN, FULL JOIN, каждый из которых определяет, какие строки будут включены в результат в зависимости от наличия соответствий в обеих таблицах. Например:
SELECT employees.name, departments.department_name
FROM employees
INNER JOIN departments ON employees.department_id = departments.id;Этот запрос объединяет таблицы employees и departments по полю department_id и возвращает имена сотрудников и названия их отделов.
7. Использование подзапросов
Подзапросы позволяют встраивать один запрос SELECT внутри другого. Это может быть полезно для получения более сложных данных или выполнения промежуточных операций. Например:
SELECT name
FROM employees
WHERE department_id = (SELECT id FROM departments WHERE department_name = 'Sales');Этот запрос вернет имена сотрудников, работающих в отделе "Sales", с использованием подзапроса для получения идентификатора отдела.
8. Агрегатные функции
Агрегатные функции, такие как COUNT, SUM, AVG, MAX и MIN, применяются для выполнения операций над множеством строк. Например, COUNT может подсчитать количество строк, а SUM – сумму значений в столбце:
SELECT COUNT(*) FROM employees WHERE salary > 50000;Этот запрос возвращает количество сотрудников с зарплатой выше 50 000.
Каждая из этих функций предоставляет уникальные возможности для работы с данными, делая запросы более мощными и гибкими.
Как выбрать конкретные столбцы с помощью SELECT
Для выбора конкретных столбцов в SQL используется конструкция SELECT с указанием имен столбцов через запятую. Вместо выборки всех данных из таблицы с использованием звездочки (*) можно указать только те столбцы, которые необходимы. Это позволяет улучшить производительность запросов и уменьшить объем данных, которые передаются и обрабатываются.
Пример базового запроса:
SELECT column1, column2 FROM table_name;
Здесь column1 и column2 – это имена столбцов, которые вы хотите выбрать из таблицы table_name. Важно точно указывать имена столбцов, как они прописаны в базе данных. Если название столбца состоит из нескольких слов, оно должно быть взято в кавычки (например, "full name").
Если необходимо выбрать столбцы с определенным условием, это можно сделать с помощью оператора WHERE:
SELECT column1, column2 FROM table_name WHERE condition;
SELECT column1 AS alias1, column2 AS alias2 FROM table_name;
При необходимости выборки столбцов с арифметическими или агрегатными операциями, например, для вычисления среднего значения или суммы, можно использовать функции SQL:
SELECT AVG(column1), SUM(column2) FROM table_name;
Важно помнить, что в SELECT можно включать и вычисляемые выражения. Например, можно создать новый столбец, который будет результатом операции между уже существующими столбцами:
SELECT column1 + column2 AS total FROM table_name;
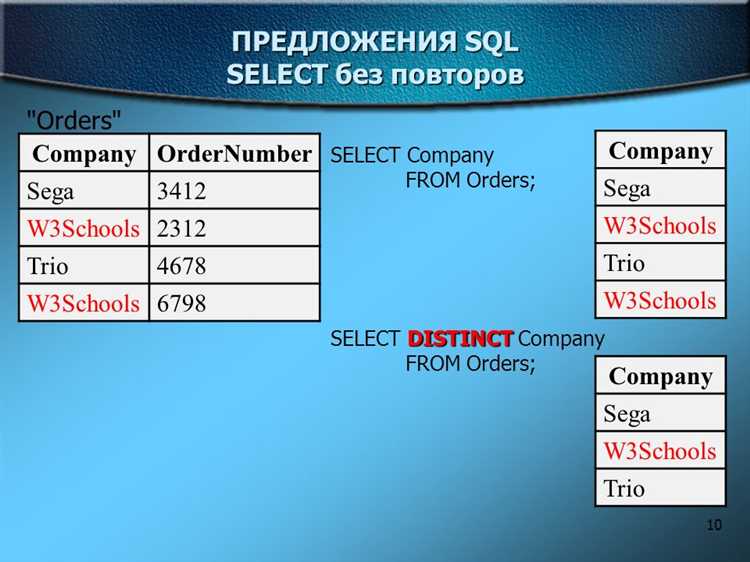
Если требуется выборка данных с удалением повторяющихся значений, применяется ключевое слово DISTINCT:
SELECT DISTINCT column1 FROM table_name;
Таким образом, используя SELECT, можно гибко контролировать, какие данные будут извлечены из базы, минимизируя ненужную нагрузку на систему.
Использование оператора SELECT для фильтрации данных

Для отбора нужных записей используется предложение WHERE, добавляемое к оператору SELECT. Оно позволяет задать условие фильтрации. Например, чтобы получить всех сотрудников с зарплатой выше 50000, используется запрос:
SELECT * FROM employees WHERE salary > 50000;
Поддерживаются логические операторы: AND, OR, NOT. Они комбинируют условия. Пример: выбор сотрудников из отдела 3 с зарплатой более 40000:
SELECT name FROM employees WHERE department_id = 3 AND salary > 40000;
Для фильтрации по диапазону значений применяется BETWEEN:
SELECT name FROM employees WHERE hire_date BETWEEN '2022-01-01' AND '2023-01-01';
Чтобы исключить записи, используется NOT или NOT IN:
SELECT name FROM employees WHERE department_id NOT IN (2, 4);
Для поиска по части строки – LIKE с символами подстановки. Пример: поиск всех сотрудников, чьё имя начинается на «А»:
SELECT name FROM employees WHERE name LIKE 'А%';
Проверка на пустые значения – с помощью IS NULL или IS NOT NULL. Например, выбор сотрудников без указания e-mail:
SELECT name FROM employees WHERE email IS NULL;
Фильтрация всегда идет после FROM и до ORDER BY или GROUP BY, если они используются. Условия чувствительны к типу данных, поэтому важно не заключать числовые значения в кавычки и корректно указывать формат дат.
Как сортировать результаты с помощью SELECT и ORDER BY
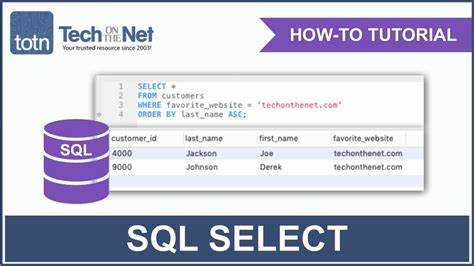
Ключевое слово ORDER BY используется для упорядочивания строк в результате запроса. По умолчанию сортировка выполняется по возрастанию (ASC), но можно указать DESC для обратного порядка.
Пример: SELECT имя, зарплата FROM сотрудники ORDER BY зарплата DESC; – этот запрос вернёт список сотрудников, отсортированный по убыванию зарплаты.
Если требуется сортировать по нескольким столбцам, они перечисляются через запятую. Сначала применяется порядок для первого столбца, затем для второго и так далее. Например: SELECT имя, отдел, зарплата FROM сотрудники ORDER BY отдел ASC, зарплата DESC;.
Сортировку можно выполнять не только по именам столбцов, но и по их порядковым номерам в списке SELECT. SELECT имя, дата_приёма FROM сотрудники ORDER BY 2 DESC; отсортирует по дате приёма, так как она вторая в списке.
С выражениями тоже работает: SELECT имя, (оклад + надбавка) AS доход FROM сотрудники ORDER BY доход DESC;. Здесь сортировка идёт по вычисленному значению.
В PostgreSQL и других СУБД допустимы NULLS FIRST и NULLS LAST, чтобы управлять положением пустых значений: ORDER BY дата_увольнения DESC NULLS LAST.
Если используется DISTINCT или GROUP BY, сортировка всё равно допустима. Например: SELECT DISTINCT отдел FROM сотрудники ORDER BY отдел.
В подзапросах или представлениях ORDER BY чаще игнорируется, если не указан LIMIT. Поэтому для надёжного управления порядком сортировки он должен быть в основном запросе.
Объединение таблиц с помощью JOIN в операторе SELECT
JOIN позволяет извлекать данные из нескольких таблиц, связанных между собой по определённому условию. Основной тип – INNER JOIN, возвращающий только те строки, где условие соединения выполняется в обеих таблицах.
Синтаксис:
SELECT ... FROM таблица1 INNER JOIN таблица2 ON таблица1.поле = таблица2.поле
LEFT JOIN возвращает все строки из первой таблицы и совпадающие из второй. Если совпадений нет, значения из второй таблицы будут NULL.
RIGHT JOIN работает аналогично, но приоритет отдаётся второй таблице.
FULL JOIN (если поддерживается СУБД) объединяет результат LEFT и RIGHT JOIN, включая строки без совпадений в обеих таблицах.
Рекомендуется явно указывать используемые поля, особенно при соединении таблиц с пересекающимися именами колонок, чтобы избежать двусмысленности.
Если требуется фильтрация после соединения, используйте WHERE после JOIN. Для фильтрации только по соединению – указывайте условие в ON.
Для соединения более двух таблиц используйте цепочку JOIN с последовательными ON-условиями. Вложенные соединения допустимы, но ухудшают читаемость. Пример:
SELECT ... FROM А JOIN B ON ... JOIN C ON ...
Используйте алиасы для сокращения записей: SELECT A.имя, B.значение FROM таблица1 A JOIN таблица2 B ON A.id = B.id.
При работе с внешними соединениями учитывайте возможность появления NULL в связанных колонках. Это влияет на сортировку, агрегацию и фильтрацию.
Группировка данных с помощью GROUP BY в SELECT
GROUP BY используется для агрегации строк по определённому признаку. Он группирует записи, имеющие одинаковые значения в указанных столбцах, и позволяет применять агрегатные функции к каждой группе.
Пример: необходимо подсчитать общее количество заказов для каждого клиента. Запрос будет выглядеть так:
SELECT customer_id, COUNT(*) FROM orders GROUP BY customer_id;
Важно: все столбцы в SELECT, кроме тех, к которым применяются агрегатные функции, должны быть перечислены в GROUP BY. Иначе запрос вызовет ошибку.
Агрегатные функции, совместимые с GROUP BY: COUNT(), SUM(), AVG(), MIN(), MAX(). Они применяются к каждой группе отдельно.
Дополнительно можно использовать HAVING для фильтрации уже сгруппированных данных. Пример: показать только тех клиентов, у которых больше трёх заказов:
SELECT customer_id, COUNT(*) FROM orders GROUP BY customer_id HAVING COUNT(*) > 3;
Сортировка результатов возможна с помощью ORDER BY. Она работает после группировки. Пример:
SELECT product_id, SUM(quantity) FROM sales GROUP BY product_id ORDER BY SUM(quantity) DESC;
GROUP BY можно использовать с несколькими столбцами. В этом случае группировка происходит по уникальным комбинациям значений. Пример:
SELECT region, product_id, SUM(amount) FROM revenue GROUP BY region, product_id;
Применение агрегатных функций в запросах SELECT
Агрегатные функции в SQL позволяют выполнять вычисления над наборами строк. Они часто используются с оператором GROUP BY для группировки данных по определённому признаку. Ниже перечислены основные функции с примерами их применения.
- COUNT() – подсчитывает количество строк. Пример:
SELECT COUNT(*) FROM продаживозвращает общее число записей в таблице. - SUM() – вычисляет сумму значений. Пример:
SELECT SUM(сумма) FROM продажипокажет общую выручку. - AVG() – определяет среднее значение. Пример:
SELECT AVG(сумма) FROM продажидаст средний чек. - MAX() – находит максимальное значение. Пример:
SELECT MAX(сумма) FROM продажипокажет самый крупный заказ. - MIN() – находит минимальное значение. Пример:
SELECT MIN(сумма) FROM продажидаст самый маленький заказ.
Для анализа по категориям применяют GROUP BY:
SELECT категория, SUM(сумма)
FROM продажи
GROUP BY категорияЕсли нужно исключить группы по условию, используют HAVING:
SELECT категория, SUM(сумма)
FROM продажи
GROUP BY категория
HAVING SUM(сумма) > 10000Агрегатные функции игнорируют значения NULL, за исключением COUNT(*), которая учитывает все строки. Для подсчёта только ненулевых значений используют COUNT(поле).
Как ограничить количество возвращаемых строк в запросе SELECT
Для получения ограниченного числа строк используется конструкция LIMIT. Она применяется в конце запроса и принимает целое число, указывающее, сколько строк вернуть.
SELECT имя, возраст FROM сотрудники LIMIT 5;В этом примере будут выбраны только первые 5 строк результата. Если необходимо пропустить часть строк, используется OFFSET:
SELECT имя, возраст FROM сотрудники LIMIT 5 OFFSET 10;Это вернёт 5 строк, начиная с одиннадцатой.
LIMITэффективен при работе с пагинацией.OFFSETувеличивает нагрузку при больших смещениях – чем выше значение, тем дольше выполняется запрос.- Для более производительного выбора рекомендуются подзапросы с фильтрацией по индексируемым колонкам вместо OFFSET при больших объёмах данных.
В SQL Server вместо LIMIT используется TOP:
SELECT TOP 10 имя, возраст FROM сотрудники;В PostgreSQL, MySQL и SQLite поддерживается LIMIT и OFFSET. В Oracle используется FETCH FIRST:
SELECT имя, возраст FROM сотрудники FETCH FIRST 10 ROWS ONLY;Порядок строк определяется только при наличии ORDER BY. Без него результаты могут быть непредсказуемыми:
SELECT имя FROM сотрудники ORDER BY дата_приёма LIMIT 3;Для точного контроля используйте сортировку, особенно при разбиении на страницы или аналитике.